 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous battery research: Principles of heuristic operando experimentation
Dec 29, 2025Unravelling the complex processes governing battery degradation is critical to the energy transition, yet the efficacy of operando characterisation is severely constrained by a lack of Reliability, Representativeness, and Reproducibility (the 3Rs). Current methods rely on bespoke hardware and passive, pre-programmed methodologies that are ill-equipped to capture stochastic failure events. Here, using the Rutherford Appleton Laboratory's multi-modal toolkit as a case study, we expose the systemic inability of conventional experiments to capture transient phenomena like dendrite initiation. To address this, we propose Heuristic Operando experiments: a framework where an AI pilot leverages physics-based digital twins to actively steer the beamline to predict and deterministically capture these rare events. Distinct from uncertainty-driven active learning, this proactive search anticipates failure precursors, redefining experimental efficiency via an entropy-based metric that prioritises scientific insight per photon, neutron, or muon. By focusing measurements only on mechanistically decisive moments, this framework simultaneously mitigates beam damage and drastically reduces data redundancy. When integrated with FAIR data principles, this approach serves as a blueprint for the trusted autonomous battery laboratories of the future.
Wearable Meets LLM for Stress Management: A Duoethnographic Study Integrating Wearable-Triggered Stressors and LLM Chatbots for Personalized Interventions
Feb 24, 2025

We use a duoethnographic approach to study how wearable-integrated LLM chatbots can assist with personalized stress management, addressing the growing need for immediacy and tailored interventions. Two researchers interacted with custom chatbots over 22 days, responding to wearable-detected physiological prompts, recording stressor phrases, and using them to seek tailored interventions from their LLM-powered chatbots. They recorded their experiences in autoethnographic diaries and analyzed them during weekly discussions, focusing on the relevance, clarity, and impact of chatbot-generated interventions. Results showed that even though most events triggered by the wearable were meaningful, only one in five warranted an intervention. It also showed that interventions tailored with brief event descriptions were more effective than generic ones. By examining the intersection of wearables and LLM, this research contributes to developing more effective, user-centric mental health tools for real-time stress relief and behavior change.
Pulse-PPG: An Open-Source Field-Trained PPG Foundation Model for Wearable Applications Across Lab and Field Settings
Feb 03, 2025Photoplethysmography (PPG)-based foundation models are gaining traction due to the widespread use of PPG in biosignal monitoring and their potential to generalize across diverse health applications. In this paper, we introduce Pulse-PPG, the first open-source PPG foundation model trained exclusively on raw PPG data collected over a 100-day field study with 120 participants. Existing PPG foundation models are either open-source but trained on clinical data or closed-source, limiting their applicability in real-world settings. We evaluate Pulse-PPG across multiple datasets and downstream tasks, comparing its performance against a state-of-the-art foundation model trained on clinical data. Our results demonstrate that Pulse-PPG, trained on uncurated field data, exhibits superior generalization across clinical and mobile health applications in both lab and field settings. This suggests that exposure to real-world variability enables the model to learn fine-grained representations, making it more adaptable across tasks. Furthermore, pre-training on field data surprisingly outperforms its pre-training on clinical data in many tasks, reinforcing the importance of training on real-world, diverse datasets. To encourage further advancements in robust foundation models leveraging field data, we plan to release Pulse-PPG, providing researchers with a powerful resource for developing more generalizable PPG-based models.
Machine Learning Algorithms for Detecting Mental Stress in College Students
Dec 10, 2024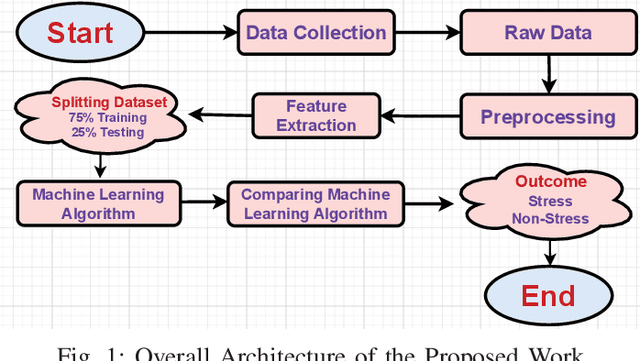
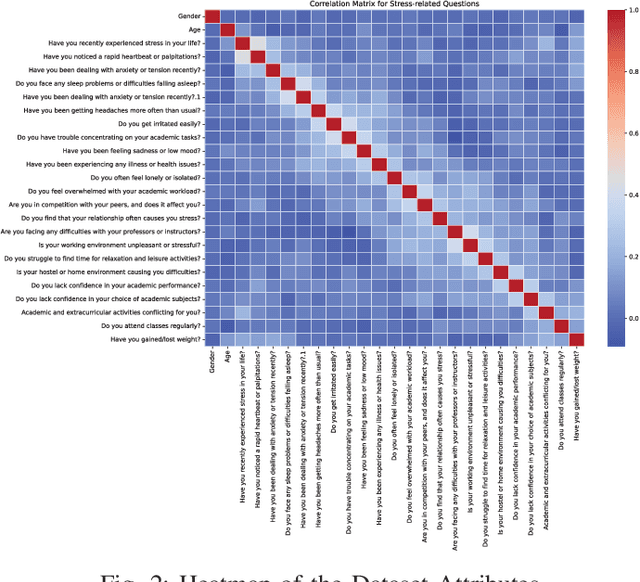
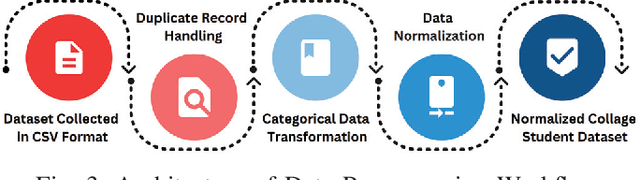
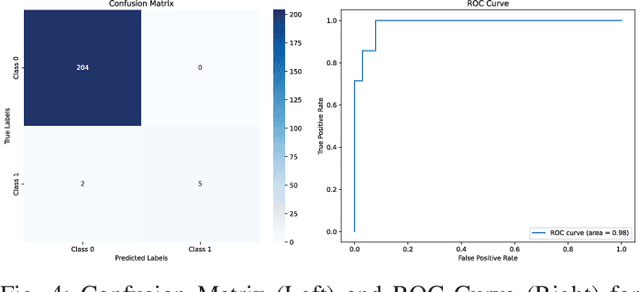
In today's world, stress is a big problem that affects people's health and happiness. More and more people are feeling stressed out, which can lead to lots of health issues like breathing problems, feeling overwhelmed, heart attack, diabetes, etc. This work endeavors to forecast stress and non-stress occurrences among college students by applying various machine learning algorithms: Decision Trees, Random Forest, Support Vector Machines, AdaBoost, Naive Bayes, Logistic Regression, and K-nearest Neighbors. The primary objective of this work is to leverage a research study to predict and mitigate stress and non-stress based on the collected questionnaire dataset. We conducted a workshop with the primary goal of studying the stress levels found among the students. This workshop was attended by Approximately 843 students aged between 18 to 21 years old. A questionnaire was given to the students validated under the guidance of the experts from the All India Institute of Medical Sciences (AIIMS) Raipur, Chhattisgarh, India, on which our dataset is based. The survey consists of 28 questions, aiming to comprehensively understand the multidimensional aspects of stress, including emotional well-being, physical health, academic performance, relationships, and leisure. This work finds that Support Vector Machines have a maximum accuracy for Stress, reaching 95\%. The study contributes to a deeper understanding of stress determinants. It aims to improve college student's overall quality of life and academic success, addressing the multifaceted nature of stress.
* This paper was presented at an IEEE conference and is 5 pages long with 5 figures. It discusses machine learning algorithms for detecting mental stress in college students
Temporally Multi-Scale Sparse Self-Attention for Physical Activity Data Imputation
Jun 27, 2024Wearable sensors enable health researchers to continuously collect data pertaining to the physiological state of individuals in real-world settings. However, such data can be subject to extensive missingness due to a complex combination of factors. In this work, we study the problem of imputation of missing step count data, one of the most ubiquitous forms of wearable sensor data. We construct a novel and large scale data set consisting of a training set with over 3 million hourly step count observations and a test set with over 2.5 million hourly step count observations. We propose a domain knowledge-informed sparse self-attention model for this task that captures the temporal multi-scale nature of step-count data. We assess the performance of the model relative to baselines and conduct ablation studies to verify our specific model designs.
Analysis of system capacity and spectral efficiency of fixed-grid network
Sep 30, 2023
In this article, the performance of a fixed grid network is examined for various modulation formats to estimate the system's capacity and spectral efficiency. The optical In-phase Quadrature Modulator structure is used to build a fixed grid network modulation, and the homodyne detection approach is used for the receiver. Data multiplexing is accomplished using the Polarization Division Multiplexed technology. 100 Gbps, 150 Gbps, and 200 Gbps data rates are transmitted under these circumstances utilizing various modulation formats. Various pre-processing and signal recovery steps are explained by using modern digital signal processing systems. The achieved spectrum efficiencies for PM-QPSK, PM-8 QAM, and PM-16 QAM, respectively, were 2, 3, and 4 bits/s/Hz. Different modulation like PM-QPSK, PM-8-QAM, and PM-16-QAM each has system capacities of 8-9, 12-13.5, and 16-18 Tbps and it reaches transmission distances of 3000, 1300, and 700 kilometers with acceptable Bit Error Rate less than equal to 2*10-3 respectively. Peak optical power for received signal detection and full width at half maximum is noted for the different modulations under a fixed grind network.
Flexible Beamforming in B5G for Improving Tethered UAV Coverage over Smart Environments
Jul 14, 2023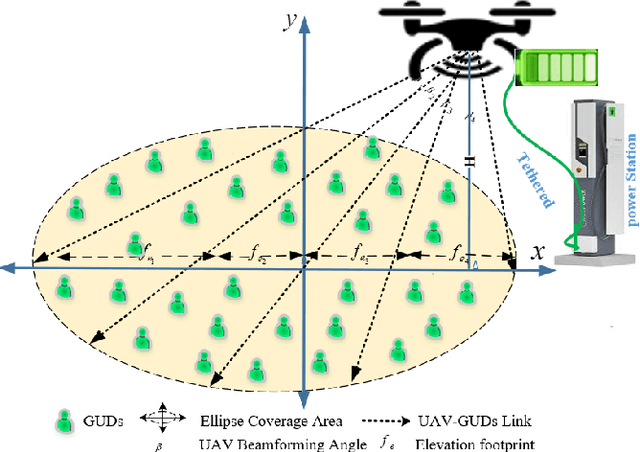
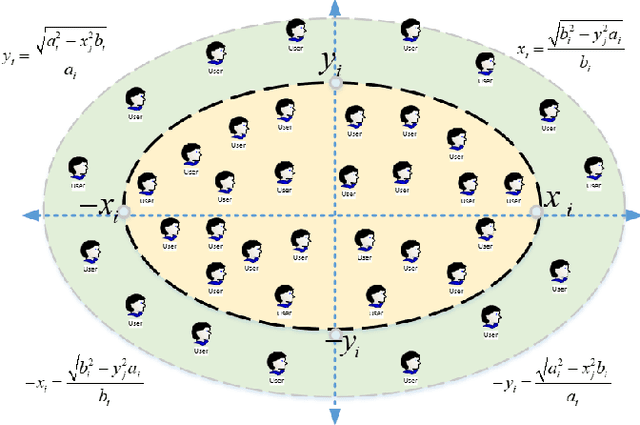
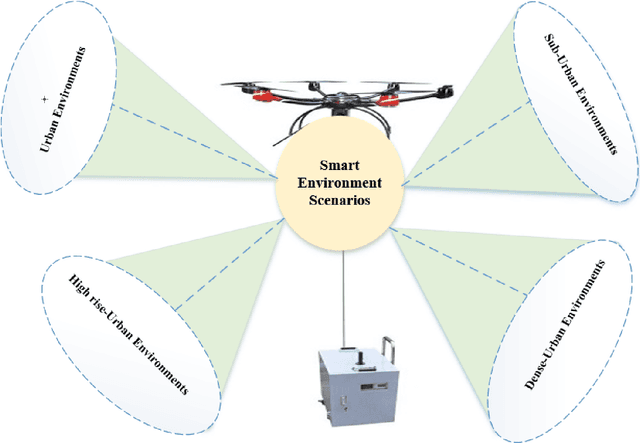
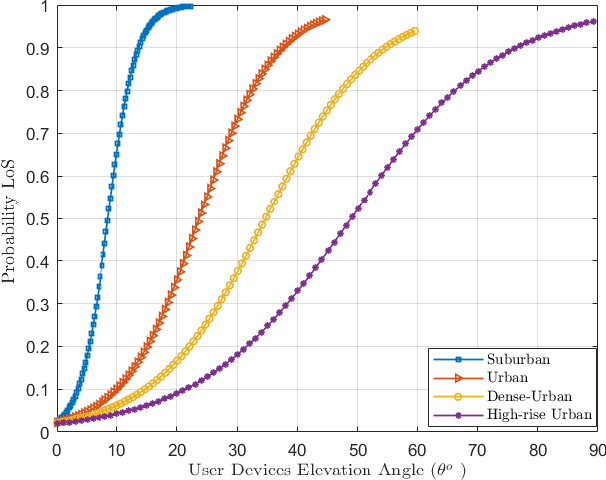
Unmanned Aerial Vehicles (UAVs) are being used for wireless communications in smart environments. However, the need for mobility, scalability of data transmission over wide areas, and the required coverage area make UAV beamforming essential for better coverage and user experience. To this end, we propose a flexible beamforming approach to improve tethered UAV coverage quality and maximize the number of users experiencing the minimum required rate in any target environment. Our solution demonstrates a significant achievement in flexible beamforming in smart environments, including urban, suburban, dense, and high-rise urban. Furthermore, the beamforming gain is mainly concentrated in the target to improve the coverage area based on various scenarios. Simulation results show that the proposed approach can achieve a significantly received flexible power beam that focuses the transmitted signal towards the receiver and improves received power by reducing signal power spread. In the case of no beamforming, signal power spreads out as distance increases, reducing the signal strength. Furthermore, our proposed solution is suitable for improving UAV coverage and reliability in smart and harsh environments.
A Novel end-to-end Framework for Occluded Pixel Reconstruction with Spatio-temporal Features for Improved Person Re-identification
Apr 16, 2023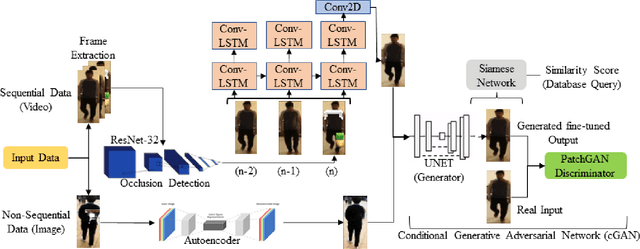

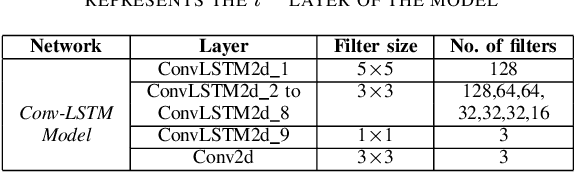
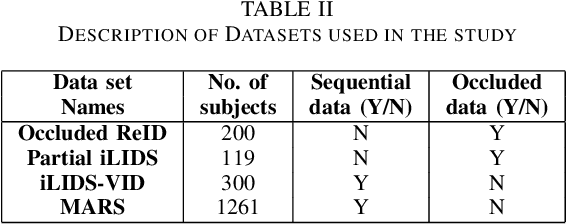
Person re-identification is vital for monitoring and tracking crowd movement to enhance public security. However, re-identification in the presence of occlusion substantially reduces the performance of existing systems and is a challenging area. In this work, we propose a plausible solution to this problem by developing effective occlusion detection and reconstruction framework for RGB images/videos consisting of Deep Neural Networks. Specifically, a CNN-based occlusion detection model classifies individual input frames, followed by a Conv-LSTM and Autoencoder to reconstruct the occluded pixels corresponding to the occluded frames for sequential (video) and non-sequential (image) data, respectively. The quality of the reconstructed RGB frames is further refined and fine-tuned using a Conditional Generative Adversarial Network (cGAN). Our method is evaluated on four well-known public data sets of the domain, and the qualitative reconstruction results are indeed appealing. Quantitative evaluation in terms of re-identification accuracy of the Siamese network showed an exceptional Rank-1 accuracy after occluded pixel reconstruction on various datasets. A comparative analysis with state-of-the-art approaches also demonstrates the robustness of our work for use in real-life surveillance systems.
PulseImpute: A Novel Benchmark Task for Pulsative Physiological Signal Imputation
Dec 14, 2022The promise of Mobile Health (mHealth) is the ability to use wearable sensors to monitor participant physiology at high frequencies during daily life to enable temporally-precise health interventions. However, a major challenge is frequent missing data. Despite a rich imputation literature, existing techniques are ineffective for the pulsative signals which comprise many mHealth applications, and a lack of available datasets has stymied progress. We address this gap with PulseImpute, the first large-scale pulsative signal imputation challenge which includes realistic mHealth missingness models, an extensive set of baselines, and clinically-relevant downstream tasks. Our baseline models include a novel transformer-based architecture designed to exploit the structure of pulsative signals. We hope that PulseImpute will enable the ML community to tackle this significant and challenging task.
Transformers for prompt-level EMA non-response prediction
Nov 01, 2021
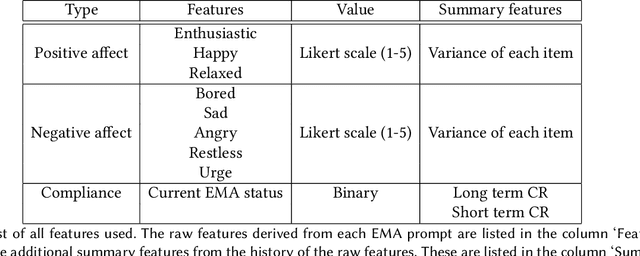
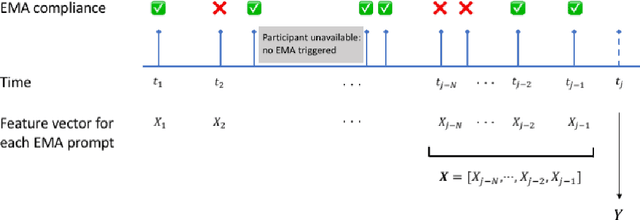

Ecological Momentary Assessments (EMAs) are an important psychological data source for measuring current cognitive states, affect, behavior, and environmental factors from participants in mobile health (mHealth) studies and treatment programs. Non-response, in which participants fail to respond to EMA prompts, is an endemic problem. The ability to accurately predict non-response could be utilized to improve EMA delivery and develop compliance interventions. Prior work has explored classical machine learning models for predicting non-response. However, as increasingly large EMA datasets become available, there is the potential to leverage deep learning models that have been effective in other fields. Recently, transformer models have shown state-of-the-art performance in NLP and other domains. This work is the first to explore the use of transformers for EMA data analysis. We address three key questions in applying transformers to EMA data: 1. Input representation, 2. encoding temporal information, 3. utility of pre-training on improving downstream prediction task performance. The transformer model achieves a non-response prediction AUC of 0.77 and is significantly better than classical ML and LSTM-based deep learning models. We will make our a predictive model trained on a corpus of 40K EMA samples freely-available to the research community, in order to facilitate the development of future transformer-based EMA analysis works.