 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural model robustness for skill routing in large-scale conversational AI systems: A design choice exploration
Mar 04, 2021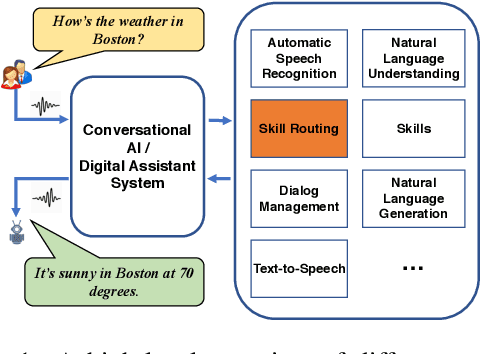
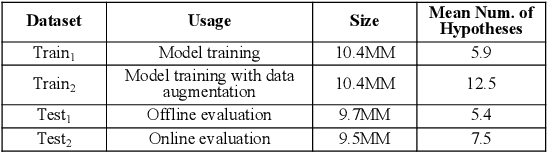
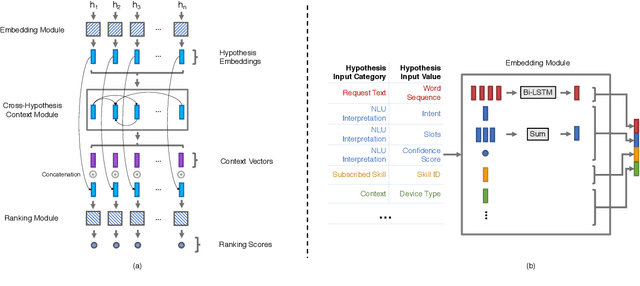

Current state-of-the-art large-scale conversational AI or intelligent digital assistant systems in industry comprises a set of components such as Automatic Speech Recognition (ASR) and Natural Language Understanding (NLU). For some of these systems that leverage a shared NLU ontology (e.g., a centralized intent/slot schema), there exists a separate skill routing component to correctly route a request to an appropriate skill, which is either a first-party or third-party application that actually executes on a user request. The skill routing component is needed as there are thousands of skills that can either subscribe to the same intent and/or subscribe to an intent under specific contextual conditions (e.g., device has a screen). Ensuring model robustness or resilience in the skill routing component is an important problem since skills may dynamically change their subscription in the ontology after the skill routing model has been deployed to production. We show how different modeling design choices impact the model robustness in the context of skill routing on a state-of-the-art commercial conversational AI system, specifically on the choices around data augmentation, model architecture, and optimization method. We show that applying data augmentation can be a very effective and practical way to drastically improve model robustness.