 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender Bias in Transformer Models: A comprehensive survey
Jun 18, 2023



Gender bias in artificial intelligence (AI) has emerged as a pressing concern with profound implications for individuals' lives. This paper presents a comprehensive survey that explores gender bias in Transformer models from a linguistic perspective. While the existence of gender bias in language models has been acknowledged in previous studies, there remains a lack of consensus on how to effectively measure and evaluate this bias. Our survey critically examines the existing literature on gender bias in Transformers, shedding light on the diverse methodologies and metrics employed to assess bias. Several limitations in current approaches to measuring gender bias in Transformers are identified, encompassing the utilization of incomplete or flawed metrics, inadequate dataset sizes, and a dearth of standardization in evaluation methods. Furthermore, our survey delves into the potential ramifications of gender bias in Transformers for downstream applications, including dialogue systems and machine translation. We underscore the importance of fostering equity and fairness in these systems by emphasizing the need for heightened awareness and accountability in developing and deploying language technologies. This paper serves as a comprehensive overview of gender bias in Transformer models, providing novel insights and offering valuable directions for future research in this critical domain.
Event Causality Identification with Causal News Corpus -- Shared Task 3, CASE 2022
Nov 22, 2022



The Event Causality Identification Shared Task of CASE 2022 involved two subtasks working on the Causal News Corpus. Subtask 1 required participants to predict if a sentence contains a causal relation or not. This is a supervised binary classification task. Subtask 2 required participants to identify the Cause, Effect and Signal spans per causal sentence. This could be seen as a supervised sequence labeling task. For both subtasks, participants uploaded their predictions for a held-out test set, and ranking was done based on binary F1 and macro F1 scores for Subtask 1 and 2, respectively. This paper summarizes the work of the 17 teams that submitted their results to our competition and 12 system description papers that were received. The best F1 scores achieved for Subtask 1 and 2 were 86.19% and 54.15%, respectively. All the top-performing approaches involved pre-trained language models fine-tuned to the targeted task. We further discuss these approaches and analyze errors across participants' systems in this paper.
The Causal News Corpus: Annotating Causal Relations in Event Sentences from News
Apr 25, 2022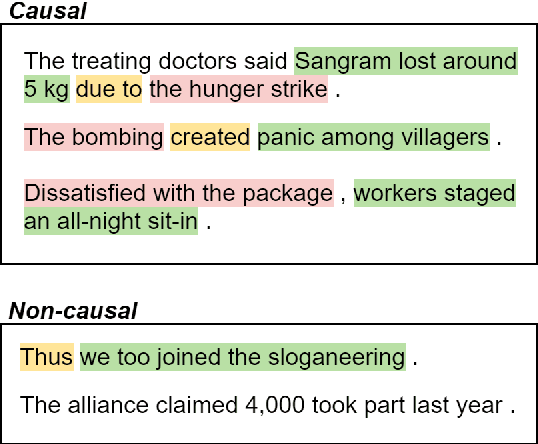
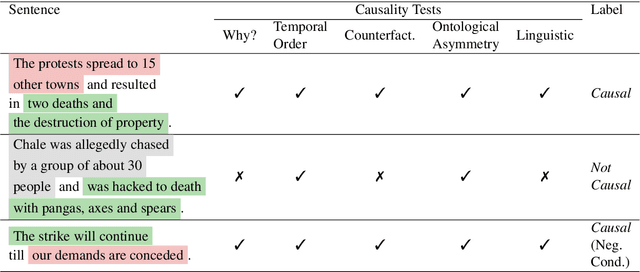
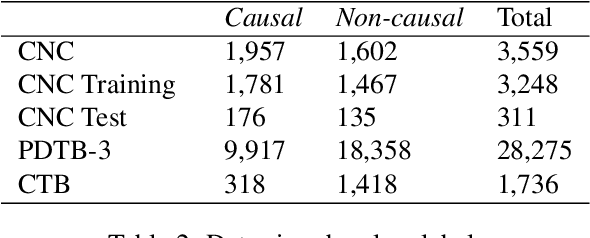
Despite the importance of understanding causality, corpora addressing causal relations are limited. There is a discrepancy between existing annotation guidelines of event causality and conventional causality corpora that focus more on linguistics. Many guidelines restrict themselves to include only explicit relations or clause-based arguments. Therefore, we propose an annotation schema for event causality that addresses these concerns. We annotated 3,559 event sentences from protest event news with labels on whether it contains causal relations or not. Our corpus is known as the Causal News Corpus (CNC). A neural network built upon a state-of-the-art pre-trained language model performed well with 81.20% F1 score on test set, and 83.46% in 5-folds cross-validation. CNC is transferable across two external corpora: CausalTimeBank (CTB) and Penn Discourse Treebank (PDTB). Leveraging each of these external datasets for training, we achieved up to approximately 64% F1 on the CNC test set without additional fine-tuning. CNC also served as an effective training and pre-training dataset for the two external corpora. Lastly, we demonstrate the difficulty of our task to the layman in a crowd-sourced annotation exercise. Our annotated corpus is publicly available, providing a valuable resource for causal text mining researchers.
Semantic Journeys: Quantifying Change in Emoji Meaning from 2012-2018
May 04, 2021



The semantics of emoji has, to date, been considered from a static perspective. We offer the first longitudinal study of how emoji semantics changes over time, applying techniques from computational linguistics to six years of Twitter data. We identify five patterns in emoji semantic development and find evidence that the less abstract an emoji is, the more likely it is to undergo semantic change. In addition, we analyse select emoji in more detail, examining the effect of seasonality and world events on emoji semantics. To aid future work on emoji and semantics, we make our data publicly available along with a web-based interface that anyone can use to explore semantic change in emoji.
Improving Language Modelling with Noise-contrastive estimation
Sep 22, 2017
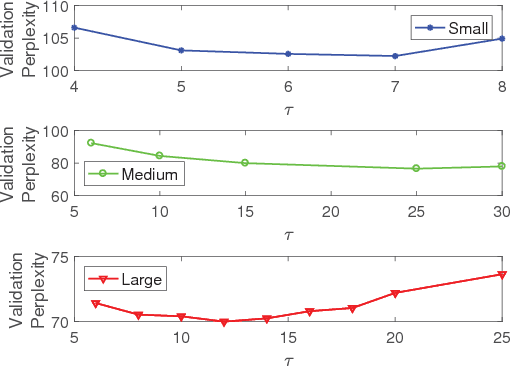

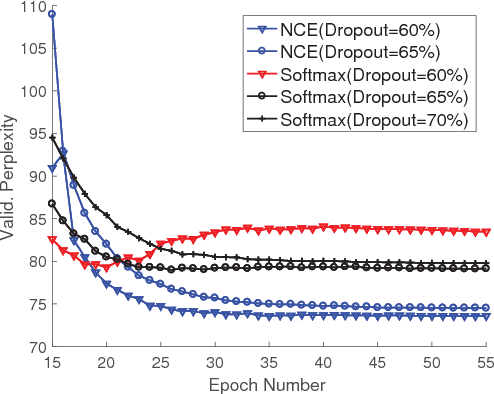
Neural language models do not scale well when the vocabulary is large. Noise-contrastive estimation (NCE) is a sampling-based method that allows for fast learning with large vocabularies. Although NCE has shown promising performance in neural machine translation, it was considered to be an unsuccessful approach for language modelling. A sufficient investigation of the hyperparameters in the NCE-based neural language models was also missing. In this paper, we showed that NCE can be a successful approach in neural language modelling when the hyperparameters of a neural network are tuned appropriately. We introduced the 'search-then-converge' learning rate schedule for NCE and designed a heuristic that specifies how to use this schedule. The impact of the other important hyperparameters, such as the dropout rate and the weight initialisation range, was also demonstrated. We showed that appropriate tuning of NCE-based neural language models outperforms the state-of-the-art single-model methods on a popular benchmark.