 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DS-SLAM: A 3D Object Detection based Semantic SLAM towards Dynamic Indoor Environments
Oct 10, 2023The existence of variable factors within the environment can cause a decline in camera localization accuracy, as it violates the fundamental assumption of a static environment in Simultaneous Localization and Mapping (SLAM) algorithms. Recent semantic SLAM systems towards dynamic environments either rely solely on 2D semantic information, or solely on geometric information, or combine their results in a loosely integrated manner. In this research paper, we introduce 3DS-SLAM, 3D Semantic SLAM, tailored for dynamic scenes with visual 3D object detection. The 3DS-SLAM is a tightly-coupled algorithm resolving both semantic and geometric constraints sequentially. We designed a 3D part-aware hybrid transformer for point cloud-based object detection to identify dynamic objects. Subsequently, we propose a dynamic feature filter based on HDBSCAN clustering to extract objects with significant absolute depth differences. When compared against ORB-SLAM2, 3DS-SLAM exhibits an average improvement of 98.01% across the dynamic sequences of the TUM RGB-D dataset. Furthermore, it surpasses the performance of the other four leading SLAM systems designed for dynamic environments.
Breast Cancer Segmentation using Attention-based Convolutional Network and Explainable AI
May 22, 2023Breast cancer (BC) remains a significant health threat, with no long-term cure currently available. Early detection is crucial, yet mammography interpretation is hindered by high false positives and negatives. With BC incidence projected to surpass lung cancer, improving early detection methods is vital. Thermography, using high-resolution infrared cameras, offers promise, especially when combined with artificial intelligence (AI). This work presents an attention-based convolutional neural network for segmentation, providing increased speed and precision in BC detection and classification. The system enhances images and performs cancer segmentation with explainable AI. We propose a transformer-attention-based convolutional architecture (UNet) for fault identification and employ Gradient-weighted Class Activation Mapping (Grad-CAM) to analyze areas of bias and weakness in the UNet architecture with IRT images. The superiority of our proposed framework is confirmed when compared with existing deep learning frameworks.
A Novel end-to-end Framework for Occluded Pixel Reconstruction with Spatio-temporal Features for Improved Person Re-identification
Apr 16, 2023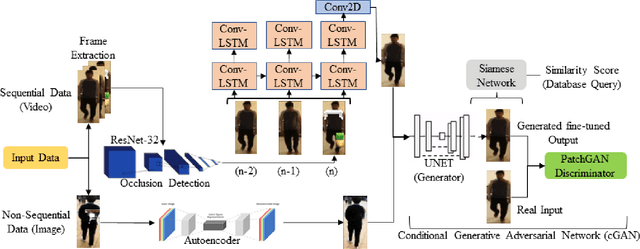

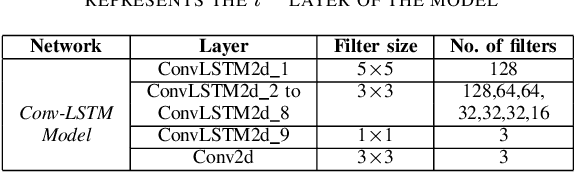
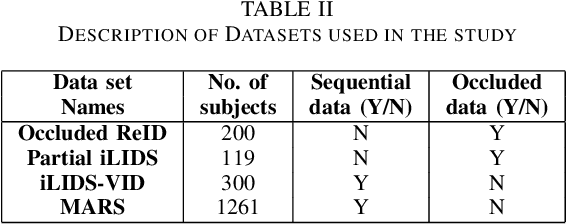
Person re-identification is vital for monitoring and tracking crowd movement to enhance public security. However, re-identification in the presence of occlusion substantially reduces the performance of existing systems and is a challenging area. In this work, we propose a plausible solution to this problem by developing effective occlusion detection and reconstruction framework for RGB images/videos consisting of Deep Neural Networks. Specifically, a CNN-based occlusion detection model classifies individual input frames, followed by a Conv-LSTM and Autoencoder to reconstruct the occluded pixels corresponding to the occluded frames for sequential (video) and non-sequential (image) data, respectively. The quality of the reconstructed RGB frames is further refined and fine-tuned using a Conditional Generative Adversarial Network (cGAN). Our method is evaluated on four well-known public data sets of the domain, and the qualitative reconstruction results are indeed appealing. Quantitative evaluation in terms of re-identification accuracy of the Siamese network showed an exceptional Rank-1 accuracy after occluded pixel reconstruction on various datasets. A comparative analysis with state-of-the-art approaches also demonstrates the robustness of our work for use in real-life surveillance systems.
LesionAid: Vision Transformers-based Skin Lesion Generation and Classification
Feb 02, 2023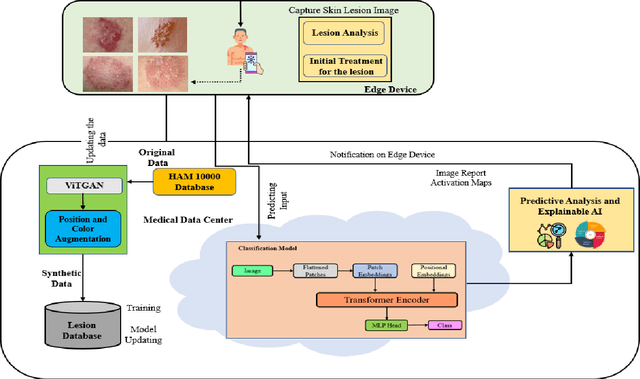

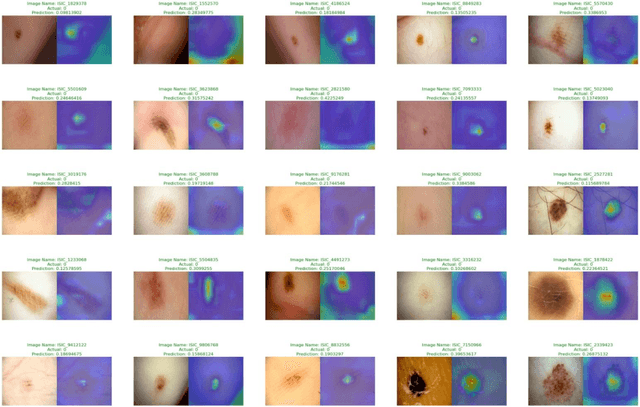
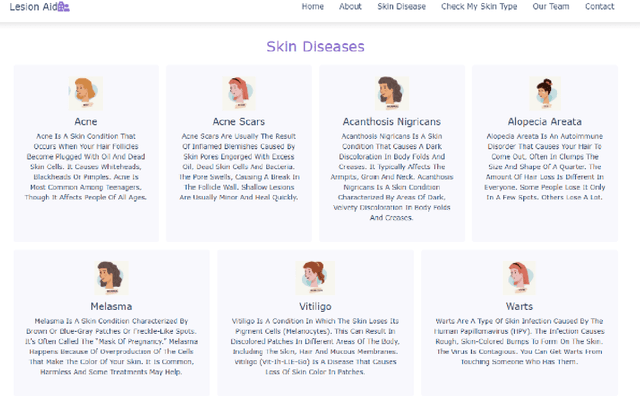
Skin cancer is one of the most prevalent forms of human cancer. It is recognized mainly visually, beginning with clinical screening and continuing with the dermoscopic examination, histological assessment, and specimen collection. Deep convolutional neural networks (CNNs) perform highly segregated and potentially universal tasks against a classified finegrained object. This research proposes a novel multi-class prediction framework that classifies skin lesions based on ViT and ViTGAN. Vision transformers-based GANs (Generative Adversarial Networks) are utilized to tackle the class imbalance. The framework consists of four main phases: ViTGANs, Image processing, and explainable AI. Phase 1 consists of generating synthetic images to balance all the classes in the dataset. Phase 2 consists of applying different data augmentation techniques and morphological operations to increase the size of the data. Phases 3 & 4 involve developing a ViT model for edge computing systems that can identify patterns and categorize skin lesions from the user's skin visible in the image. In phase 3, after classifying the lesions into the desired class with ViT, we will use explainable AI (XAI) that leads to more explainable results (using activation maps, etc.) while ensuring high predictive accuracy. Real-time images of skin diseases can capture by a doctor or a patient using the camera of a mobile application to perform an early examination and determine the cause of the skin lesion. The whole framework is compared with the existing frameworks for skin lesion detection.
Video Vision Transformers for Violence Detection
Sep 08, 2022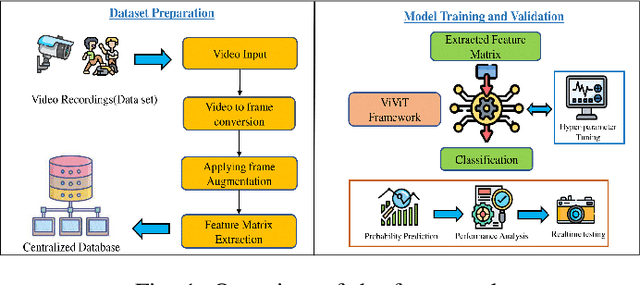
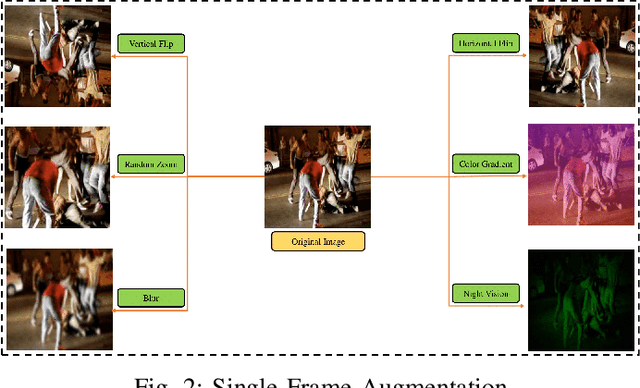
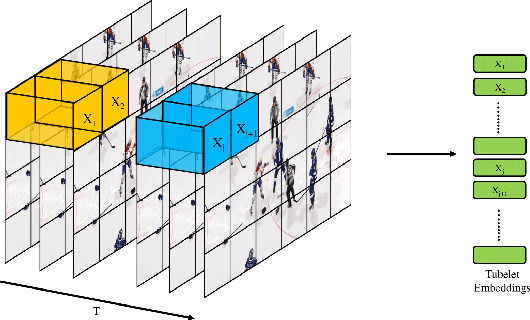
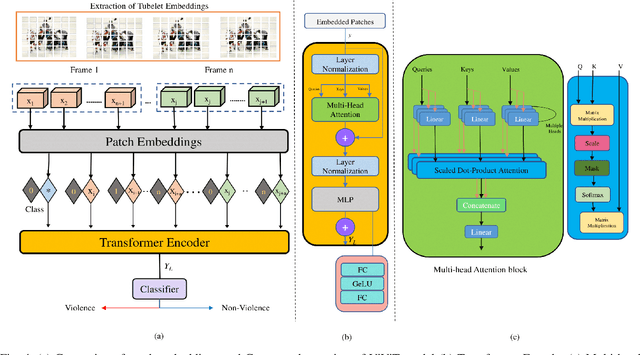
Law enforcement and city safety are significantly impacted by detecting violent incidents in surveillance systems. Although modern (smart) cameras are widely available and affordable, such technological solutions are impotent in most instances. Furthermore, personnel monitoring CCTV recordings frequently show a belated reaction, resulting in the potential cause of catastrophe to people and property. Thus automated detection of violence for swift actions is very crucial. The proposed solution uses a novel end-to-end deep learning-based video vision transformer (ViViT) that can proficiently discern fights, hostile movements, and violent events in video sequences. The study presents utilizing a data augmentation strategy to overcome the downside of weaker inductive biasness while training vision transformers on a smaller training datasets. The evaluated results can be subsequently sent to local concerned authority, and the captured video can be analyzed. In comparison to state-of-theart (SOTA) approaches the proposed method achieved auspicious performance on some of the challenging benchmark datasets.
Vision Transformers and YoloV5 based Driver Drowsiness Detection Framework
Sep 03, 2022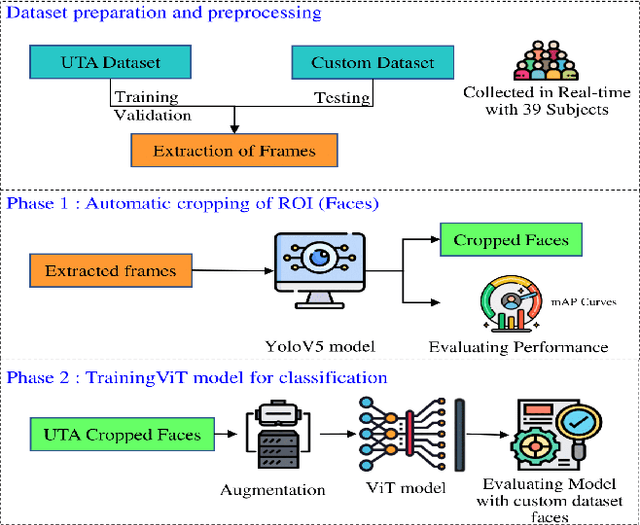
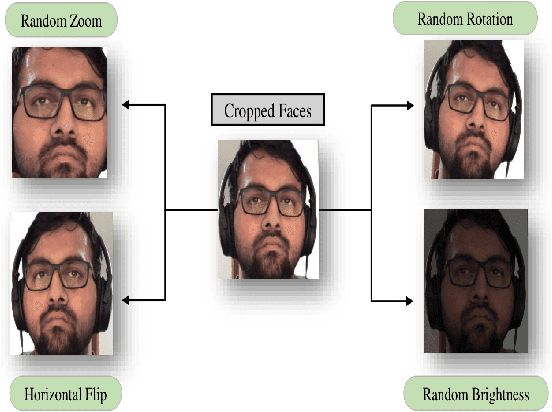

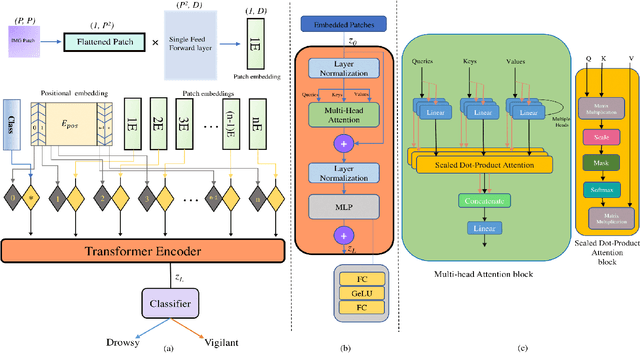
Human drivers have distinct driving techniques, knowledge, and sentiments due to unique driving traits. Driver drowsiness has been a serious issue endangering road safety; therefore, it is essential to design an effective drowsiness detection algorithm to bypass road accidents. Miscellaneous research efforts have been approached the problem of detecting anomalous human driver behaviour to examine the frontal face of the driver and automobile dynamics via computer vision techniques. Still, the conventional methods cannot capture complicated driver behaviour features. However, with the origin of deep learning architectures, a substantial amount of research has also been executed to analyze and recognize driver's drowsiness using neural network algorithms. This paper introduces a novel framework based on vision transformers and YoloV5 architectures for driver drowsiness recognition. A custom YoloV5 pre-trained architecture is proposed for face extraction with the aim of extracting Region of Interest (ROI). Owing to the limitations of previous architectures, this paper introduces vision transformers for binary image classification which is trained and validated on a public dataset UTA-RLDD. The model had achieved 96.2\% and 97.4\% as it's training and validation accuracies respectively. For the further evaluation, proposed framework is tested on a custom dataset of 39 participants in various light circumstances and achieved 95.5\% accuracy. The conducted experimentations revealed the significant potential of our framework for practical applications in smart transportation systems.
Epersist: A Self Balancing Robot Using PID Controller And Deep Reinforcement Learning
Jul 23, 2022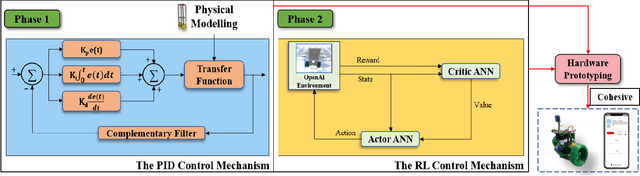
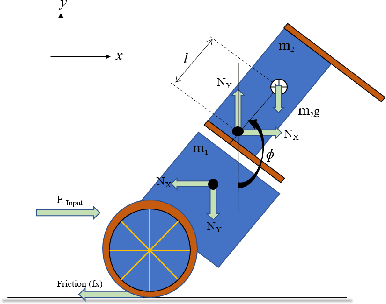
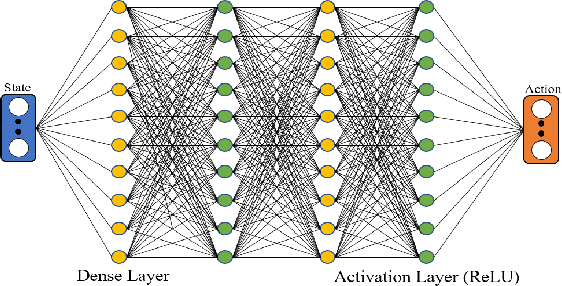

A two-wheeled self-balancing robot is an example of an inverse pendulum and is an inherently non-linear, unstable system. The fundamental concept of the proposed framework "Epersist" is to overcome the challenge of counterbalancing an initially unstable system by delivering robust control mechanisms, Proportional Integral Derivative(PID), and Reinforcement Learning (RL). Moreover, the micro-controller NodeMCUESP32 and inertial sensor in the Epersist employ fewer computational procedures to give accurate instruction regarding the spin of wheels to the motor driver, which helps control the wheels and balance the robot. This framework also consists of the mathematical model of the PID controller and a novel self-trained advantage actor-critic algorithm as the RL agent. After several experiments, control variable calibrations are made as the benchmark values to attain the angle of static equilibrium. This "Epersist" framework proposes PID and RL-assisted functional prototypes and simulations for better utility.