 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Clinical Entity Recognition using ChatGPT
Mar 29, 2023



In this study, we investigated the potential of ChatGPT, a large language model developed by OpenAI, for the clinical named entity recognition task defined in the 2010 i2b2 challenge, in a zero-shot setting with two different prompt strategies. We compared its performance with GPT-3 in a similar zero-shot setting, as well as a fine-tuned BioClinicalBERT model using a set of synthetic clinical notes from MTSamples. Our findings revealed that ChatGPT outperformed GPT-3 in the zero-shot setting, with F1 scores of 0.418 (vs.0.250) and 0.620 (vs. 0.480) for exact- and relaxed-matching, respectively. Moreover, prompts affected ChatGPT's performance greatly, with relaxed-matching F1 scores of 0.628 vs.0.541 for two different prompt strategies. Although ChatGPT's performance was still lower than that of the supervised BioClinicalBERT model (i.e., relaxed-matching F1 scores of 0.628 vs. 0.870), our study demonstrates the great potential of ChatGPT for clinical NER tasks in a zero-shot setting, which is much more appealing as it does not require any annotation.
Job Offers Classifier using Neural Networks and Oversampling Methods
Jul 03, 2022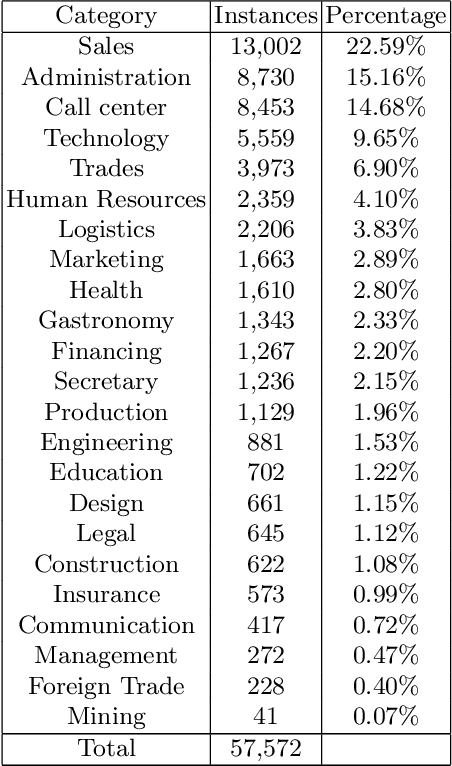
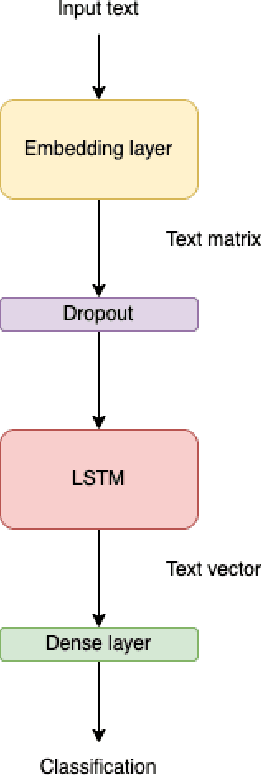
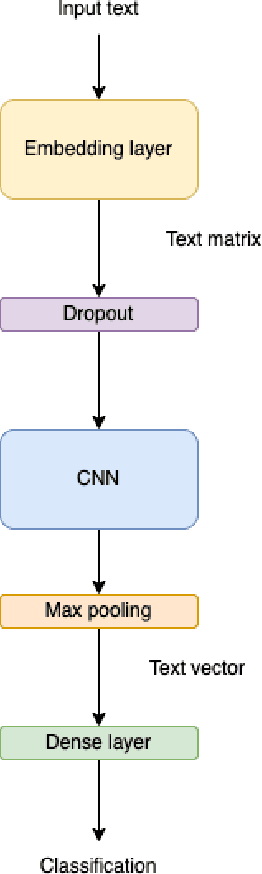
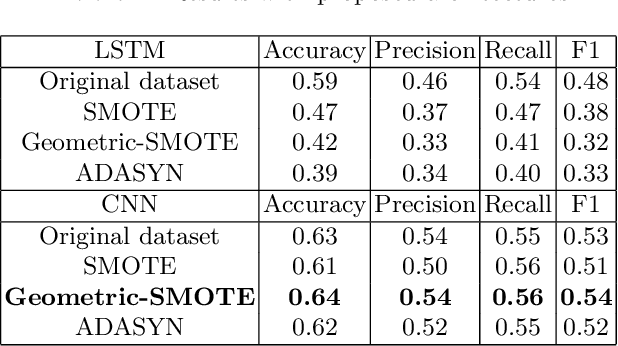
Both policy and research benefit from a better understanding of individuals' jobs. However, as large-scale administrative records are increasingly employed to represent labor market activity, new automatic methods to classify jobs will become necessary. We developed an automatic job offers classifier using a dataset collected from the largest job bank of Mexico known as Bumeran https://www.bumeran.com.mx/ Last visited: 19-01-2022.. We applied machine learning algorithms such as Support Vector Machines, Naive-Bayes, Logistic Regression, Random Forest, and deep learning Long-Short Term Memory (LSTM). Using these algorithms, we trained multi-class models to classify job offers in one of the 23 classes (not uniformly distributed): Sales, Administration, Call Center, Technology, Trades, Human Resources, Logistics, Marketing, Health, Gastronomy, Financing, Secretary, Production, Engineering, Education, Design, Legal, Construction, Insurance, Communication, Management, Foreign Trade, and Mining. We used the SMOTE, Geometric-SMOTE, and ADASYN synthetic oversampling algorithms to handle imbalanced classes. The proposed convolutional neural network architecture achieved the best results when applied the Geometric-SMOTE algorithm.
Mental Illness Classification on Social Media Texts using Deep Learning and Transfer Learning
Jul 03, 2022
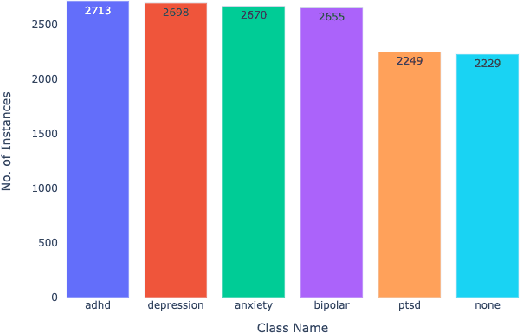
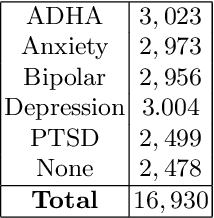
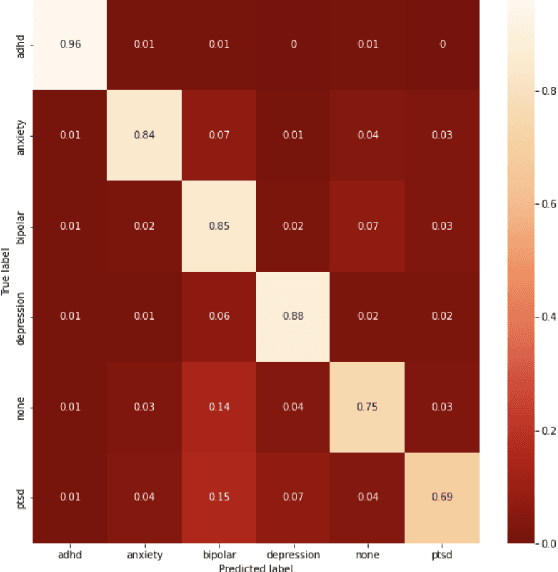
Given the current social distance restrictions across the world, most individuals now use social media as their major medium of communication. Millions of people suffering from mental diseases have been isolated due to this, and they are unable to get help in person. They have become more reliant on online venues to express themselves and seek advice on dealing with their mental disorders. According to the World health organization (WHO), approximately 450 million people are affected. Mental illnesses, such as depression, anxiety, etc., are immensely common and have affected an individuals' physical health. Recently Artificial Intelligence (AI) methods have been presented to help mental health providers, including psychiatrists and psychologists, in decision making based on patients' authentic information (e.g., medical records, behavioral data, social media utilization, etc.). AI innovations have demonstrated predominant execution in numerous real-world applications broadening from computer vision to healthcare. This study analyzes unstructured user data on the Reddit platform and classifies five common mental illnesses: depression, anxiety, bipolar disorder, ADHD, and PTSD. We trained traditional machine learning, deep learning, and transfer learning multi-class models to detect mental disorders of individuals. This effort will benefit the public health system by automating the detection process and informing appropriate authorities about people who require emergency assistance.
The Causal News Corpus: Annotating Causal Relations in Event Sentences from News
Apr 25, 2022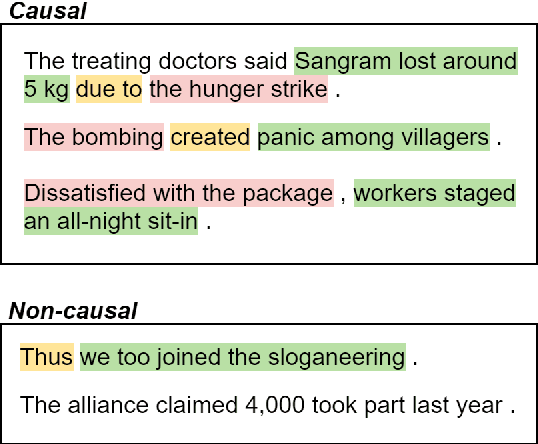
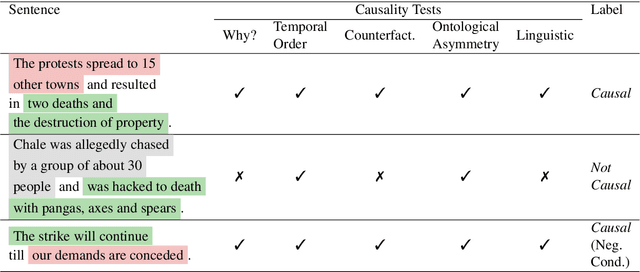
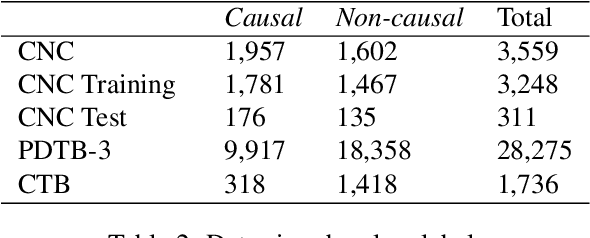
Despite the importance of understanding causality, corpora addressing causal relations are limited. There is a discrepancy between existing annotation guidelines of event causality and conventional causality corpora that focus more on linguistics. Many guidelines restrict themselves to include only explicit relations or clause-based arguments. Therefore, we propose an annotation schema for event causality that addresses these concerns. We annotated 3,559 event sentences from protest event news with labels on whether it contains causal relations or not. Our corpus is known as the Causal News Corpus (CNC). A neural network built upon a state-of-the-art pre-trained language model performed well with 81.20% F1 score on test set, and 83.46% in 5-folds cross-validation. CNC is transferable across two external corpora: CausalTimeBank (CTB) and Penn Discourse Treebank (PDTB). Leveraging each of these external datasets for training, we achieved up to approximately 64% F1 on the CNC test set without additional fine-tuning. CNC also served as an effective training and pre-training dataset for the two external corpora. Lastly, we demonstrate the difficulty of our task to the layman in a crowd-sourced annotation exercise. Our annotated corpus is publicly available, providing a valuable resource for causal text mining researchers.