 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrder Matters in the Presence of Dataset Imbalance for Multilingual Learning
Dec 11, 2023In this paper, we empirically study the optimization dynamics of multi-task learning, particularly focusing on those that govern a collection of tasks with significant data imbalance. We present a simple yet effective method of pre-training on high-resource tasks, followed by fine-tuning on a mixture of high/low-resource tasks. We provide a thorough empirical study and analysis of this method's benefits showing that it achieves consistent improvements relative to the performance trade-off profile of standard static weighting. We analyze under what data regimes this method is applicable and show its improvements empirically in neural machine translation (NMT) and multi-lingual language modeling.
MADLAD-400: A Multilingual And Document-Level Large Audited Dataset
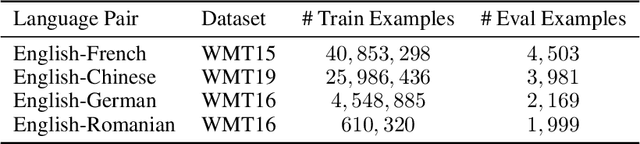
Sep 09, 2023We introduce MADLAD-400, a manually audited, general domain 3T token monolingual dataset based on CommonCrawl, spanning 419 languages. We discuss the limitations revealed by self-auditing MADLAD-400, and the role data auditing had in the dataset creation process. We then train and release a 10.7B-parameter multilingual machine translation model on 250 billion tokens covering over 450 languages using publicly available data, and find that it is competitive with models that are significantly larger, and report the results on different domains. In addition, we train a 8B-parameter language model, and assess the results on few-shot translation. We make the baseline models available to the research community.
Do Current Multi-Task Optimization Methods in Deep Learning Even Help?
Sep 23, 2022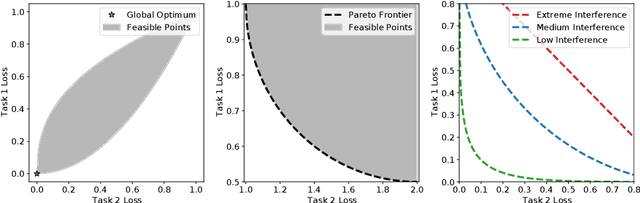
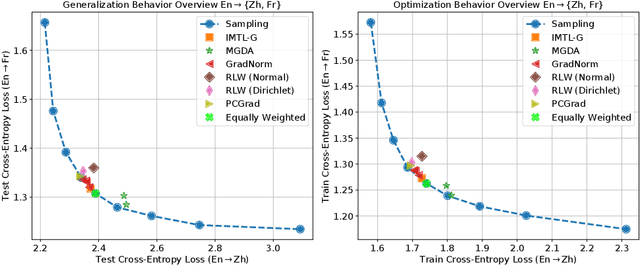
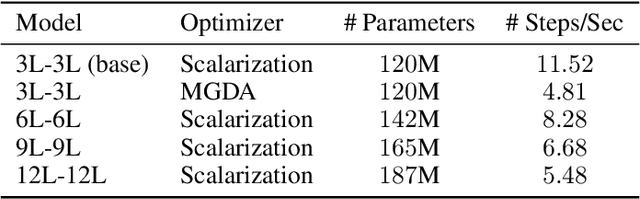
Recent research has proposed a series of specialized optimization algorithms for deep multi-task models. It is often claimed that these multi-task optimization (MTO) methods yield solutions that are superior to the ones found by simply optimizing a weighted average of the task losses. In this paper, we perform large-scale experiments on a variety of language and vision tasks to examine the empirical validity of these claims. We show that, despite the added design and computational complexity of these algorithms, MTO methods do not yield any performance improvements beyond what is achievable via traditional optimization approaches. We highlight alternative strategies that consistently yield improvements to the performance profile and point out common training pitfalls that might cause suboptimal results. Finally, we outline challenges in reliably evaluating the performance of MTO algorithms and discuss potential solutions.