 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDU-NER-2025: Named Entity Recognition in Urdu Educational Texts using XLM-RoBERTa with X (formerly Twitter)
Apr 25, 2025Named Entity Recognition (NER) plays a pivotal role in various Natural Language Processing (NLP) tasks by identifying and classifying named entities (NEs) from unstructured data into predefined categories such as person, organization, location, date, and time. While extensive research exists for high-resource languages and general domains, NER in Urdu particularly within domain-specific contexts like education remains significantly underexplored. This is Due to lack of annotated datasets for educational content which limits the ability of existing models to accurately identify entities such as academic roles, course names, and institutional terms, underscoring the urgent need for targeted resources in this domain. To the best of our knowledge, no dataset exists in the domain of the Urdu language for this purpose. To achieve this objective this study makes three key contributions. Firstly, we created a manually annotated dataset in the education domain, named EDU-NER-2025, which contains 13 unique most important entities related to education domain. Second, we describe our annotation process and guidelines in detail and discuss the challenges of labelling EDU-NER-2025 dataset. Third, we addressed and analyzed key linguistic challenges, such as morphological complexity and ambiguity, which are prevalent in formal Urdu texts.
Synthetic Time Series Data Generation for Healthcare Applications: A PCG Case Study
Dec 17, 2024


The generation of high-quality medical time series data is essential for advancing healthcare diagnostics and safeguarding patient privacy. Specifically, synthesizing realistic phonocardiogram (PCG) signals offers significant potential as a cost-effective and efficient tool for cardiac disease pre-screening. Despite its potential, the synthesis of PCG signals for this specific application received limited attention in research. In this study, we employ and compare three state-of-the-art generative models from different categories - WaveNet, DoppelGANger, and DiffWave - to generate high-quality PCG data. We use data from the George B. Moody PhysioNet Challenge 2022. Our methods are evaluated using various metrics widely used in the previous literature in the domain of time series data generation, such as mean absolute error and maximum mean discrepancy. Our results demonstrate that the generated PCG data closely resembles the original datasets, indicating the effectiveness of our generative models in producing realistic synthetic PCG data. In our future work, we plan to incorporate this method into a data augmentation pipeline to synthesize abnormal PCG signals with heart murmurs, in order to address the current scarcity of abnormal data. We hope to improve the robustness and accuracy of diagnostic tools in cardiology, enhancing their effectiveness in detecting heart murmurs.
Mental Illness Classification on Social Media Texts using Deep Learning and Transfer Learning
Jul 03, 2022
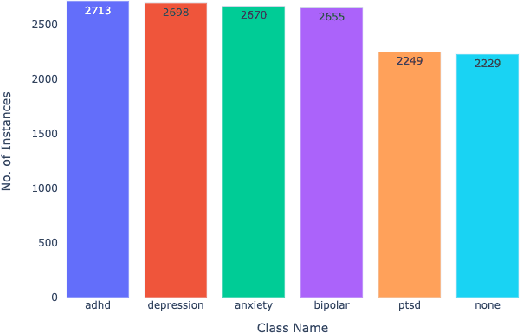
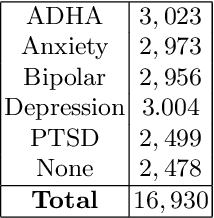
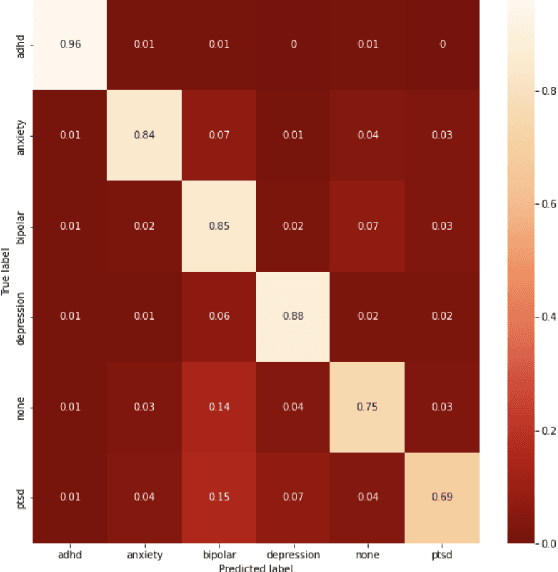
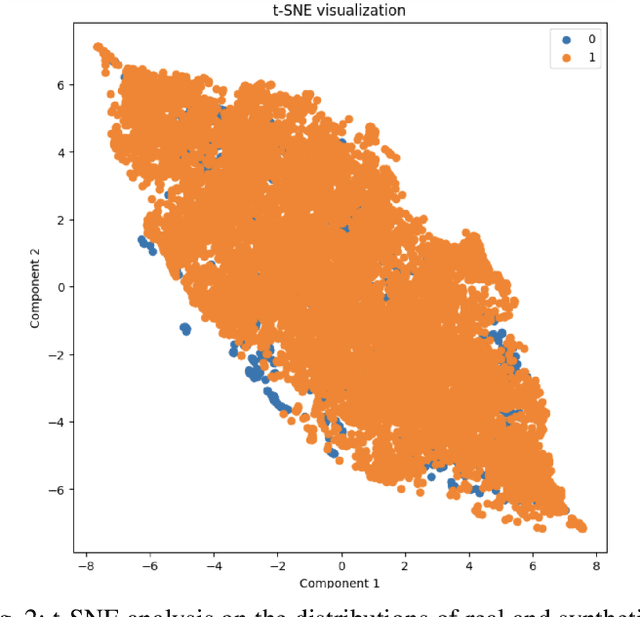
Given the current social distance restrictions across the world, most individuals now use social media as their major medium of communication. Millions of people suffering from mental diseases have been isolated due to this, and they are unable to get help in person. They have become more reliant on online venues to express themselves and seek advice on dealing with their mental disorders. According to the World health organization (WHO), approximately 450 million people are affected. Mental illnesses, such as depression, anxiety, etc., are immensely common and have affected an individuals' physical health. Recently Artificial Intelligence (AI) methods have been presented to help mental health providers, including psychiatrists and psychologists, in decision making based on patients' authentic information (e.g., medical records, behavioral data, social media utilization, etc.). AI innovations have demonstrated predominant execution in numerous real-world applications broadening from computer vision to healthcare. This study analyzes unstructured user data on the Reddit platform and classifies five common mental illnesses: depression, anxiety, bipolar disorder, ADHD, and PTSD. We trained traditional machine learning, deep learning, and transfer learning multi-class models to detect mental disorders of individuals. This effort will benefit the public health system by automating the detection process and informing appropriate authorities about people who require emergency assistance.
Scene Recognition by Combining Local and Global Image Descriptors
Feb 21, 2017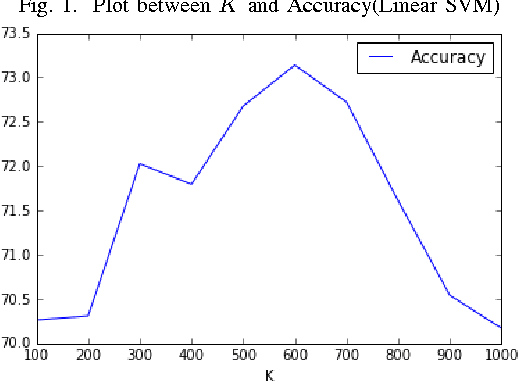
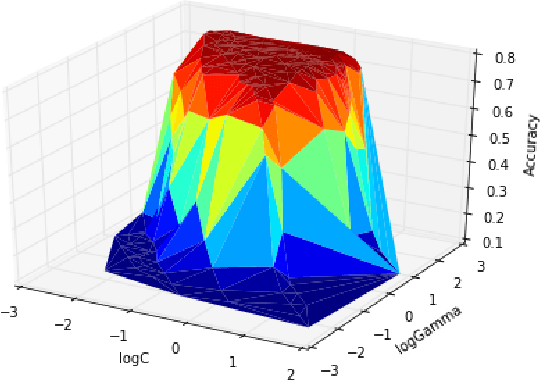
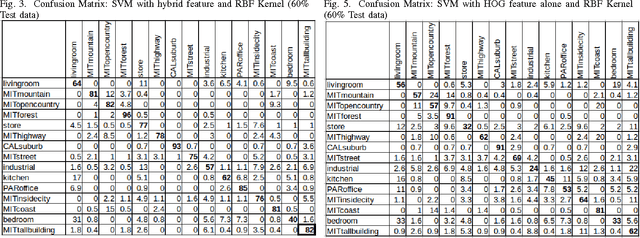
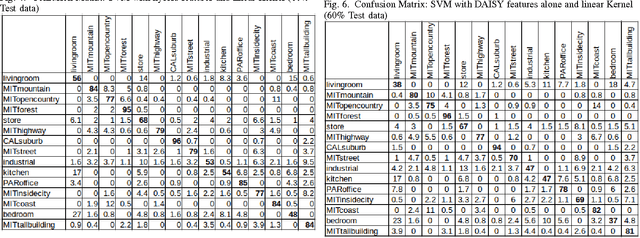
Object recognition is an important problem in computer vision, having diverse applications. In this work, we construct an end-to-end scene recognition pipeline consisting of feature extraction, encoding, pooling and classification. Our approach simultaneously utilize global feature descriptors as well as local feature descriptors from images, to form a hybrid feature descriptor corresponding to each image. We utilize DAISY features associated with key points within images as our local feature descriptor and histogram of oriented gradients (HOG) corresponding to an entire image as a global descriptor. We make use of a bag-of-visual-words encoding and apply Mini- Batch K-Means algorithm to reduce the complexity of our feature encoding scheme. A 2-level pooling procedure is used to combine DAISY and HOG features corresponding to each image. Finally, we experiment with a multi-class SVM classifier with several kernels, in a cross-validation setting, and tabulate our results on the fifteen scene categories dataset. The average accuracy of our model was 76.4% in the case of a 40%-60% random split of images into training and testing datasets respectively. The primary objective of this work is to clearly outline the practical implementation of a basic screne-recognition pipeline having a reasonable accuracy, in python, using open-source libraries. A full implementation of the proposed model is available in our github repository.
Ranking academic institutions on potential paper acceptance in upcoming conferences
Oct 10, 2016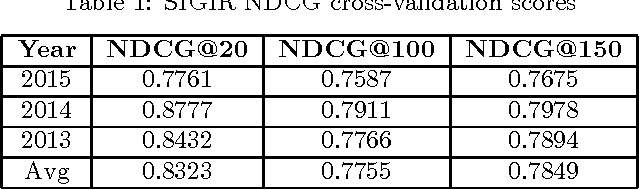
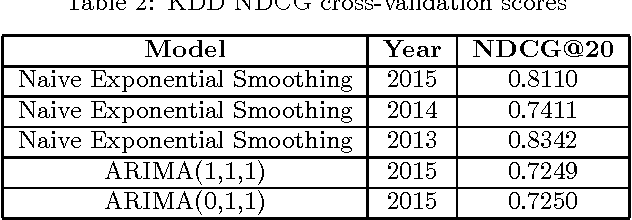
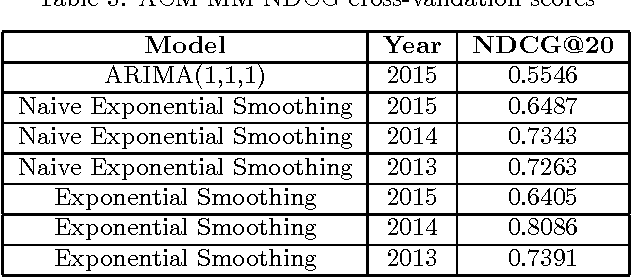
The crux of the problem in KDD Cup 2016 involves developing data mining techniques to rank research institutions based on publications. Rank importance of research institutions are derived from predictions on the number of full research papers that would potentially get accepted in upcoming top-tier conferences, utilizing public information on the web. This paper describes our solution to KDD Cup 2016. We used a two step approach in which we first identify full research papers corresponding to each conference of interest and then train two variants of exponential smoothing models to make predictions. Our solution achieves an overall score of 0.7508, while the winning submission scored 0.7656 in the overall results.