 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWMT24++: Expanding the Language Coverage of WMT24 to 55 Languages & Dialects
Feb 18, 2025
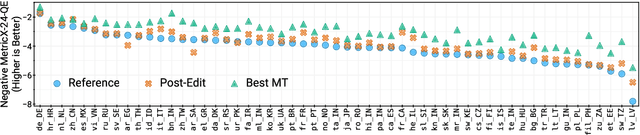


As large language models (LLM) become more and more capable in languages other than English, it is important to collect benchmark datasets in order to evaluate their multilingual performance, including on tasks like machine translation (MT). In this work, we extend the WMT24 dataset to cover 55 languages by collecting new human-written references and post-edits for 46 new languages and dialects in addition to post-edits of the references in 8 out of 9 languages in the original WMT24 dataset. The dataset covers four domains: literary, news, social, and speech. We benchmark a variety of MT providers and LLMs on the collected dataset using automatic metrics and find that LLMs are the best-performing MT systems in all 55 languages. These results should be confirmed using a human-based evaluation, which we leave for future work.
Learning from others' mistakes: Finetuning machine translation models with span-level error annotations
Oct 21, 2024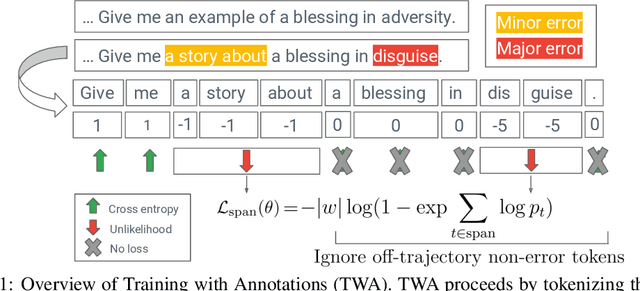


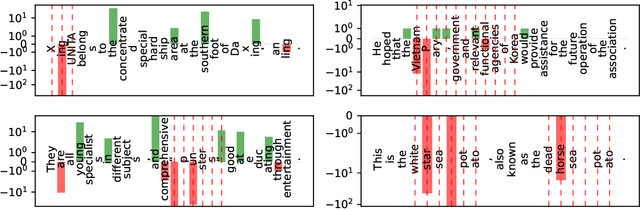
Despite growing interest in incorporating feedback to improve language models, most efforts focus only on sequence-level annotations. In this work, we explore the potential of utilizing fine-grained span-level annotations from offline datasets to improve model quality. We develop a simple finetuning algorithm, called Training with Annotations (TWA), to directly train machine translation models on such annotated data. TWA utilizes targeted span-level error information while also flexibly learning what to penalize within a span. Moreover, TWA considers the overall trajectory of a sequence when deciding which non-error spans to utilize as positive signals. Experiments on English-German and Chinese-English machine translation show that TWA outperforms baselines such as Supervised FineTuning on sequences filtered for quality and Direct Preference Optimization on pairs constructed from the same data.
Efficient Minimum Bayes Risk Decoding using Low-Rank Matrix Completion Algorithms
Jun 05, 2024Minimum Bayes Risk (MBR) decoding is a powerful decoding strategy widely used for text generation tasks, but its quadratic computational complexity limits its practical application. This paper presents a novel approach for approximating MBR decoding using matrix completion techniques, focusing on the task of machine translation. We formulate MBR decoding as a matrix completion problem, where the utility metric scores between candidate hypotheses and pseudo-reference translations form a low-rank matrix. First, we empirically show that the scores matrices indeed have a low-rank structure. Then, we exploit this by only computing a random subset of the scores and efficiently recover the missing entries in the matrix by applying the Alternating Least Squares (ALS) algorithm, thereby enabling a fast approximation of the MBR decoding process. Our experimental results on machine translation tasks demonstrate that the proposed method requires 1/16 utility metric computations compared to vanilla MBR decoding while achieving equal translation quality measured by COMET22 on the WMT22 dataset (en<>de and en<>ru). We also benchmark our method against other approximation methods and we show gains in quality when comparing to them.