 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoVid-19 Detection leveraging Vision Transformers and Explainable AI
Jul 29, 2023Lung disease is a common health problem in many parts of the world. It is a significant risk to people health and quality of life all across the globe since it is responsible for five of the top thirty leading causes of death. Among them are COVID 19, pneumonia, and tuberculosis, to name just a few. It is critical to diagnose lung diseases in their early stages. Several different models including machine learning and image processing have been developed for this purpose. The earlier a condition is diagnosed, the better the patient chances of making a full recovery and surviving into the long term. Thanks to deep learning algorithms, there is significant promise for the autonomous, rapid, and accurate identification of lung diseases based on medical imaging. Several different deep learning strategies, including convolutional neural networks (CNN), vanilla neural networks, visual geometry group based networks (VGG), and capsule networks , are used for the goal of making lung disease forecasts. The standard CNN has a poor performance when dealing with rotated, tilted, or other aberrant picture orientations. As a result of this, within the scope of this study, we have suggested a vision transformer based approach end to end framework for the diagnosis of lung disorders. In the architecture, data augmentation, training of the suggested models, and evaluation of the models are all included. For the purpose of detecting lung diseases such as pneumonia, Covid 19, lung opacity, and others, a specialised Compact Convolution Transformers (CCT) model have been tested and evaluated on datasets such as the Covid 19 Radiography Database. The model has achieved a better accuracy for both its training and validation purposes on the Covid 19 Radiography Database.
Image-based Indian Sign Language Recognition: A Practical Review using Deep Neural Networks
Apr 28, 2023



People with vocal and hearing disabilities use sign language to express themselves using visual gestures and signs. Although sign language is a solution for communication difficulties faced by deaf people, there are still problems as most of the general population cannot understand this language, creating a communication barrier, especially in places such as banks, airports, supermarkets, etc. [1]. A sign language recognition(SLR) system is a must to solve this problem. The main focus of this model is to develop a real-time word-level sign language recognition system that would translate sign language to text. Much research has been done on ASL(American sign language). Thus, we have worked on ISL(Indian sign language) to cater to the needs of the deaf and hard-of-hearing community of India[2]. In this research, we provide an Indian Sign Language-based Sign Language recognition system. For this analysis, the user must be able to take pictures of hand movements using a web camera, and the system must anticipate and display the name of the taken picture. The acquired image goes through several processing phases, some of which use computer vision techniques, including grayscale conversion, dilatation, and masking. Our model is trained using a convolutional neural network (CNN), which is then utilized to recognize the images. Our best model has a 99% accuracy rate[3].
LesionAid: Vision Transformers-based Skin Lesion Generation and Classification
Feb 02, 2023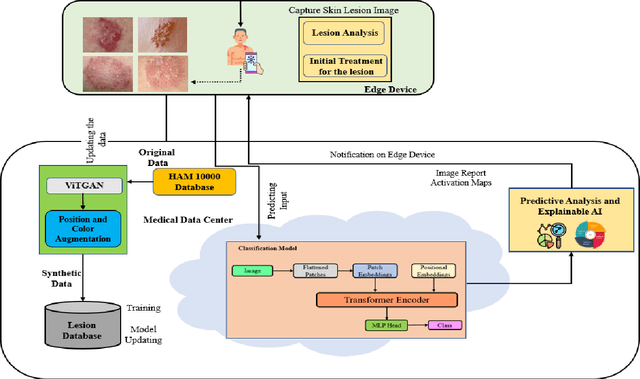

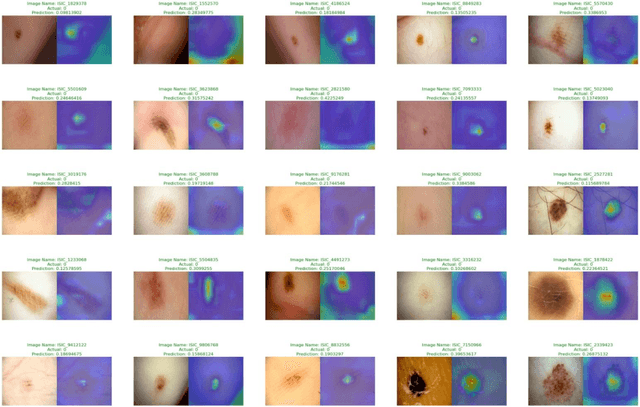
Skin cancer is one of the most prevalent forms of human cancer. It is recognized mainly visually, beginning with clinical screening and continuing with the dermoscopic examination, histological assessment, and specimen collection. Deep convolutional neural networks (CNNs) perform highly segregated and potentially universal tasks against a classified finegrained object. This research proposes a novel multi-class prediction framework that classifies skin lesions based on ViT and ViTGAN. Vision transformers-based GANs (Generative Adversarial Networks) are utilized to tackle the class imbalance. The framework consists of four main phases: ViTGANs, Image processing, and explainable AI. Phase 1 consists of generating synthetic images to balance all the classes in the dataset. Phase 2 consists of applying different data augmentation techniques and morphological operations to increase the size of the data. Phases 3 & 4 involve developing a ViT model for edge computing systems that can identify patterns and categorize skin lesions from the user's skin visible in the image. In phase 3, after classifying the lesions into the desired class with ViT, we will use explainable AI (XAI) that leads to more explainable results (using activation maps, etc.) while ensuring high predictive accuracy. Real-time images of skin diseases can capture by a doctor or a patient using the camera of a mobile application to perform an early examination and determine the cause of the skin lesion. The whole framework is compared with the existing frameworks for skin lesion detection.
Vision Transformers and YoloV5 based Driver Drowsiness Detection Framework
Sep 03, 2022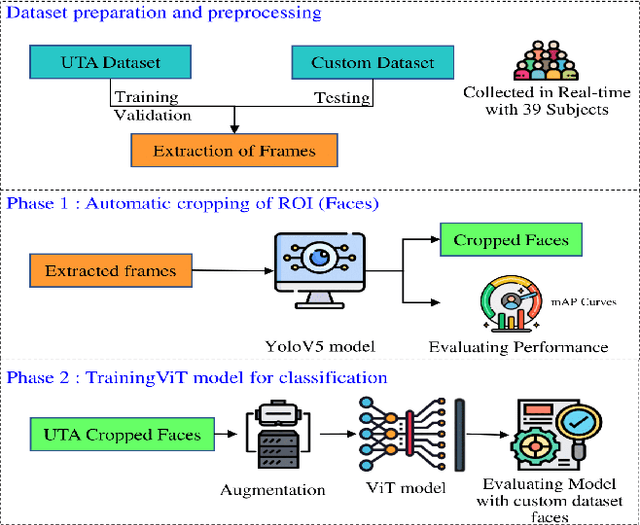
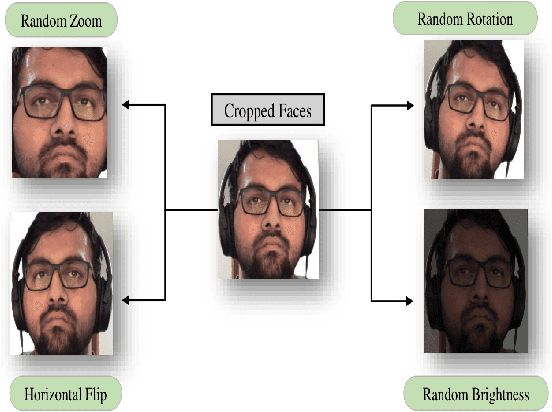

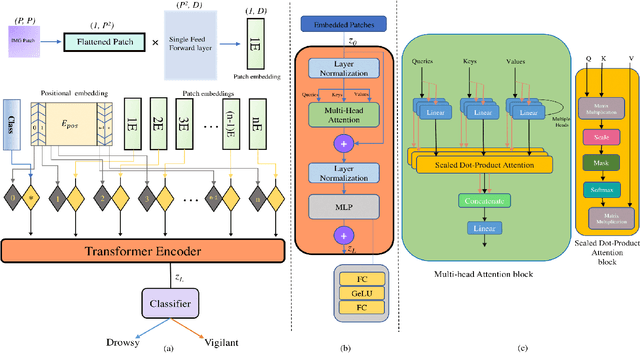
Human drivers have distinct driving techniques, knowledge, and sentiments due to unique driving traits. Driver drowsiness has been a serious issue endangering road safety; therefore, it is essential to design an effective drowsiness detection algorithm to bypass road accidents. Miscellaneous research efforts have been approached the problem of detecting anomalous human driver behaviour to examine the frontal face of the driver and automobile dynamics via computer vision techniques. Still, the conventional methods cannot capture complicated driver behaviour features. However, with the origin of deep learning architectures, a substantial amount of research has also been executed to analyze and recognize driver's drowsiness using neural network algorithms. This paper introduces a novel framework based on vision transformers and YoloV5 architectures for driver drowsiness recognition. A custom YoloV5 pre-trained architecture is proposed for face extraction with the aim of extracting Region of Interest (ROI). Owing to the limitations of previous architectures, this paper introduces vision transformers for binary image classification which is trained and validated on a public dataset UTA-RLDD. The model had achieved 96.2\% and 97.4\% as it's training and validation accuracies respectively. For the further evaluation, proposed framework is tested on a custom dataset of 39 participants in various light circumstances and achieved 95.5\% accuracy. The conducted experimentations revealed the significant potential of our framework for practical applications in smart transportation systems.