 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINTELLECT-3: Technical Report
Dec 18, 2025We present INTELLECT-3, a 106B-parameter Mixture-of-Experts model (12B active) trained with large-scale reinforcement learning on our end-to-end RL infrastructure stack. INTELLECT-3 achieves state of the art performance for its size across math, code, science and reasoning benchmarks, outperforming many larger frontier models. We open-source the model together with the full infrastructure stack used to create it, including RL frameworks, complete recipe, and a wide collection of environments, built with the verifiers library, for training and evaluation from our Environments Hub community platform. Built for this effort, we introduce prime-rl, an open framework for large-scale asynchronous reinforcement learning, which scales seamlessly from a single node to thousands of GPUs, and is tailored for agentic RL with first-class support for multi-turn interactions and tool use. Using this stack, we run both SFT and RL training on top of the GLM-4.5-Air-Base model, scaling RL training up to 512 H200s with high training efficiency.
Beat the long tail: Distribution-Aware Speculative Decoding for RL Training
Nov 17, 2025Reinforcement learning(RL) post-training has become essential for aligning large language models (LLMs), yet its efficiency is increasingly constrained by the rollout phase, where long trajectories are generated token by token. We identify a major bottleneck:the long-tail distribution of rollout lengths, where a small fraction of long generations dominates wall clock time and a complementary opportunity; the availability of historical rollouts that reveal stable prompt level patterns across training epochs. Motivated by these observations, we propose DAS, a Distribution Aware Speculative decoding framework that accelerates RL rollouts without altering model outputs. DAS integrates two key ideas: an adaptive, nonparametric drafter built from recent rollouts using an incrementally maintained suffix tree, and a length aware speculation policy that allocates more aggressive draft budgets to long trajectories that dominate makespan. This design exploits rollout history to sustain acceptance while balancing base and token level costs during decoding. Experiments on math and code reasoning tasks show that DAS reduces rollout time up to 50% while preserving identical training curves, demonstrating that distribution-aware speculative decoding can significantly accelerate RL post training without compromising learning quality.
Graph-Guided Reasoning for Multi-Hop Question Answering in Large Language Models
Nov 16, 2023



Chain-of-Thought (CoT) prompting has boosted the multi-step reasoning capabilities of Large Language Models (LLMs) by generating a series of rationales before the final answer. We analyze the reasoning paths generated by CoT and find two issues in multi-step reasoning: (i) Generating rationales irrelevant to the question, (ii) Unable to compose subquestions or queries for generating/retrieving all the relevant information. To address them, we propose a graph-guided CoT prompting method, which guides the LLMs to reach the correct answer with graph representation/verification steps. Specifically, we first leverage LLMs to construct a "question/rationale graph" by using knowledge extraction prompting given the initial question and the rationales generated in the previous steps. Then, the graph verification step diagnoses the current rationale triplet by comparing it with the existing question/rationale graph to filter out irrelevant rationales and generate follow-up questions to obtain relevant information. Additionally, we generate CoT paths that exclude the extracted graph information to represent the context information missed from the graph extraction. Our graph-guided reasoning method shows superior performance compared to previous CoT prompting and the variants on multi-hop question answering benchmark datasets.
A Scalable Framework for Learning From Implicit User Feedback to Improve Natural Language Understanding in Large-Scale Conversational AI Systems
Oct 23, 2020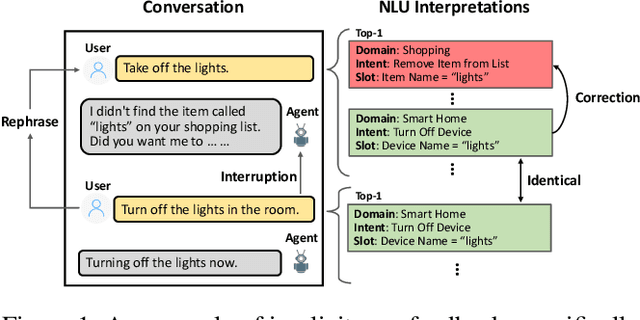
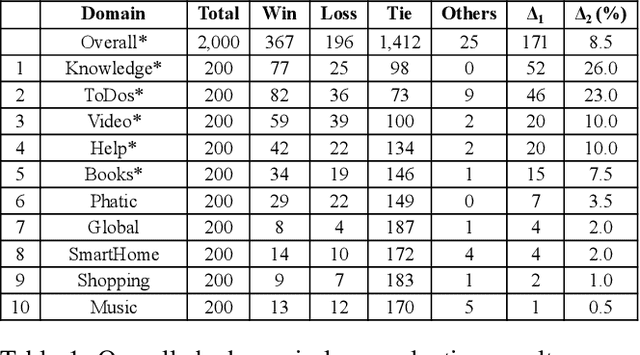
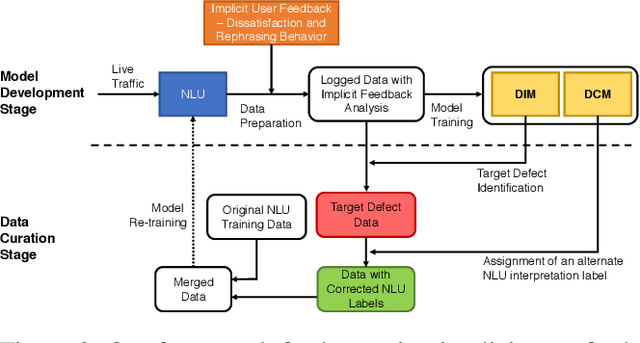
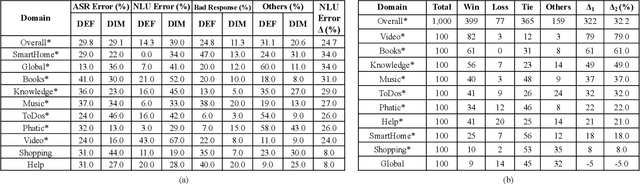
Natural Language Understanding (NLU) is an established component within a conversational AI or digital assistant system, and it is responsible for producing semantic understanding of a user request. We propose a scalable and automatic approach for improving NLU in a large-scale conversational AI system by leveraging implicit user feedback, with an insight that user interaction data and dialog context have rich information embedded from which user satisfaction and intention can be inferred. In particular, we propose a general domain-agnostic framework for curating new supervision data for improving NLU from live production traffic. With an extensive set of experiments, we show the results of applying the framework and improving NLU for a large-scale production system and show its impact across 10 domains.