 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from others' mistakes: Finetuning machine translation models with span-level error annotations
Oct 21, 2024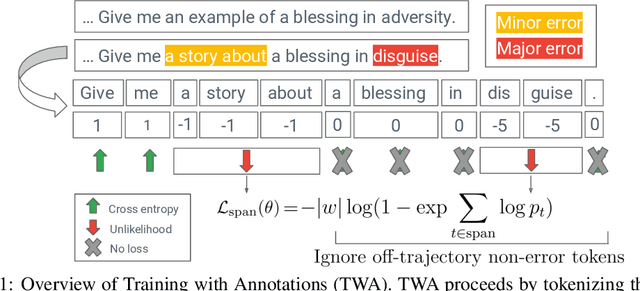


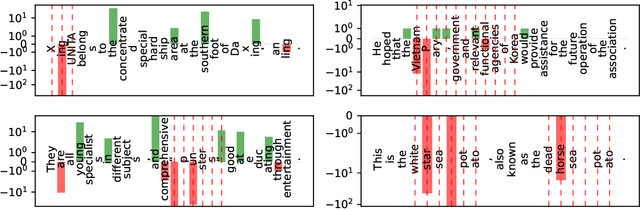
Despite growing interest in incorporating feedback to improve language models, most efforts focus only on sequence-level annotations. In this work, we explore the potential of utilizing fine-grained span-level annotations from offline datasets to improve model quality. We develop a simple finetuning algorithm, called Training with Annotations (TWA), to directly train machine translation models on such annotated data. TWA utilizes targeted span-level error information while also flexibly learning what to penalize within a span. Moreover, TWA considers the overall trajectory of a sequence when deciding which non-error spans to utilize as positive signals. Experiments on English-German and Chinese-English machine translation show that TWA outperforms baselines such as Supervised FineTuning on sequences filtered for quality and Direct Preference Optimization on pairs constructed from the same data.
Don't Throw Away Data: Better Sequence Knowledge Distillation
Jul 15, 2024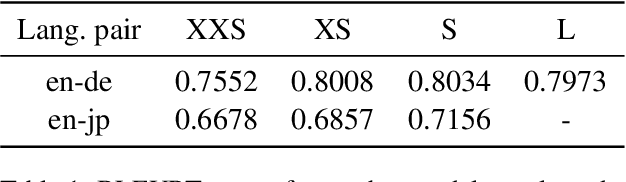
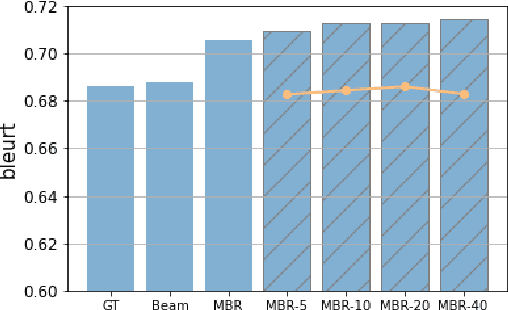
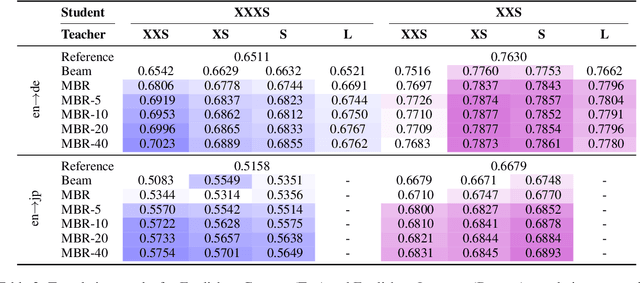
A critical component in knowledge distillation is the means of coupling the teacher and student. The predominant sequence knowledge distillation method involves supervised learning of the student against teacher-decoded outputs, and is exemplified by the current state of the art, which incorporates minimum Bayes risk (MBR) decoding. In this paper we seek to integrate MBR more tightly in distillation training, specifically by using several high scoring MBR translations, rather than a single selected sequence, thus capturing a rich diversity of teacher outputs. Our experiments on English to German and English to Japanese translation show consistent improvements over strong baseline methods for both tasks and with varying model sizes. Additionally, we conduct a detailed analysis focusing on data efficiency and capacity curse aspects to elucidate MBR-n and explore its further potential.
Order Matters in the Presence of Dataset Imbalance for Multilingual Learning
Dec 11, 2023In this paper, we empirically study the optimization dynamics of multi-task learning, particularly focusing on those that govern a collection of tasks with significant data imbalance. We present a simple yet effective method of pre-training on high-resource tasks, followed by fine-tuning on a mixture of high/low-resource tasks. We provide a thorough empirical study and analysis of this method's benefits showing that it achieves consistent improvements relative to the performance trade-off profile of standard static weighting. We analyze under what data regimes this method is applicable and show its improvements empirically in neural machine translation (NMT) and multi-lingual language modeling.
Fourier Representations for Black-Box Optimization over Categorical Variables
Feb 08, 2022
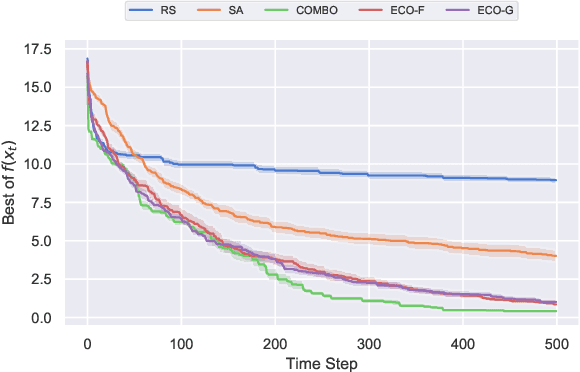
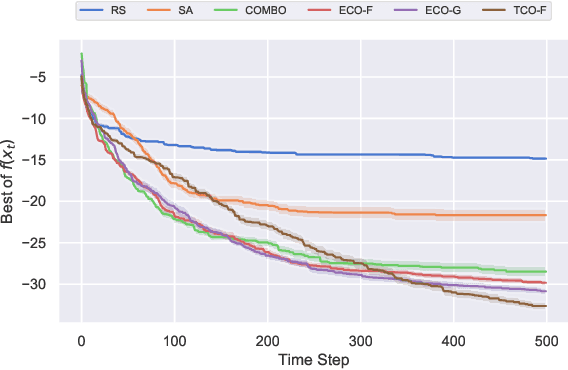
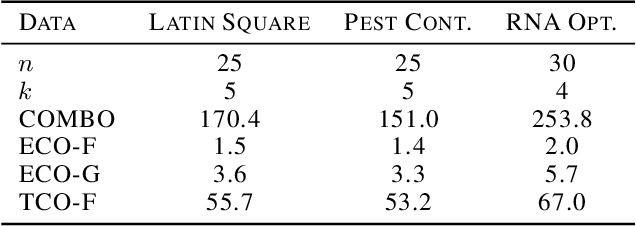
Optimization of real-world black-box functions defined over purely categorical variables is an active area of research. In particular, optimization and design of biological sequences with specific functional or structural properties have a profound impact in medicine, materials science, and biotechnology. Standalone search algorithms, such as simulated annealing (SA) and Monte Carlo tree search (MCTS), are typically used for such optimization problems. In order to improve the performance and sample efficiency of such algorithms, we propose to use existing methods in conjunction with a surrogate model for the black-box evaluations over purely categorical variables. To this end, we present two different representations, a group-theoretic Fourier expansion and an abridged one-hot encoded Boolean Fourier expansion. To learn such representations, we consider two different settings to update our surrogate model. First, we utilize an adversarial online regression setting where Fourier characters of each representation are considered as experts and their respective coefficients are updated via an exponential weight update rule each time the black box is evaluated. Second, we consider a Bayesian setting where queries are selected via Thompson sampling and the posterior is updated via a sparse Bayesian regression model (over our proposed representation) with a regularized horseshoe prior. Numerical experiments over synthetic benchmarks as well as real-world RNA sequence optimization and design problems demonstrate the representational power of the proposed methods, which achieve competitive or superior performance compared to state-of-the-art counterparts, while improving the computation cost and/or sample efficiency, substantially.
Combinatorial Black-Box Optimization with Expert Advice
Jun 06, 2020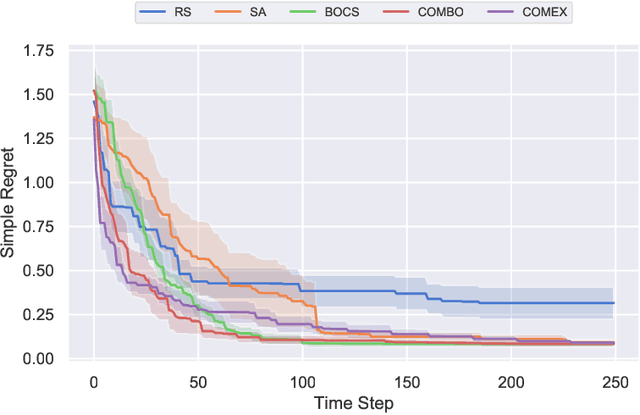
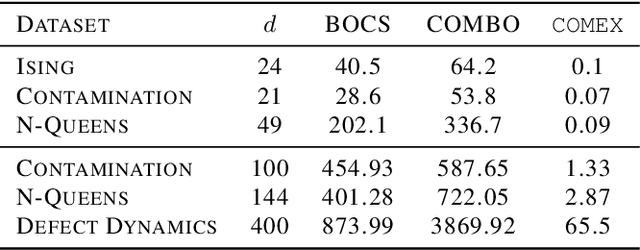
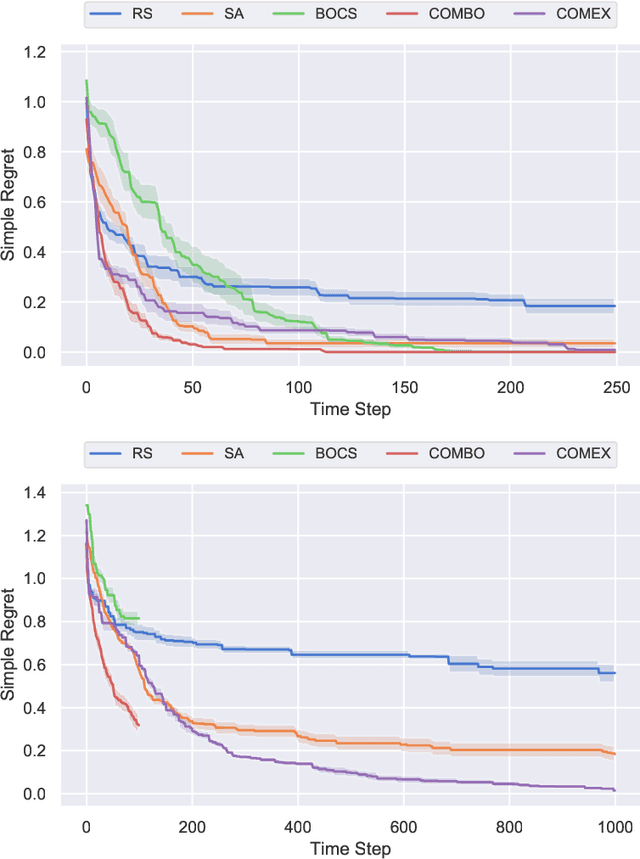
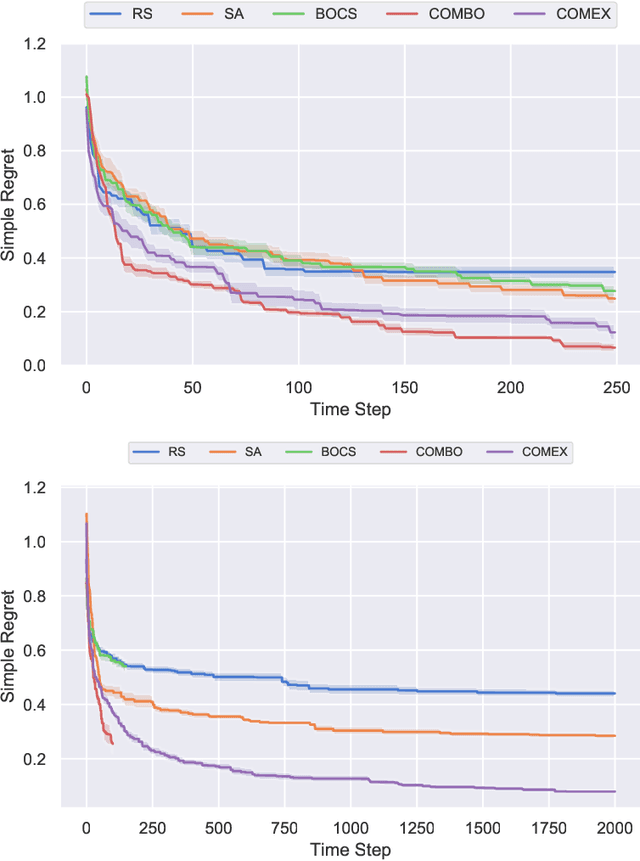
We consider the problem of black-box function optimization over the boolean hypercube. Despite the vast literature on black-box function optimization over continuous domains, not much attention has been paid to learning models for optimization over combinatorial domains until recently. However, the computational complexity of the recently devised algorithms are prohibitive even for moderate numbers of variables; drawing one sample using the existing algorithms is more expensive than a function evaluation for many black-box functions of interest. To address this problem, we propose a computationally efficient model learning algorithm based on multilinear polynomials and exponential weight updates. In the proposed algorithm, we alternate between simulated annealing with respect to the current polynomial representation and updating the weights using monomial experts' advice. Numerical experiments on various datasets in both unconstrained and sum-constrained boolean optimization indicate the competitive performance of the proposed algorithm, while improving the computational time up to several orders of magnitude compared to state-of-the-art algorithms in the literature.
Alternating Linear Bandits for Online Matrix-Factorization Recommendation
Oct 22, 2018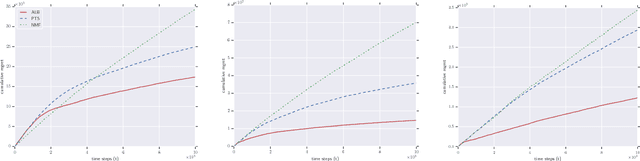
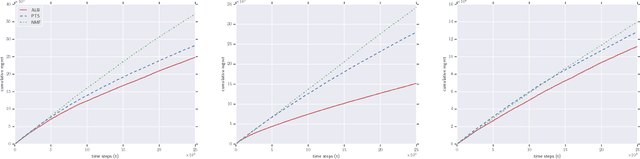
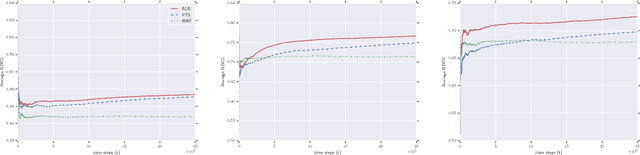
We consider the problem of online collaborative filtering in the online setting, where items are recommended to the users over time. At each time step, the user (selected by the environment) consumes an item (selected by the agent) and provides a rating of the selected item. In this paper, we propose a novel algorithm for online matrix factorization recommendation that combines linear bandits and alternating least squares. In this formulation, the bandit feedback is equal to the difference between the ratings of the best and selected items. We evaluate the performance of the proposed algorithm over time using both cumulative regret and average cumulative NDCG. Simulation results over three synthetic datasets as well as three real-world datasets for online collaborative filtering indicate the superior performance of the proposed algorithm over two state-of-the-art online algorithms.
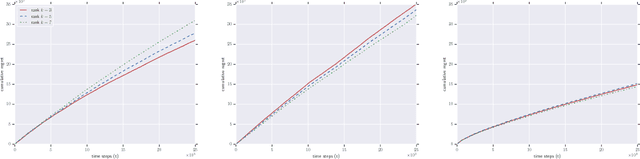
Out-of-Sample Extension for Dimensionality Reduction of Noisy Time Series
Jul 29, 2017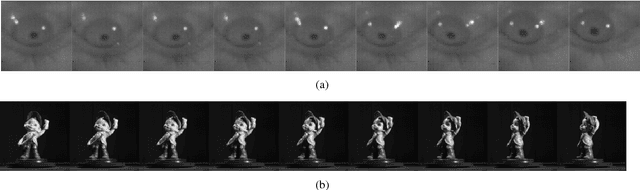

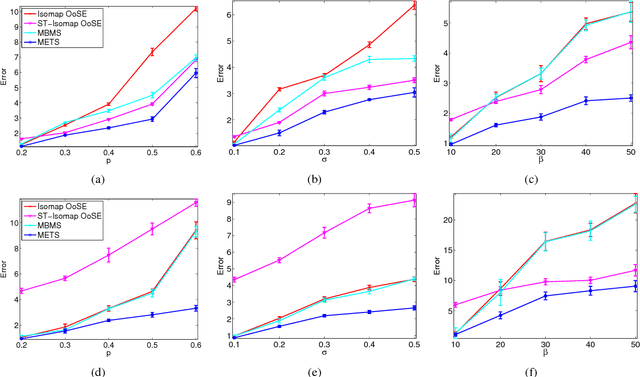
This paper proposes an out-of-sample extension framework for a global manifold learning algorithm (Isomap) that uses temporal information in out-of-sample points in order to make the embedding more robust to noise and artifacts. Given a set of noise-free training data and its embedding, the proposed framework extends the embedding for a noisy time series. This is achieved by adding a spatio-temporal compactness term to the optimization objective of the embedding. To the best of our knowledge, this is the first method for out-of-sample extension of manifold embeddings that leverages timing information available for the extension set. Experimental results demonstrate that our out-of-sample extension algorithm renders a more robust and accurate embedding of sequentially ordered image data in the presence of various noise and artifacts when compared to other timing-aware embeddings. Additionally, we show that an out-of-sample extension framework based on the proposed algorithm outperforms the state of the art in eye-gaze estimation.
Learning Tree-Structured Detection Cascades for Heterogeneous Networks of Embedded Devices
Jun 24, 2017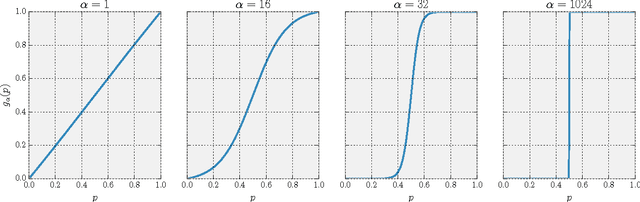
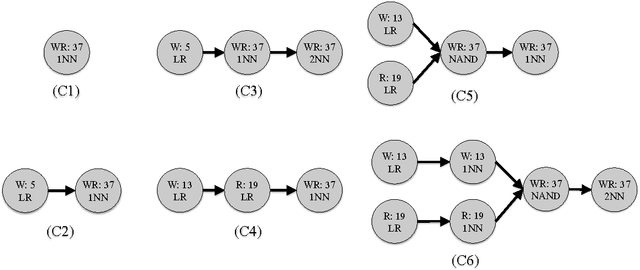
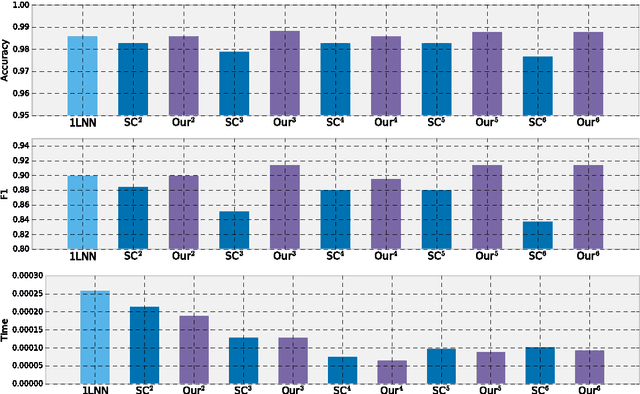
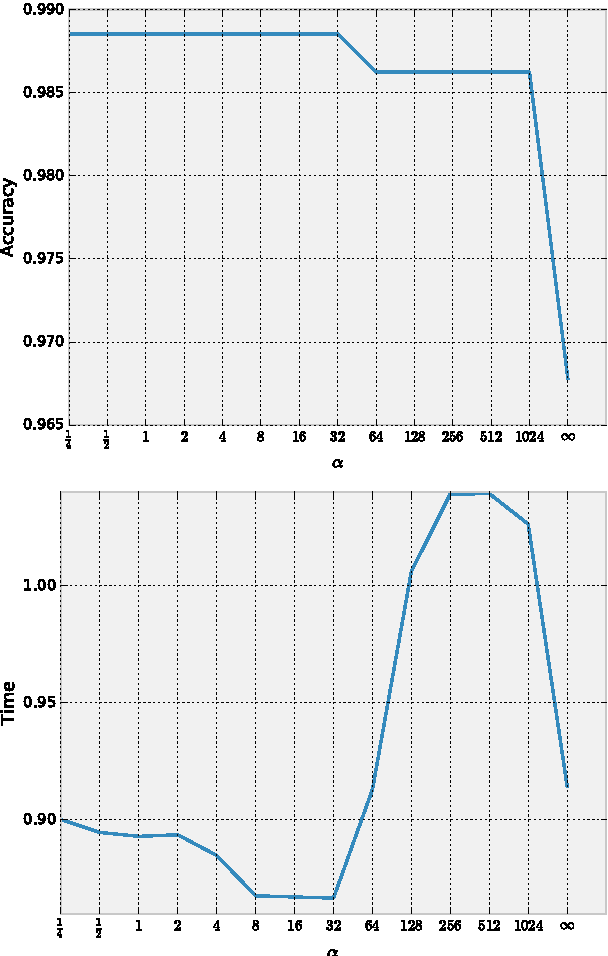
In this paper, we present a new approach to learning cascaded classifiers for use in computing environments that involve networks of heterogeneous and resource-constrained, low-power embedded compute and sensing nodes. We present a generalization of the classical linear detection cascade to the case of tree-structured cascades where different branches of the tree execute on different physical compute nodes in the network. Different nodes have access to different features, as well as access to potentially different computation and energy resources. We concentrate on the problem of jointly learning the parameters for all of the classifiers in the cascade given a fixed cascade architecture and a known set of costs required to carry out the computation at each node.To accomplish the objective of joint learning of all detectors, we propose a novel approach to combining classifier outputs during training that better matches the hard cascade setting in which the learned system will be deployed. This work is motivated by research in the area of mobile health where energy efficient real time detectors integrating information from multiple wireless on-body sensors and a smart phone are needed for real-time monitoring and delivering just- in-time adaptive interventions. We apply our framework to two activity recognition datasets as well as the problem of cigarette smoking detection from a combination of wrist-worn actigraphy data and respiration chest band data.
Learning Shallow Detection Cascades for Wearable Sensor-Based Mobile Health Applications
Jul 13, 2016
The field of mobile health aims to leverage recent advances in wearable on-body sensing technology and smart phone computing capabilities to develop systems that can monitor health states and deliver just-in-time adaptive interventions. However, existing work has largely focused on analyzing collected data in the off-line setting. In this paper, we propose a novel approach to learning shallow detection cascades developed explicitly for use in a real-time wearable-phone or wearable-phone-cloud systems. We apply our approach to the problem of cigarette smoking detection from a combination of wrist-worn actigraphy data and respiration chest band data using two and three stage cascades.
Masking Strategies for Image Manifolds
Jun 15, 2016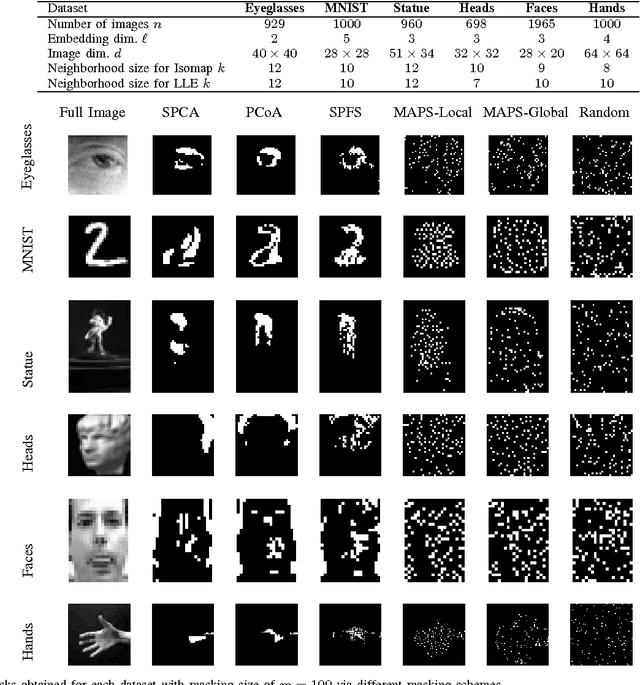
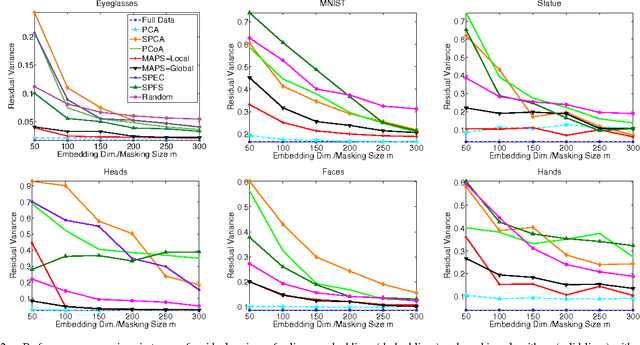
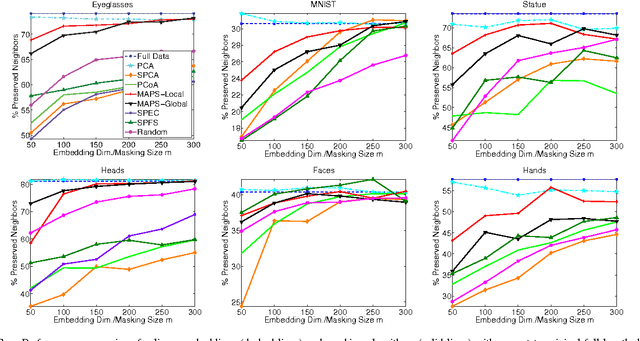
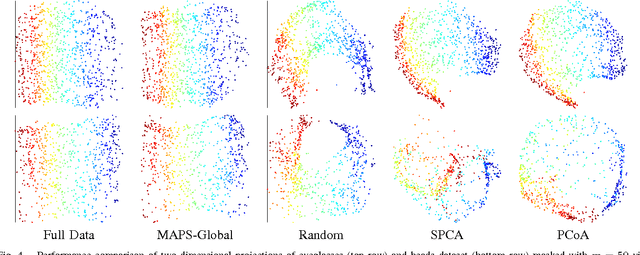
We consider the problem of selecting an optimal mask for an image manifold, i.e., choosing a subset of the pixels of the image that preserves the manifold's geometric structure present in the original data. Such masking implements a form of compressive sensing through emerging imaging sensor platforms for which the power expense grows with the number of pixels acquired. Our goal is for the manifold learned from masked images to resemble its full image counterpart as closely as possible. More precisely, we show that one can indeed accurately learn an image manifold without having to consider a large majority of the image pixels. In doing so, we consider two masking methods that preserve the local and global geometric structure of the manifold, respectively. In each case, the process of finding the optimal masking pattern can be cast as a binary integer program, which is computationally expensive but can be approximated by a fast greedy algorithm. Numerical experiments show that the relevant manifold structure is preserved through the data-dependent masking process, even for modest mask sizes.