 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISITRON: Visual Semantics-Aligned Interactively Trained Object-Navigator
May 25, 2021



Interactive robots navigating photo-realistic environments face challenges underlying vision-and-language navigation (VLN), but in addition, they need to be trained to handle the dynamic nature of dialogue. However, research in Cooperative Vision-and-Dialog Navigation (CVDN), where a navigator interacts with a guide in natural language in order to reach a goal, treats the dialogue history as a VLN-style static instruction. In this paper, we present VISITRON, a navigator better suited to the interactive regime inherent to CVDN by being trained to: i) identify and associate object-level concepts and semantics between the environment and dialogue history, ii) identify when to interact vs. navigate via imitation learning of a binary classification head. We perform extensive ablations with VISITRON to gain empirical insights and improve performance on CVDN. VISITRON is competitive with models on the static CVDN leaderboard. We also propose a generalized interactive regime to fine-tune and evaluate VISITRON and future such models with pre-trained guides for adaptability.
Building a Conversational Agent Overnight with Dialogue Self-Play
Jan 15, 2018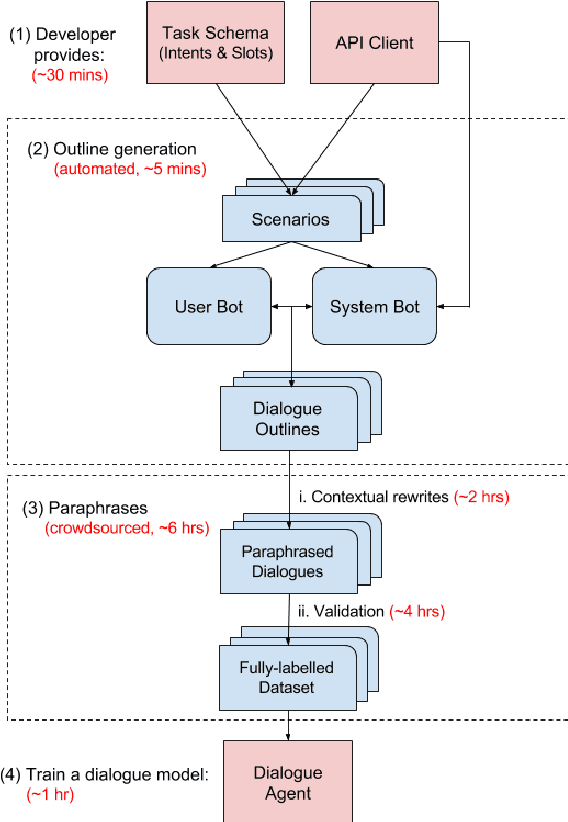

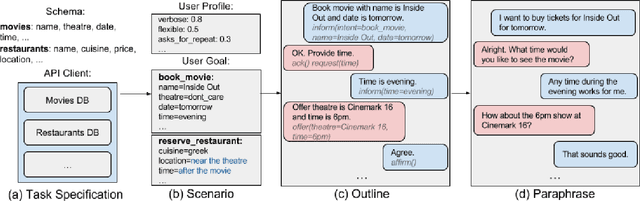
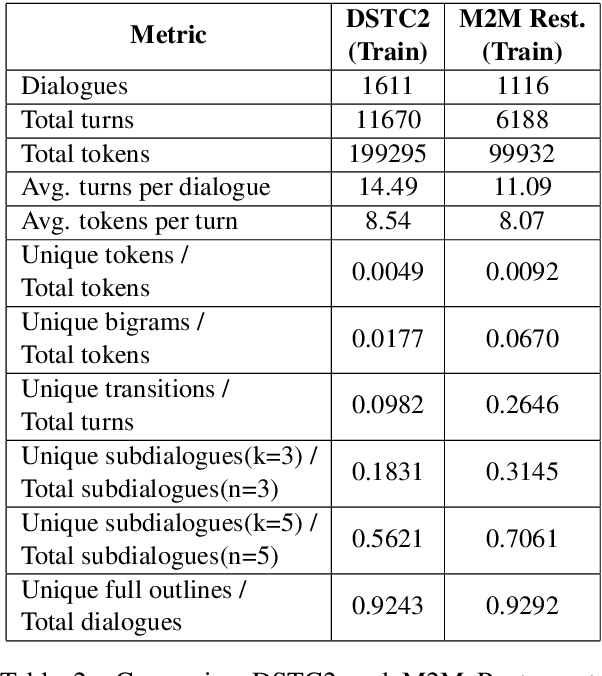
We propose Machines Talking To Machines (M2M), a framework combining automation and crowdsourcing to rapidly bootstrap end-to-end dialogue agents for goal-oriented dialogues in arbitrary domains. M2M scales to new tasks with just a task schema and an API client from the dialogue system developer, but it is also customizable to cater to task-specific interactions. Compared to the Wizard-of-Oz approach for data collection, M2M achieves greater diversity and coverage of salient dialogue flows while maintaining the naturalness of individual utterances. In the first phase, a simulated user bot and a domain-agnostic system bot converse to exhaustively generate dialogue "outlines", i.e. sequences of template utterances and their semantic parses. In the second phase, crowd workers provide contextual rewrites of the dialogues to make the utterances more natural while preserving their meaning. The entire process can finish within a few hours. We propose a new corpus of 3,000 dialogues spanning 2 domains collected with M2M, and present comparisons with popular dialogue datasets on the quality and diversity of the surface forms and dialogue flows.