 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
STAB: Speech Tokenizer Assessment Benchmark
Sep 04, 2024
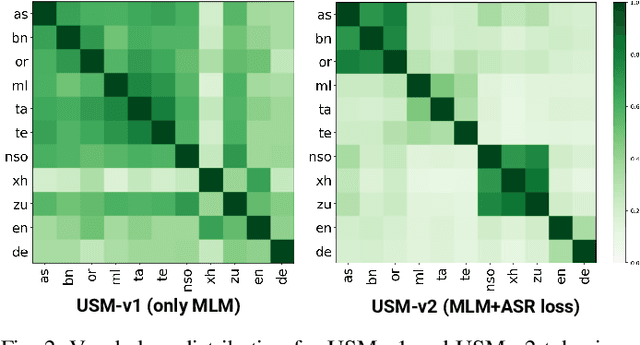
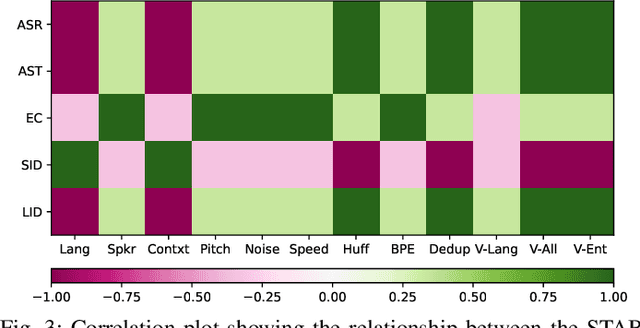
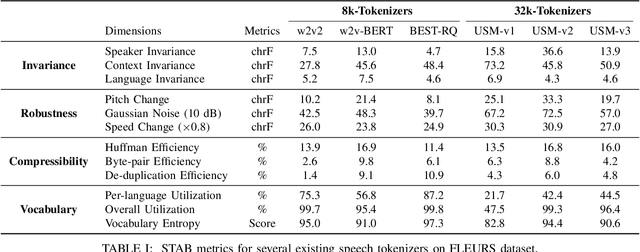
Representing speech as discrete tokens provides a framework for transforming speech into a format that closely resembles text, thus enabling the use of speech as an input to the widely successful large language models (LLMs). Currently, while several speech tokenizers have been proposed, there is ambiguity regarding the properties that are desired from a tokenizer for specific downstream tasks and its overall generalizability. Evaluating the performance of tokenizers across different downstream tasks is a computationally intensive effort that poses challenges for scalability. To circumvent this requirement, we present STAB (Speech Tokenizer Assessment Benchmark), a systematic evaluation framework designed to assess speech tokenizers comprehensively and shed light on their inherent characteristics. This framework provides a deeper understanding of the underlying mechanisms of speech tokenization, thereby offering a valuable resource for expediting the advancement of future tokenizer models and enabling comparative analysis using a standardized benchmark. We evaluate the STAB metrics and correlate this with downstream task performance across a range of speech tasks and tokenizer choices.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Multimodal Modeling For Spoken Language Identification
Sep 19, 2023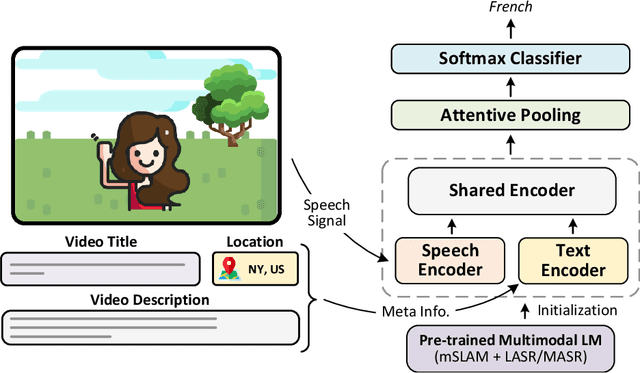
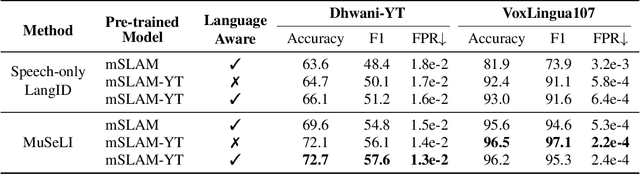
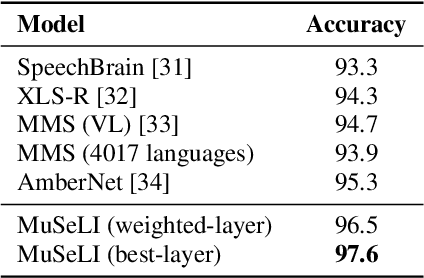
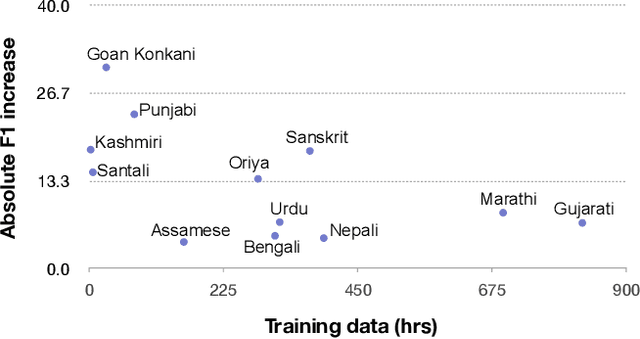
Spoken language identification refers to the task of automatically predicting the spoken language in a given utterance. Conventionally, it is modeled as a speech-based language identification task. Prior techniques have been constrained to a single modality; however in the case of video data there is a wealth of other metadata that may be beneficial for this task. In this work, we propose MuSeLI, a Multimodal Spoken Language Identification method, which delves into the use of various metadata sources to enhance language identification. Our study reveals that metadata such as video title, description and geographic location provide substantial information to identify the spoken language of the multimedia recording. We conduct experiments using two diverse public datasets of YouTube videos, and obtain state-of-the-art results on the language identification task. We additionally conduct an ablation study that describes the distinct contribution of each modality for language recognition.
MADLAD-400: A Multilingual And Document-Level Large Audited Dataset
Sep 09, 2023We introduce MADLAD-400, a manually audited, general domain 3T token monolingual dataset based on CommonCrawl, spanning 419 languages. We discuss the limitations revealed by self-auditing MADLAD-400, and the role data auditing had in the dataset creation process. We then train and release a 10.7B-parameter multilingual machine translation model on 250 billion tokens covering over 450 languages using publicly available data, and find that it is competitive with models that are significantly larger, and report the results on different domains. In addition, we train a 8B-parameter language model, and assess the results on few-shot translation. We make the baseline models available to the research community.
AudioPaLM: A Large Language Model That Can Speak and Listen
Jun 22, 2023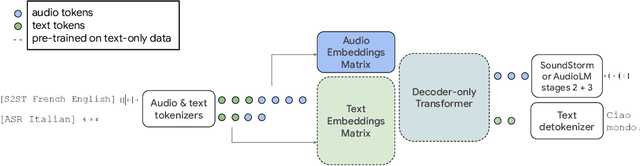



We introduce AudioPaLM, a large language model for speech understanding and generation. AudioPaLM fuses text-based and speech-based language models, PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified multimodal architecture that can process and generate text and speech with applications including speech recognition and speech-to-speech translation. AudioPaLM inherits the capability to preserve paralinguistic information such as speaker identity and intonation from AudioLM and the linguistic knowledge present only in text large language models such as PaLM-2. We demonstrate that initializing AudioPaLM with the weights of a text-only large language model improves speech processing, successfully leveraging the larger quantity of text training data used in pretraining to assist with the speech tasks. The resulting model significantly outperforms existing systems for speech translation tasks and has the ability to perform zero-shot speech-to-text translation for many languages for which input/target language combinations were not seen in training. AudioPaLM also demonstrates features of audio language models, such as transferring a voice across languages based on a short spoken prompt. We release examples of our method at https://google-research.github.io/seanet/audiopalm/examples
Label Aware Speech Representation Learning For Language Identification
Jun 07, 2023

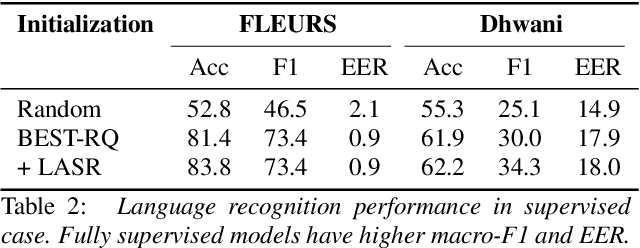

Speech representation learning approaches for non-semantic tasks such as language recognition have either explored supervised embedding extraction methods using a classifier model or self-supervised representation learning approaches using raw data. In this paper, we propose a novel framework of combining self-supervised representation learning with the language label information for the pre-training task. This framework, termed as Label Aware Speech Representation (LASR) learning, uses a triplet based objective function to incorporate language labels along with the self-supervised loss function. The speech representations are further fine-tuned for the downstream task. The language recognition experiments are performed on two public datasets - FLEURS and Dhwani. In these experiments, we illustrate that the proposed LASR framework improves over the state-of-the-art systems on language identification. We also report an analysis of the robustness of LASR approach to noisy/missing labels as well as its application to multi-lingual speech recognition tasks.
LibriTTS-R: A Restored Multi-Speaker Text-to-Speech Corpus
May 30, 2023
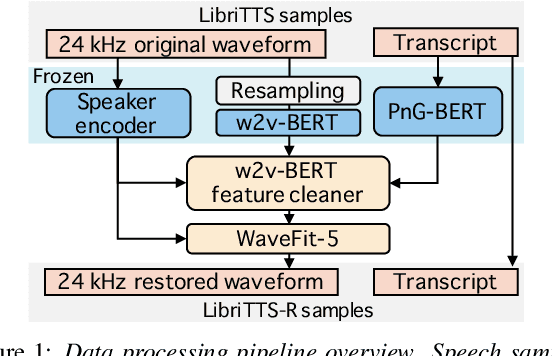
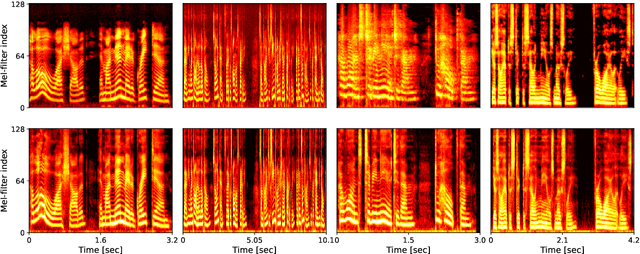

This paper introduces a new speech dataset called ``LibriTTS-R'' designed for text-to-speech (TTS) use. It is derived by applying speech restoration to the LibriTTS corpus, which consists of 585 hours of speech data at 24 kHz sampling rate from 2,456 speakers and the corresponding texts. The constituent samples of LibriTTS-R are identical to those of LibriTTS, with only the sound quality improved. Experimental results show that the LibriTTS-R ground-truth samples showed significantly improved sound quality compared to those in LibriTTS. In addition, neural end-to-end TTS trained with LibriTTS-R achieved speech naturalness on par with that of the ground-truth samples. The corpus is freely available for download from \url{http://www.openslr.org/141/}.
Understanding Shared Speech-Text Representations
Apr 27, 2023Recently, a number of approaches to train speech models by incorpo-rating text into end-to-end models have been developed, with Mae-stro advancing state-of-the-art automatic speech recognition (ASR)and Speech Translation (ST) performance. In this paper, we expandour understanding of the resulting shared speech-text representationswith two types of analyses. First we examine the limits of speech-free domain adaptation, finding that a corpus-specific duration modelfor speech-text alignment is the most important component for learn-ing a shared speech-text representation. Second, we inspect the sim-ilarities between activations of unimodal (speech or text) encodersas compared to the activations of a shared encoder. We find that theshared encoder learns a more compact and overlapping speech-textrepresentation than the uni-modal encoders. We hypothesize that thispartially explains the effectiveness of the Maestro shared speech-textrepresentations.