Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking academic institutions on potential paper acceptance in upcoming conferences
Paper and Code
Oct 10, 2016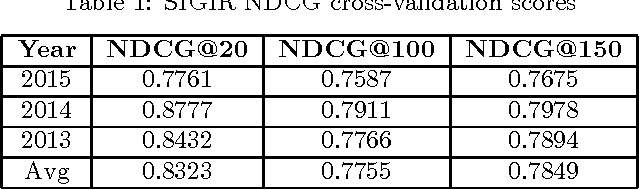
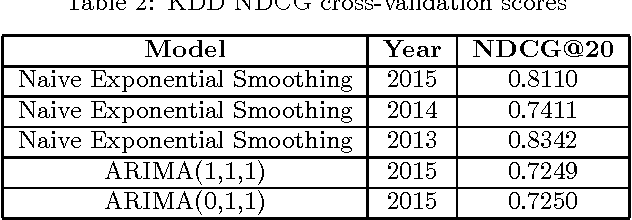
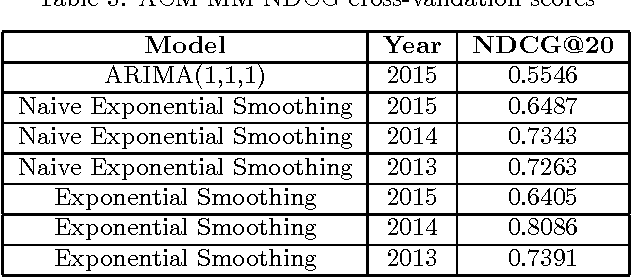
The crux of the problem in KDD Cup 2016 involves developing data mining techniques to rank research institutions based on publications. Rank importance of research institutions are derived from predictions on the number of full research papers that would potentially get accepted in upcoming top-tier conferences, utilizing public information on the web. This paper describes our solution to KDD Cup 2016. We used a two step approach in which we first identify full research papers corresponding to each conference of interest and then train two variants of exponential smoothing models to make predictions. Our solution achieves an overall score of 0.7508, while the winning submission scored 0.7656 in the overall results.
* KDD 2016, KDD Cup 2016, Appeared in the KDD Cup Workshop
2016,https://kddcup2016.azurewebsites.net/Workshop
View paper on