 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Smart Malnutrition Monitoring: A Multi-Modal Learning Approach for Vital Health Parameter Estimation
Jul 31, 2023



Malnutrition poses a significant threat to global health, resulting from an inadequate intake of essential nutrients that adversely impacts vital organs and overall bodily functioning. Periodic examinations and mass screenings, incorporating both conventional and non-invasive techniques, have been employed to combat this challenge. However, these approaches suffer from critical limitations, such as the need for additional equipment, lack of comprehensive feature representation, absence of suitable health indicators, and the unavailability of smartphone implementations for precise estimations of Body Fat Percentage (BFP), Basal Metabolic Rate (BMR), and Body Mass Index (BMI) to enable efficient smart-malnutrition monitoring. To address these constraints, this study presents a groundbreaking, scalable, and robust smart malnutrition-monitoring system that leverages a single full-body image of an individual to estimate height, weight, and other crucial health parameters within a multi-modal learning framework. Our proposed methodology involves the reconstruction of a highly precise 3D point cloud, from which 512-dimensional feature embeddings are extracted using a headless-3D classification network. Concurrently, facial and body embeddings are also extracted, and through the application of learnable parameters, these features are then utilized to estimate weight accurately. Furthermore, essential health metrics, including BMR, BFP, and BMI, are computed to conduct a comprehensive analysis of the subject's health, subsequently facilitating the provision of personalized nutrition plans. While being robust to a wide range of lighting conditions across multiple devices, our model achieves a low Mean Absolute Error (MAE) of $\pm$ 4.7 cm and $\pm$ 5.3 kg in estimating height and weight.
Gender Bias in Transformer Models: A comprehensive survey
Jun 18, 2023



Gender bias in artificial intelligence (AI) has emerged as a pressing concern with profound implications for individuals' lives. This paper presents a comprehensive survey that explores gender bias in Transformer models from a linguistic perspective. While the existence of gender bias in language models has been acknowledged in previous studies, there remains a lack of consensus on how to effectively measure and evaluate this bias. Our survey critically examines the existing literature on gender bias in Transformers, shedding light on the diverse methodologies and metrics employed to assess bias. Several limitations in current approaches to measuring gender bias in Transformers are identified, encompassing the utilization of incomplete or flawed metrics, inadequate dataset sizes, and a dearth of standardization in evaluation methods. Furthermore, our survey delves into the potential ramifications of gender bias in Transformers for downstream applications, including dialogue systems and machine translation. We underscore the importance of fostering equity and fairness in these systems by emphasizing the need for heightened awareness and accountability in developing and deploying language technologies. This paper serves as a comprehensive overview of gender bias in Transformer models, providing novel insights and offering valuable directions for future research in this critical domain.
Automated Speaker Independent Visual Speech Recognition: A Comprehensive Survey
Jun 14, 2023



Speaker-independent VSR is a complex task that involves identifying spoken words or phrases from video recordings of a speaker's facial movements. Over the years, there has been a considerable amount of research in the field of VSR involving different algorithms and datasets to evaluate system performance. These efforts have resulted in significant progress in developing effective VSR models, creating new opportunities for further research in this area. This survey provides a detailed examination of the progression of VSR over the past three decades, with a particular emphasis on the transition from speaker-dependent to speaker-independent systems. We also provide a comprehensive overview of the various datasets used in VSR research and the preprocessing techniques employed to achieve speaker independence. The survey covers the works published from 1990 to 2023, thoroughly analyzing each work and comparing them on various parameters. This survey provides an in-depth analysis of speaker-independent VSR systems evolution from 1990 to 2023. It outlines the development of VSR systems over time and highlights the need to develop end-to-end pipelines for speaker-independent VSR. The pictorial representation offers a clear and concise overview of the techniques used in speaker-independent VSR, thereby aiding in the comprehension and analysis of the various methodologies. The survey also highlights the strengths and limitations of each technique and provides insights into developing novel approaches for analyzing visual speech cues. Overall, This comprehensive review provides insights into the current state-of-the-art speaker-independent VSR and highlights potential areas for future research.
A Novel end-to-end Framework for Occluded Pixel Reconstruction with Spatio-temporal Features for Improved Person Re-identification
Apr 16, 2023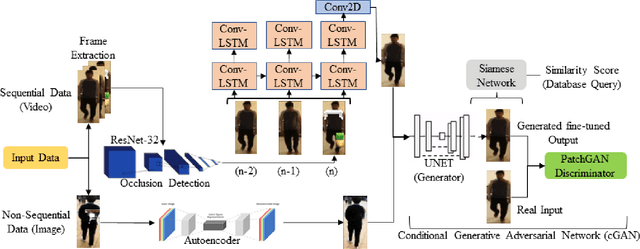

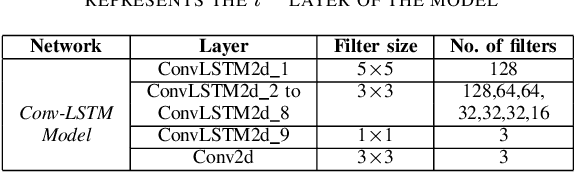
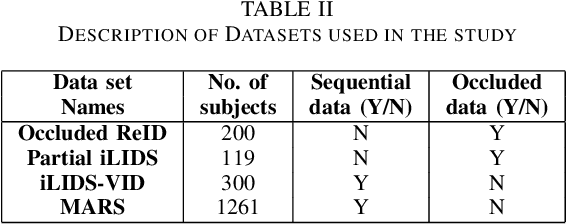
Person re-identification is vital for monitoring and tracking crowd movement to enhance public security. However, re-identification in the presence of occlusion substantially reduces the performance of existing systems and is a challenging area. In this work, we propose a plausible solution to this problem by developing effective occlusion detection and reconstruction framework for RGB images/videos consisting of Deep Neural Networks. Specifically, a CNN-based occlusion detection model classifies individual input frames, followed by a Conv-LSTM and Autoencoder to reconstruct the occluded pixels corresponding to the occluded frames for sequential (video) and non-sequential (image) data, respectively. The quality of the reconstructed RGB frames is further refined and fine-tuned using a Conditional Generative Adversarial Network (cGAN). Our method is evaluated on four well-known public data sets of the domain, and the qualitative reconstruction results are indeed appealing. Quantitative evaluation in terms of re-identification accuracy of the Siamese network showed an exceptional Rank-1 accuracy after occluded pixel reconstruction on various datasets. A comparative analysis with state-of-the-art approaches also demonstrates the robustness of our work for use in real-life surveillance systems.
Medical Image Segmentation using LeViT-UNet++: A Case Study on GI Tract Data
Sep 15, 2022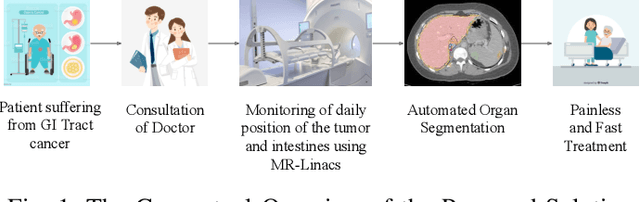
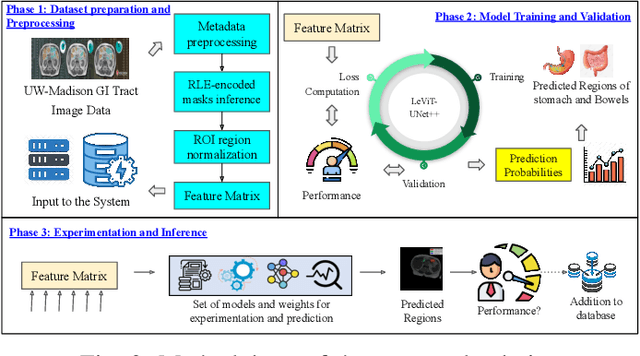
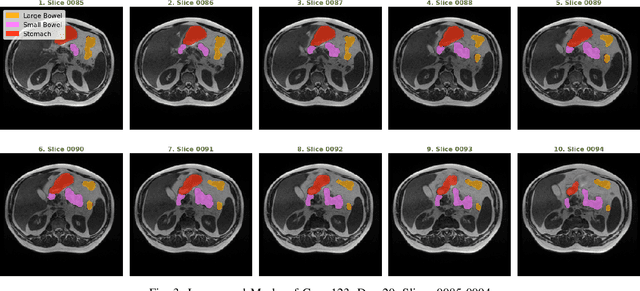
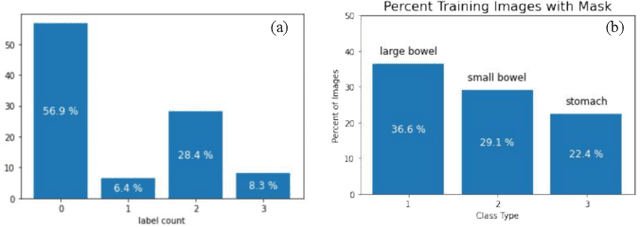
Gastro-Intestinal Tract cancer is considered a fatal malignant condition of the organs in the GI tract. Due to its fatality, there is an urgent need for medical image segmentation techniques to segment organs to reduce the treatment time and enhance the treatment. Traditional segmentation techniques rely upon handcrafted features and are computationally expensive and inefficient. Vision Transformers have gained immense popularity in many image classification and segmentation tasks. To address this problem from a transformers' perspective, we introduced a hybrid CNN-transformer architecture to segment the different organs from an image. The proposed solution is robust, scalable, and computationally efficient, with a Dice and Jaccard coefficient of 0.79 and 0.72, respectively. The proposed solution also depicts the essence of deep learning-based automation to improve the effectiveness of the treatment
A Cognitive Study on Semantic Similarity Analysis of Large Corpora: A Transformer-based Approach
Jul 24, 2022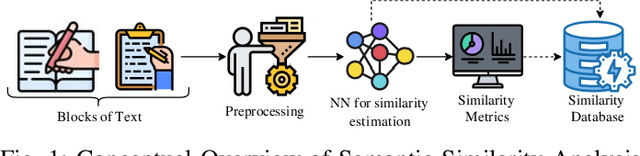

Semantic similarity analysis and modeling is a fundamentally acclaimed task in many pioneering applications of natural language processing today. Owing to the sensation of sequential pattern recognition, many neural networks like RNNs and LSTMs have achieved satisfactory results in semantic similarity modeling. However, these solutions are considered inefficient due to their inability to process information in a non-sequential manner, thus leading to the improper extraction of context. Transformers function as the state-of-the-art architecture due to their advantages like non-sequential data processing and self-attention. In this paper, we perform semantic similarity analysis and modeling on the U.S Patent Phrase to Phrase Matching Dataset using both traditional and transformer-based techniques. We experiment upon four different variants of the Decoding Enhanced BERT - DeBERTa and enhance its performance by performing K-Fold Cross-Validation. The experimental results demonstrate our methodology's enhanced performance compared to traditional techniques, with an average Pearson correlation score of 0.79.