 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$PA^3$: $\textbf{P}$olicy-$\textbf{A}$ware $\textbf{A}$gent $\textbf{A}$lignment through Chain-of-Thought
Mar 15, 2026Conversational assistants powered by large language models (LLMs) excel at tool-use tasks but struggle with adhering to complex, business-specific rules. While models can reason over business rules provided in context, including all policies for every query introduces high latency and wastes compute. Furthermore, these lengthy prompts lead to long contexts, harming overall performance due to the "needle-in-the-haystack" problem. To address these challenges, we propose a multi-stage alignment method that teaches models to recall and apply relevant business policies during chain-of-thought reasoning at inference time, without including the full business policy in-context. Furthermore, we introduce a novel PolicyRecall reward based on the Jaccard score and a Hallucination Penalty for GRPO training. Altogether, our best model outperforms the baseline by 16 points and surpasses comparable in-context baselines of similar model size by 3 points, while using 40% fewer words.
Multimodal Policy Internalization for Conversational Agents
Oct 10, 2025Modern conversational agents like ChatGPT and Alexa+ rely on predefined policies specifying metadata, response styles, and tool-usage rules. As these LLM-based systems expand to support diverse business and user queries, such policies, often implemented as in-context prompts, are becoming increasingly complex and lengthy, making faithful adherence difficult and imposing large fixed computational costs. With the rise of multimodal agents, policies that govern visual and multimodal behaviors are critical but remain understudied. Prior prompt-compression work mainly shortens task templates and demonstrations, while existing policy-alignment studies focus only on text-based safety rules. We introduce Multimodal Policy Internalization (MPI), a new task that internalizes reasoning-intensive multimodal policies into model parameters, enabling stronger policy-following without including the policy during inference. MPI poses unique data and algorithmic challenges. We build two datasets spanning synthetic and real-world decision-making and tool-using tasks and propose TriMPI, a three-stage training framework. TriMPI first injects policy knowledge via continual pretraining, then performs supervised finetuning, and finally applies PolicyRollout, a GRPO-style reinforcement learning extension that augments rollouts with policy-aware responses for grounded exploration. TriMPI achieves notable gains in end-to-end accuracy, generalization, and robustness to forgetting. As the first work on multimodal policy internalization, we provide datasets, training recipes, and comprehensive evaluations to foster future research. Project page: https://mikewangwzhl.github.io/TriMPI.
Learning Slice-Aware Representations with Mixture of Attentions
Jun 04, 2021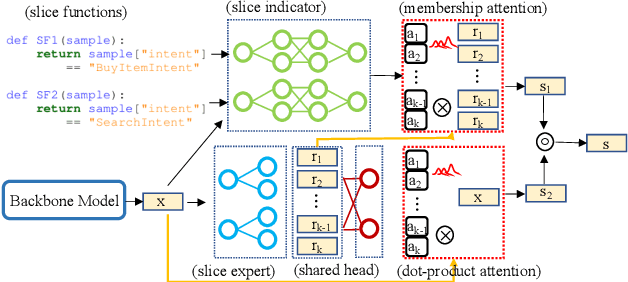

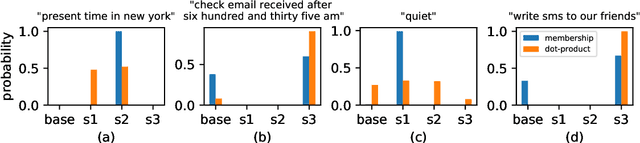
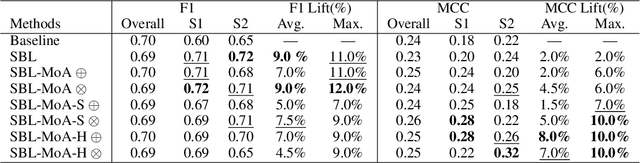
Real-world machine learning systems are achieving remarkable performance in terms of coarse-grained metrics like overall accuracy and F-1 score. However, model improvement and development often require fine-grained modeling on individual data subsets or slices, for instance, the data slices where the models have unsatisfactory results. In practice, it gives tangible values for developing such models that can pay extra attention to critical or interested slices while retaining the original overall performance. This work extends the recent slice-based learning (SBL)~\cite{chen2019slice} with a mixture of attentions (MoA) to learn slice-aware dual attentive representations. We empirically show that the MoA approach outperforms the baseline method as well as the original SBL approach on monitored slices with two natural language understanding (NLU) tasks.
Handling Long-Tail Queries with Slice-Aware Conversational Systems
Apr 26, 2021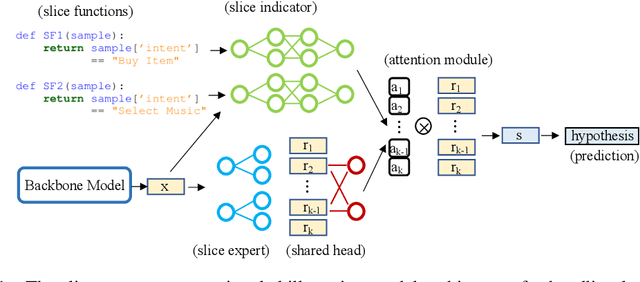

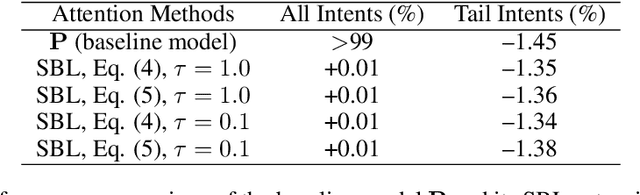

We have been witnessing the usefulness of conversational AI systems such as Siri and Alexa, directly impacting our daily lives. These systems normally rely on machine learning models evolving over time to provide quality user experience. However, the development and improvement of the models are challenging because they need to support both high (head) and low (tail) usage scenarios, requiring fine-grained modeling strategies for specific data subsets or slices. In this paper, we explore the recent concept of slice-based learning (SBL) (Chen et al., 2019) to improve our baseline conversational skill routing system on the tail yet critical query traffic. We first define a set of labeling functions to generate weak supervision data for the tail intents. We then extend the baseline model towards a slice-aware architecture, which monitors and improves the model performance on the selected tail intents. Applied to de-identified live traffic from a commercial conversational AI system, our experiments show that the slice-aware model is beneficial in improving model performance for the tail intents while maintaining the overall performance.
Neural model robustness for skill routing in large-scale conversational AI systems: A design choice exploration
Mar 04, 2021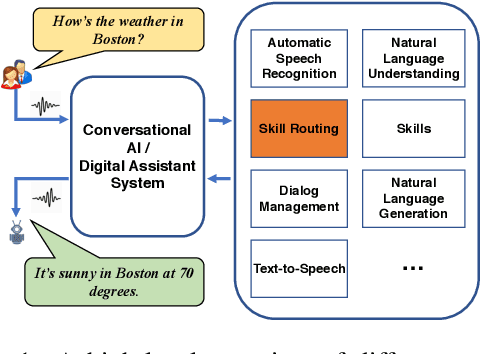
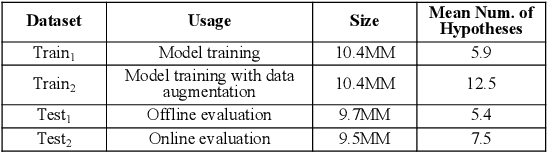
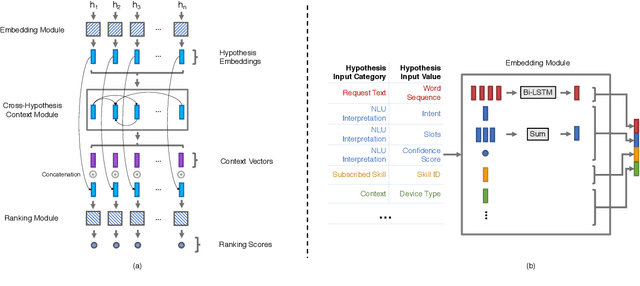

Current state-of-the-art large-scale conversational AI or intelligent digital assistant systems in industry comprises a set of components such as Automatic Speech Recognition (ASR) and Natural Language Understanding (NLU). For some of these systems that leverage a shared NLU ontology (e.g., a centralized intent/slot schema), there exists a separate skill routing component to correctly route a request to an appropriate skill, which is either a first-party or third-party application that actually executes on a user request. The skill routing component is needed as there are thousands of skills that can either subscribe to the same intent and/or subscribe to an intent under specific contextual conditions (e.g., device has a screen). Ensuring model robustness or resilience in the skill routing component is an important problem since skills may dynamically change their subscription in the ontology after the skill routing model has been deployed to production. We show how different modeling design choices impact the model robustness in the context of skill routing on a state-of-the-art commercial conversational AI system, specifically on the choices around data augmentation, model architecture, and optimization method. We show that applying data augmentation can be a very effective and practical way to drastically improve model robustness.
A Scalable Framework for Learning From Implicit User Feedback to Improve Natural Language Understanding in Large-Scale Conversational AI Systems
Oct 23, 2020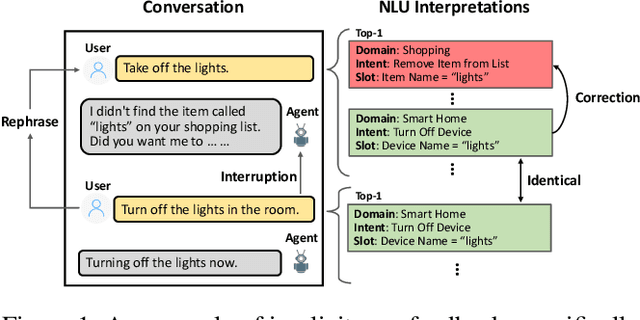
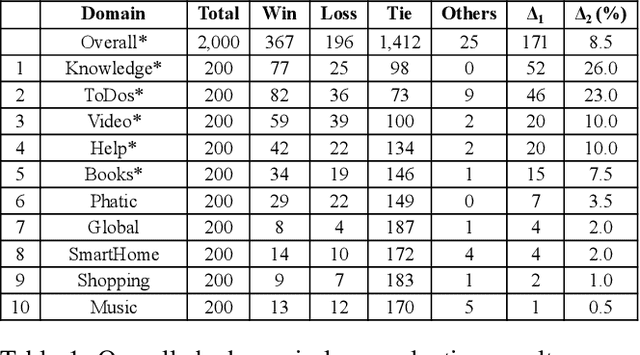
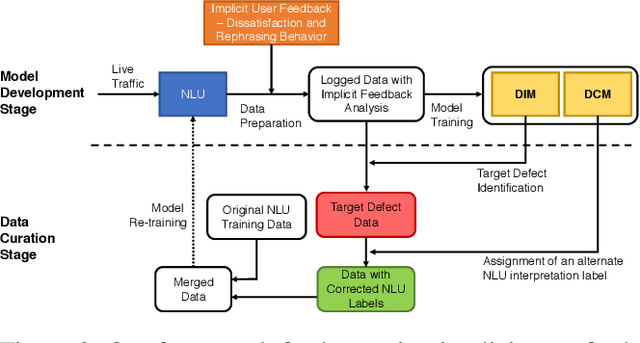
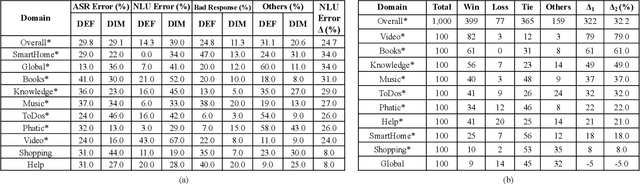
Natural Language Understanding (NLU) is an established component within a conversational AI or digital assistant system, and it is responsible for producing semantic understanding of a user request. We propose a scalable and automatic approach for improving NLU in a large-scale conversational AI system by leveraging implicit user feedback, with an insight that user interaction data and dialog context have rich information embedded from which user satisfaction and intention can be inferred. In particular, we propose a general domain-agnostic framework for curating new supervision data for improving NLU from live production traffic. With an extensive set of experiments, we show the results of applying the framework and improving NLU for a large-scale production system and show its impact across 10 domains.
Large-scale Hybrid Approach for Predicting User Satisfaction with Conversational Agents
May 29, 2020
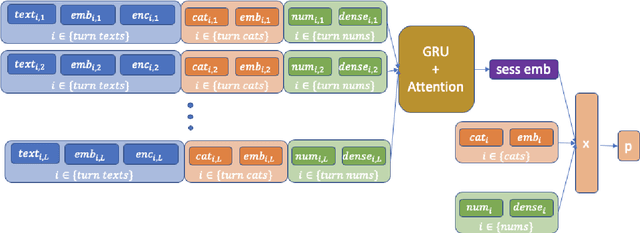
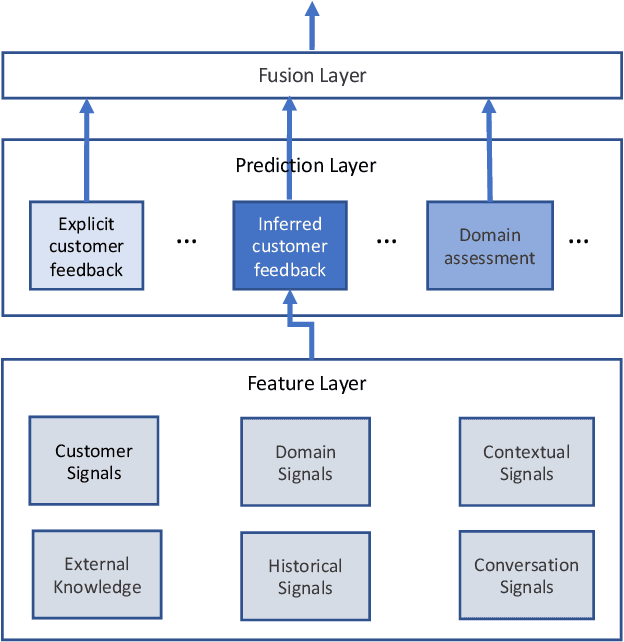
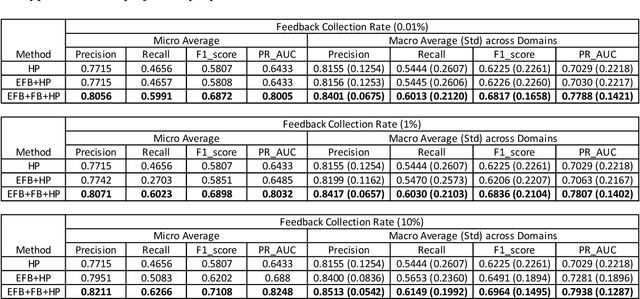
Measuring user satisfaction level is a challenging task, and a critical component in developing large-scale conversational agent systems serving the needs of real users. An widely used approach to tackle this is to collect human annotation data and use them for evaluation or modeling. Human annotation based approaches are easier to control, but hard to scale. A novel alternative approach is to collect user's direct feedback via a feedback elicitation system embedded to the conversational agent system, and use the collected user feedback to train a machine-learned model for generalization. User feedback is the best proxy for user satisfaction, but is not available for some ineligible intents and certain situations. Thus, these two types of approaches are complementary to each other. In this work, we tackle the user satisfaction assessment problem with a hybrid approach that fuses explicit user feedback, user satisfaction predictions inferred by two machine-learned models, one trained on user feedback data and the other human annotation data. The hybrid approach is based on a waterfall policy, and the experimental results with Amazon Alexa's large-scale datasets show significant improvements in inferring user satisfaction. A detailed hybrid architecture, an in-depth analysis on user feedback data, and an algorithm that generates data sets to properly simulate the live traffic are presented in this paper.
Feedback-Based Self-Learning in Large-Scale Conversational AI Agents
Nov 06, 2019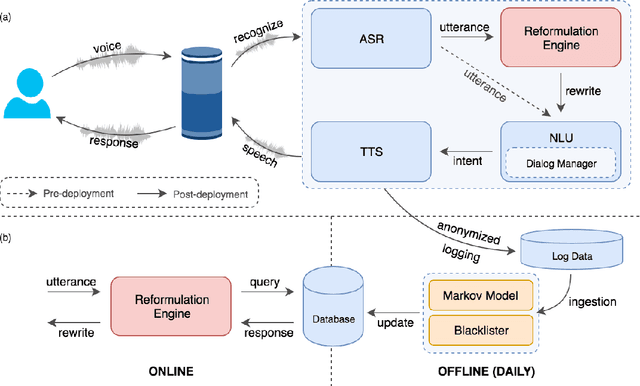

Today, most large-scale conversational AI agents (e.g. Alexa, Siri, or Google Assistant) are built using manually annotated data to train the different components of the system. Typically, the accuracy of the ML models in these components are improved by manually transcribing and annotating data. As the scope of these systems increase to cover more scenarios and domains, manual annotation to improve the accuracy of these components becomes prohibitively costly and time consuming. In this paper, we propose a system that leverages user-system interaction feedback signals to automate learning without any manual annotation. Users here tend to modify a previous query in hopes of fixing an error in the previous turn to get the right results. These reformulations, which are often preceded by defective experiences caused by errors in ASR, NLU, ER or the application. In some cases, users may not properly formulate their requests (e.g. providing partial title of a song), but gleaning across a wider pool of users and sessions reveals the underlying recurrent patterns. Our proposed self-learning system automatically detects the errors, generate reformulations and deploys fixes to the runtime system to correct different types of errors occurring in different components of the system. In particular, we propose leveraging an absorbing Markov Chain model as a collaborative filtering mechanism in a novel attempt to mine these patterns. We show that our approach is highly scalable, and able to learn reformulations that reduce Alexa-user errors by pooling anonymized data across millions of customers. The proposed self-learning system achieves a win/loss ratio of 11.8 and effectively reduces the defect rate by more than 30% on utterance level reformulations in our production A/B tests. To the best of our knowledge, this is the first self-learning large-scale conversational AI system in production.
Locale-agnostic Universal Domain Classification Model in Spoken Language Understanding
May 02, 2019

In this paper, we introduce an approach for leveraging available data across multiple locales sharing the same language to 1) improve domain classification model accuracy in Spoken Language Understanding and user experience even if new locales do not have sufficient data and 2) reduce the cost of scaling the domain classifier to a large number of locales. We propose a locale-agnostic universal domain classification model based on selective multi-task learning that learns a joint representation of an utterance over locales with different sets of domains and allows locales to share knowledge selectively depending on the domains. The experimental results demonstrate the effectiveness of our approach on domain classification task in the scenario of multiple locales with imbalanced data and disparate domain sets. The proposed approach outperforms other baselines models especially when classifying locale-specific domains and also low-resourced domains.
Continuous Learning for Large-scale Personalized Domain Classification
May 02, 2019

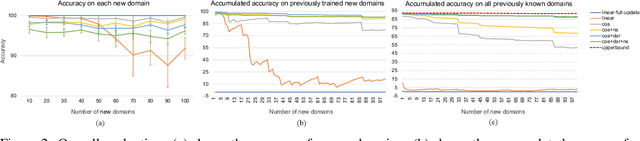

Domain classification is the task of mapping spoken language utterances to one of the natural language understanding domains in intelligent personal digital assistants (IPDAs). This is a major component in mainstream IPDAs in industry. Apart from official domains, thousands of third-party domains are also created by external developers to enhance the capability of IPDAs. As more domains are developed rapidly, the question of how to continuously accommodate the new domains still remains challenging. Moreover, existing continual learning approaches do not address the problem of incorporating personalized information dynamically for better domain classification. In this paper, we propose CoNDA, a neural network based approach for domain classification that supports incremental learning of new classes. Empirical evaluation shows that CoNDA achieves high accuracy and outperforms baselines by a large margin on both incrementally added new domains and existing domains.