 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Detection and Root-Cause Analysis of Flaky Tests in Quantum Software
Mar 09, 2026Like classical software, quantum software systems rely on automated testing. However, their inherently probabilistic outputs make them susceptible to quantum flakiness -- tests that pass or fail inconsistently without code changes. Such quantum flaky tests can mask real defects and reduce developer productivity, yet systematic tooling for their detection and diagnosis remains limited. This paper presents an automated pipeline to detect flaky-test-related issues and pull requests in quantum software repositories and to support the identification of their root causes. We aim to expand an existing quantum flaky test dataset and evaluate the capability of Large Language Models (LLMs) for flakiness classification and root-cause identification. Building on a prior manual analysis of 14 quantum software repositories, we automate the discovery of additional flaky test cases using LLMs and cosine similarity. We further evaluate a variety of LLMs from OpenAI GPT, Meta LLaMA, Google Gemini, and Anthropic Claude suites for classifying flakiness and identifying root causes from issue descriptions and code context. Classification performance is assessed using standard performance metrics, including F1-score. Using our pipeline, we identify 25 previously unknown flaky tests, increasing the original dataset size by 54%. The best-performing model, Google Gemini, achieves an F1-score of 0.9420 for flakiness detection and 0.9643 for root-cause identification, demonstrating that LLMs can provide practical support for triaging flaky reports and understanding their underlying causes in quantum software. The expanded dataset and automated pipeline provide reusable artifacts for the quantum software engineering community. Future work will focus on improving detection robustness and exploring automated repair of quantum flaky tests.
Identifying Flaky Tests in Quantum Code: A Machine Learning Approach
Feb 06, 2025Testing and debugging quantum software pose significant challenges due to the inherent complexities of quantum mechanics, such as superposition and entanglement. One challenge is indeterminacy, a fundamental characteristic of quantum systems, which increases the likelihood of flaky tests in quantum programs. To the best of our knowledge, there is a lack of comprehensive studies on quantum flakiness in the existing literature. In this paper, we present a novel machine learning platform that leverages multiple machine learning models to automatically detect flaky tests in quantum programs. Our evaluation shows that the extreme gradient boosting and decision tree-based models outperform other models (i.e., random forest, k-nearest neighbors, and support vector machine), achieving the highest F1 score and Matthews Correlation Coefficient in a balanced dataset and an imbalanced dataset, respectively. Furthermore, we expand the currently limited dataset for researchers interested in quantum flaky tests. In the future, we plan to explore the development of unsupervised learning techniques to detect and classify quantum flaky tests more effectively. These advancements aim to improve the reliability and robustness of quantum software testing.
Synthetic Time Series Data Generation for Healthcare Applications: A PCG Case Study
Dec 17, 2024
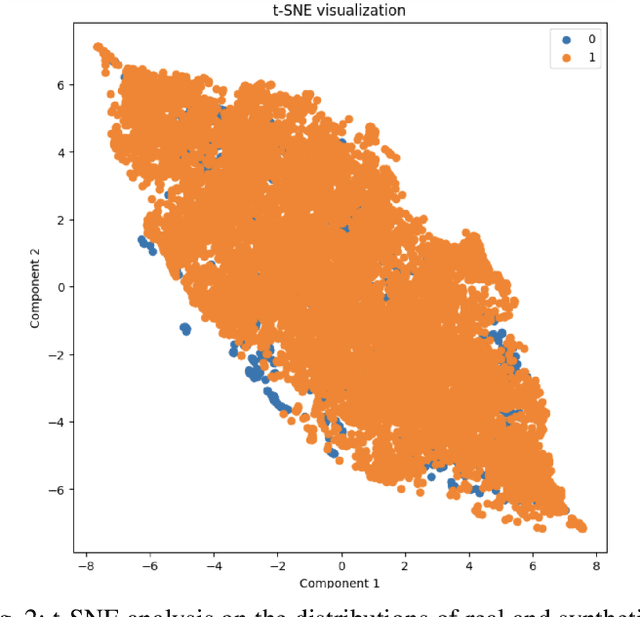


The generation of high-quality medical time series data is essential for advancing healthcare diagnostics and safeguarding patient privacy. Specifically, synthesizing realistic phonocardiogram (PCG) signals offers significant potential as a cost-effective and efficient tool for cardiac disease pre-screening. Despite its potential, the synthesis of PCG signals for this specific application received limited attention in research. In this study, we employ and compare three state-of-the-art generative models from different categories - WaveNet, DoppelGANger, and DiffWave - to generate high-quality PCG data. We use data from the George B. Moody PhysioNet Challenge 2022. Our methods are evaluated using various metrics widely used in the previous literature in the domain of time series data generation, such as mean absolute error and maximum mean discrepancy. Our results demonstrate that the generated PCG data closely resembles the original datasets, indicating the effectiveness of our generative models in producing realistic synthetic PCG data. In our future work, we plan to incorporate this method into a data augmentation pipeline to synthesize abnormal PCG signals with heart murmurs, in order to address the current scarcity of abnormal data. We hope to improve the robustness and accuracy of diagnostic tools in cardiology, enhancing their effectiveness in detecting heart murmurs.
Automating Quantum Software Maintenance: Flakiness Detection and Root Cause Analysis
Oct 31, 2024Flaky tests, which pass or fail inconsistently without code changes, are a major challenge in software engineering in general and in quantum software engineering in particular due to their complexity and probabilistic nature, leading to hidden issues and wasted developer effort. We aim to create an automated framework to detect flaky tests in quantum software and an extended dataset of quantum flaky tests, overcoming the limitations of manual methods. Building on prior manual analysis of 14 quantum software repositories, we expanded the dataset and automated flaky test detection using transformers and cosine similarity. We conducted experiments with Large Language Models (LLMs) from the OpenAI GPT and Meta LLaMA families to assess their ability to detect and classify flaky tests from code and issue descriptions. Embedding transformers proved effective: we identified 25 new flaky tests, expanding the dataset by 54%. Top LLMs achieved an F1-score of 0.8871 for flakiness detection but only 0.5839 for root cause identification. We introduced an automated flaky test detection framework using machine learning, showing promising results but highlighting the need for improved root cause detection and classification in large quantum codebases. Future work will focus on improving detection techniques and developing automatic flaky test fixes.