 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Collapses When AI Pollutes the Web
Feb 18, 2026The rapid proliferation of AI-generated content on the Web presents a structural risk to information retrieval, as search engines and Retrieval-Augmented Generation (RAG) systems increasingly consume evidence produced by the Large Language Models (LLMs). We characterize this ecosystem-level failure mode as Retrieval Collapse, a two-stage process where (1) AI-generated content dominates search results, eroding source diversity, and (2) low-quality or adversarial content infiltrates the retrieval pipeline. We analyzed this dynamic through controlled experiments involving both high-quality SEO-style content and adversarially crafted content. In the SEO scenario, a 67\% pool contamination led to over 80\% exposure contamination, creating a homogenized yet deceptively healthy state where answer accuracy remains stable despite the reliance on synthetic sources. Conversely, under adversarial contamination, baselines like BM25 exposed $\sim$19\% of harmful content, whereas LLM-based rankers demonstrated stronger suppression capabilities. These findings highlight the risk of retrieval pipelines quietly shifting toward synthetic evidence and the need for retrieval-aware strategies to prevent a self-reinforcing cycle of quality decline in Web-grounded systems.
Do Not Mimic My Voice: Speaker Identity Unlearning for Zero-Shot Text-to-Speech
Jul 27, 2025The rapid advancement of Zero-Shot Text-to-Speech (ZS-TTS) technology has enabled high-fidelity voice synthesis from minimal audio cues, raising significant privacy and ethical concerns. Despite the threats to voice privacy, research to selectively remove the knowledge to replicate unwanted individual voices from pre-trained model parameters has not been explored. In this paper, we address the new challenge of speaker identity unlearning for ZS-TTS systems. To meet this goal, we propose the first machine unlearning frameworks for ZS-TTS, especially Teacher-Guided Unlearning (TGU), designed to ensure the model forgets designated speaker identities while retaining its ability to generate accurate speech for other speakers. Our proposed methods incorporate randomness to prevent consistent replication of forget speakers' voices, assuring unlearned identities remain untraceable. Additionally, we propose a new evaluation metric, speaker-Zero Retrain Forgetting (spk-ZRF). This assesses the model's ability to disregard prompts associated with forgotten speakers, effectively neutralizing its knowledge of these voices. The experiments conducted on the state-of-the-art model demonstrate that TGU prevents the model from replicating forget speakers' voices while maintaining high quality for other speakers. The demo is available at https://speechunlearn.github.io/
Identifying Flaky Tests in Quantum Code: A Machine Learning Approach
Feb 06, 2025Testing and debugging quantum software pose significant challenges due to the inherent complexities of quantum mechanics, such as superposition and entanglement. One challenge is indeterminacy, a fundamental characteristic of quantum systems, which increases the likelihood of flaky tests in quantum programs. To the best of our knowledge, there is a lack of comprehensive studies on quantum flakiness in the existing literature. In this paper, we present a novel machine learning platform that leverages multiple machine learning models to automatically detect flaky tests in quantum programs. Our evaluation shows that the extreme gradient boosting and decision tree-based models outperform other models (i.e., random forest, k-nearest neighbors, and support vector machine), achieving the highest F1 score and Matthews Correlation Coefficient in a balanced dataset and an imbalanced dataset, respectively. Furthermore, we expand the currently limited dataset for researchers interested in quantum flaky tests. In the future, we plan to explore the development of unsupervised learning techniques to detect and classify quantum flaky tests more effectively. These advancements aim to improve the reliability and robustness of quantum software testing.
CUE-M: Contextual Understanding and Enhanced Search with Multimodal Large Language Model
Nov 19, 2024
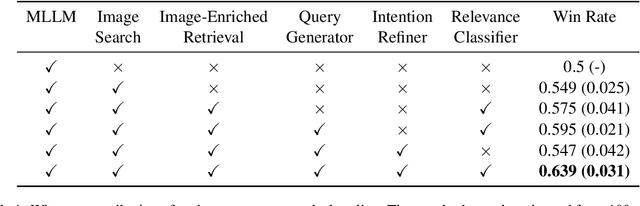
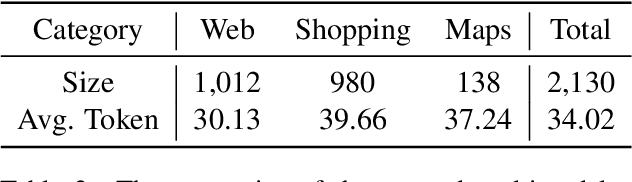
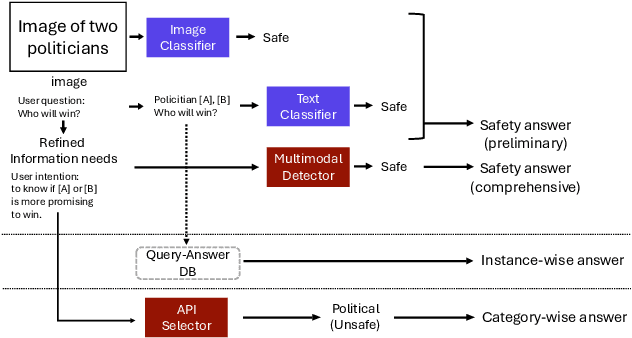
The integration of Retrieval-Augmented Generation (RAG) with Multimodal Large Language Models (MLLMs) has expanded the scope of multimodal query resolution. However, current systems struggle with intent understanding, information retrieval, and safety filtering, limiting their effectiveness. This paper introduces Contextual Understanding and Enhanced Search with MLLM (CUE-M), a novel multimodal search pipeline that addresses these challenges through a multi-stage framework comprising image context enrichment, intent refinement, contextual query generation, external API integration, and relevance-based filtering. CUE-M incorporates a robust safety framework combining image-based, text-based, and multimodal classifiers, dynamically adapting to instance- and category-specific risks. Evaluations on a multimodal Q&A dataset and a public safety benchmark demonstrate that CUE-M outperforms baselines in accuracy, knowledge integration, and safety, advancing the capabilities of multimodal retrieval systems.
Neural Motion Planning for Autonomous Parking
Nov 16, 2021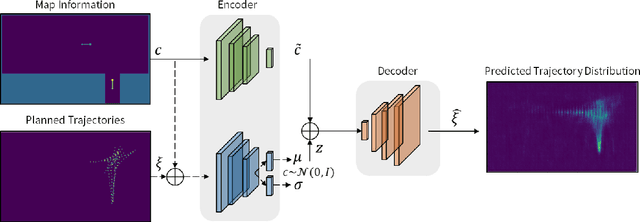
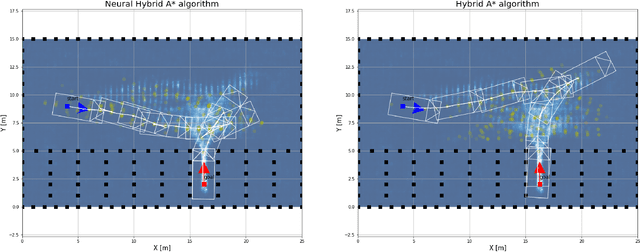
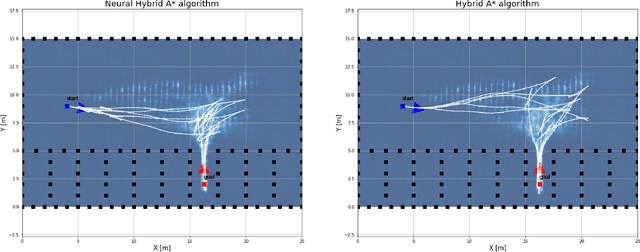
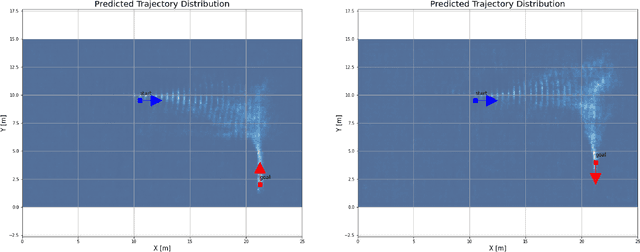
This paper presents a hybrid motion planning strategy that combines a deep generative network with a conventional motion planning method. Existing planning methods such as A* and Hybrid A* are widely used in path planning tasks because of their ability to determine feasible paths even in complex environments; however, they have limitations in terms of efficiency. To overcome these limitations, a path planning algorithm based on a neural network, namely the neural Hybrid A*, is introduced. This paper proposes using a conditional variational autoencoder (CVAE) to guide the search algorithm by exploiting the ability of CVAE to learn information about the planning space given the information of the parking environment. A non-uniform expansion strategy is utilized based on a distribution of feasible trajectories learned in the demonstrations. The proposed method effectively learns the representations of a given state, and shows improvement in terms of algorithm performance.
Multi-Head Attention based Probabilistic Vehicle Trajectory Prediction
Apr 20, 2020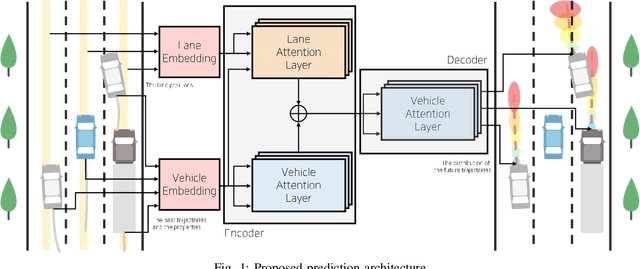
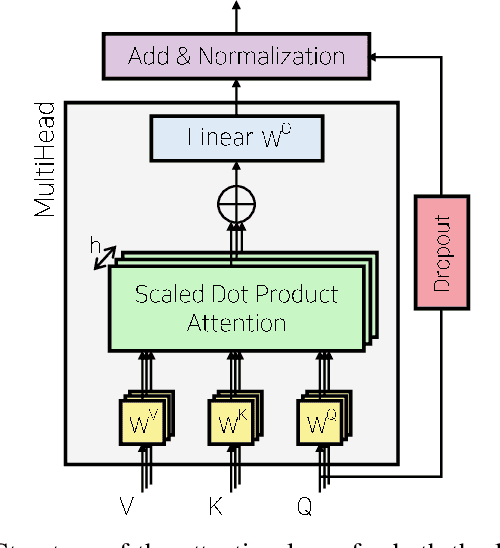

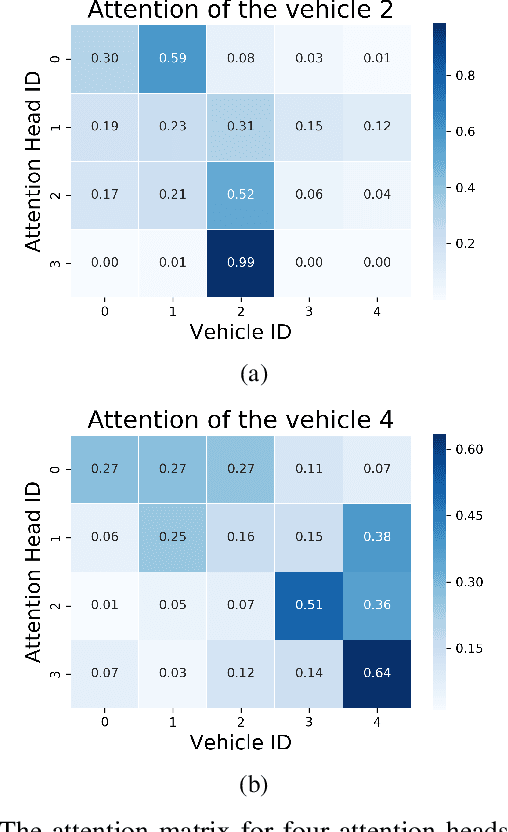
This paper presents online-capable deep learning model for probabilistic vehicle trajectory prediction. We propose a simple encoder-decoder architecture based on multi-head attention. The proposed model generates the distribution of the predicted trajectories for multiple vehicles in parallel. Our approach to model the interactions can learn to attend to a few influential vehicles in an unsupervised manner, which can improve the interpretability of the network. The experiments using naturalistic trajectories at highway show the clear improvement in terms of positional error on both longitudinal and lateral direction.
Coupled Representation Learning for Domains, Intents and Slots in Spoken Language Understanding
Dec 13, 2018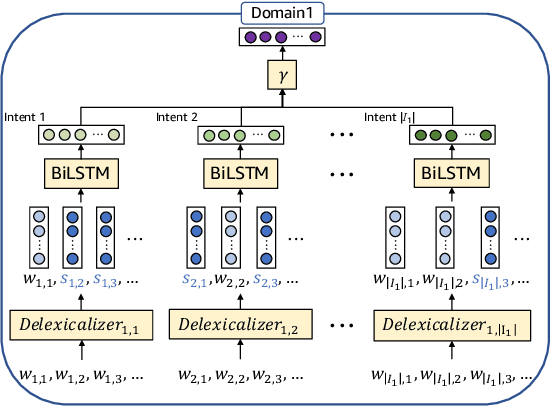
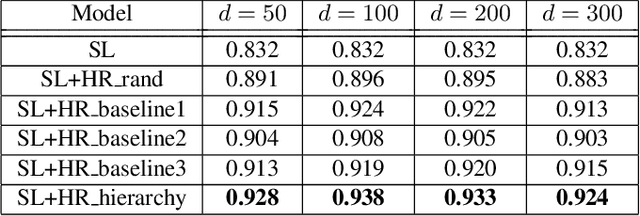
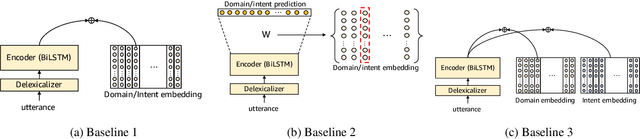
Representation learning is an essential problem in a wide range of applications and it is important for performing downstream tasks successfully. In this paper, we propose a new model that learns coupled representations of domains, intents, and slots by taking advantage of their hierarchical dependency in a Spoken Language Understanding system. Our proposed model learns the vector representation of intents based on the slots tied to these intents by aggregating the representations of the slots. Similarly, the vector representation of a domain is learned by aggregating the representations of the intents tied to a specific domain. To the best of our knowledge, it is the first approach to jointly learning the representations of domains, intents, and slots using their hierarchical relationships. The experimental results demonstrate the effectiveness of the representations learned by our model, as evidenced by improved performance on the contextual cross-domain reranking task.
Efficient Large-Scale Domain Classification with Personalized Attention
Apr 22, 2018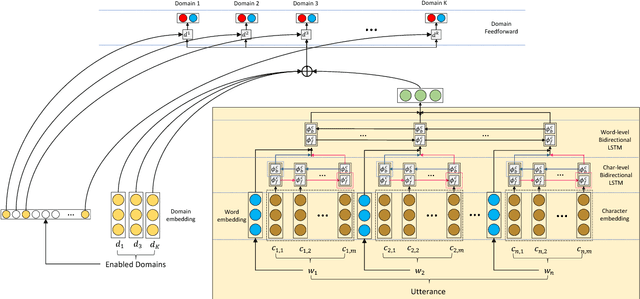
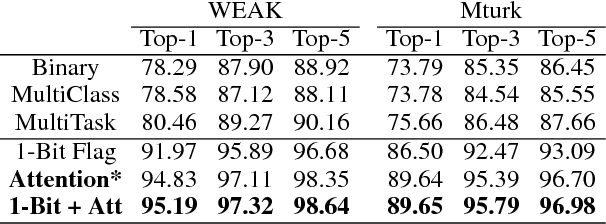
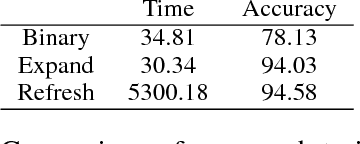
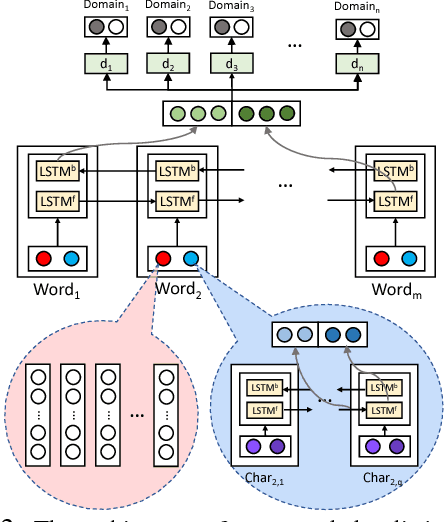
In this paper, we explore the task of mapping spoken language utterances to one of thousands of natural language understanding domains in intelligent personal digital assistants (IPDAs). This scenario is observed for many mainstream IPDAs in industry that allow third parties to develop thousands of new domains to augment built-in ones to rapidly increase domain coverage and overall IPDA capabilities. We propose a scalable neural model architecture with a shared encoder, a novel attention mechanism that incorporates personalization information and domain-specific classifiers that solves the problem efficiently. Our architecture is designed to efficiently accommodate new domains that appear in-between full model retraining cycles with a rapid bootstrapping mechanism two orders of magnitude faster than retraining. We account for practical constraints in real-time production systems, and design to minimize memory footprint and runtime latency. We demonstrate that incorporating personalization results in significantly more accurate domain classification in the setting with thousands of overlapping domains.
A Scalable Neural Shortlisting-Reranking Approach for Large-Scale Domain Classification in Natural Language Understanding
Apr 22, 2018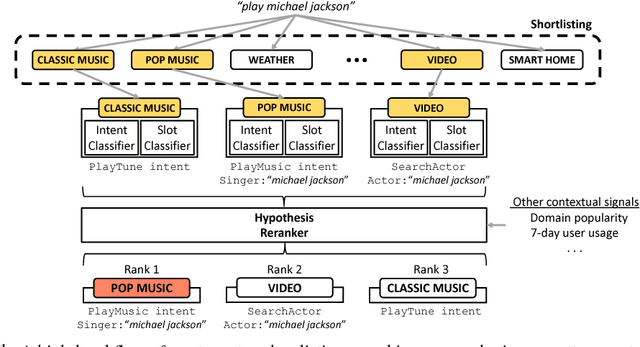
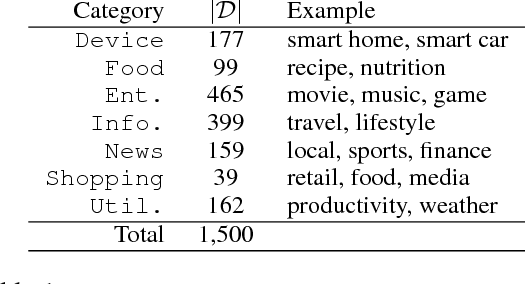

Intelligent personal digital assistants (IPDAs), a popular real-life application with spoken language understanding capabilities, can cover potentially thousands of overlapping domains for natural language understanding, and the task of finding the best domain to handle an utterance becomes a challenging problem on a large scale. In this paper, we propose a set of efficient and scalable neural shortlisting-reranking models for large-scale domain classification in IPDAs. The shortlisting stage focuses on efficiently trimming all domains down to a list of k-best candidate domains, and the reranking stage performs a list-wise reranking of the initial k-best domains with additional contextual information. We show the effectiveness of our approach with extensive experiments on 1,500 IPDA domains.