 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward a Rational and Ethical Sociotechnical System of Autonomous Vehicles: A Novel Application of Multi-Criteria Decision Analysis
Feb 04, 2021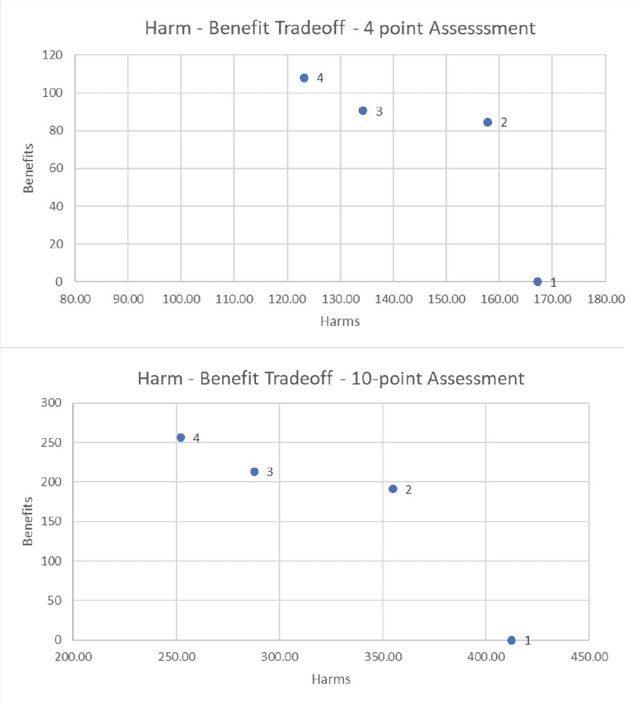


The expansion of artificial intelligence (AI) and autonomous systems has shown the potential to generate enormous social good while also raising serious ethical and safety concerns. AI technology is increasingly adopted in transportation. A survey of various in-vehicle technologies found that approximately 64% of the respondents used a smartphone application to assist with their travel. The top-used applications were navigation and real-time traffic information systems. Among those who used smartphones during their commutes, the top-used applications were navigation and entertainment. There is a pressing need to address relevant social concerns to allow for the development of systems of intelligent agents that are informed and cognizant of ethical standards. Doing so will facilitate the responsible integration of these systems in society. To this end, we have applied Multi-Criteria Decision Analysis (MCDA) to develop a formal Multi-Attribute Impact Assessment (MAIA) questionnaire for examining the social and ethical issues associated with the uptake of AI. We have focused on the domain of autonomous vehicles (AVs) because of their imminent expansion. However, AVs could serve as a stand-in for any domain where intelligent, autonomous agents interact with humans, either on an individual level (e.g., pedestrians, passengers) or a societal level.
Differentiable Greedy Networks
Oct 30, 2018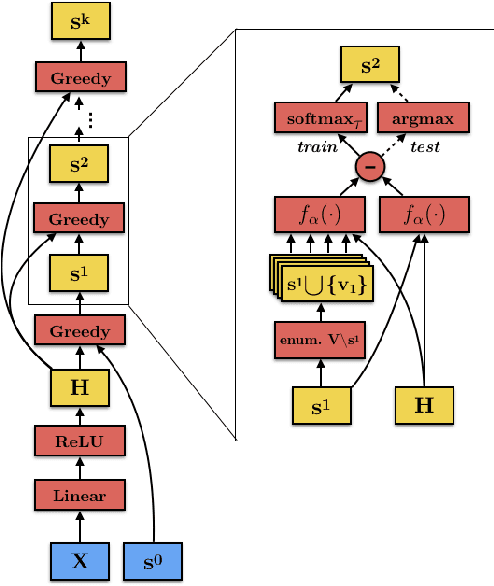
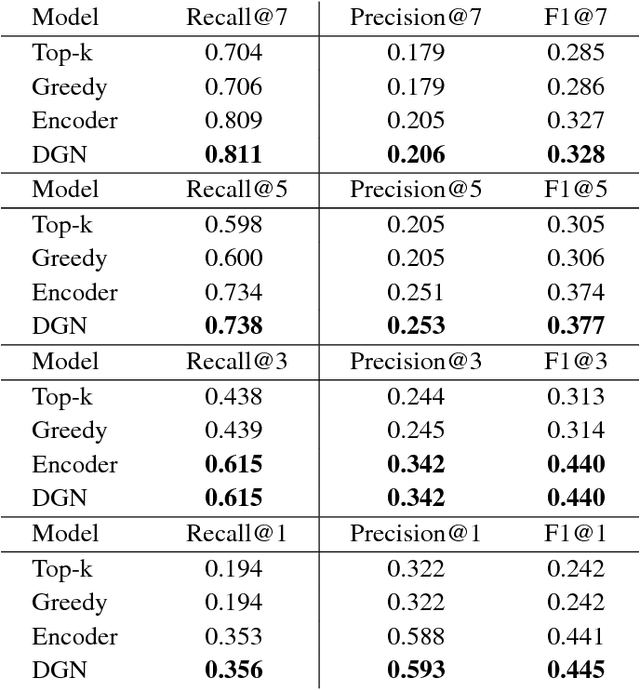
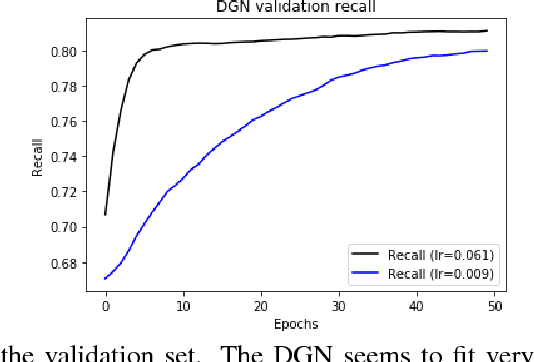

Optimal selection of a subset of items from a given set is a hard problem that requires combinatorial optimization. In this paper, we propose a subset selection algorithm that is trainable with gradient-based methods yet achieves near-optimal performance via submodular optimization. We focus on the task of identifying a relevant set of sentences for claim verification in the context of the FEVER task. Conventional methods for this task look at sentences on their individual merit and thus do not optimize the informativeness of sentences as a set. We show that our proposed method which builds on the idea of unfolding a greedy algorithm into a computational graph allows both interpretability and gradient-based training. The proposed differentiable greedy network (DGN) outperforms discrete optimization algorithms as well as other baseline methods in terms of precision and recall.
Deep Recurrent NMF for Speech Separation by Unfolding Iterative Thresholding
Sep 21, 2017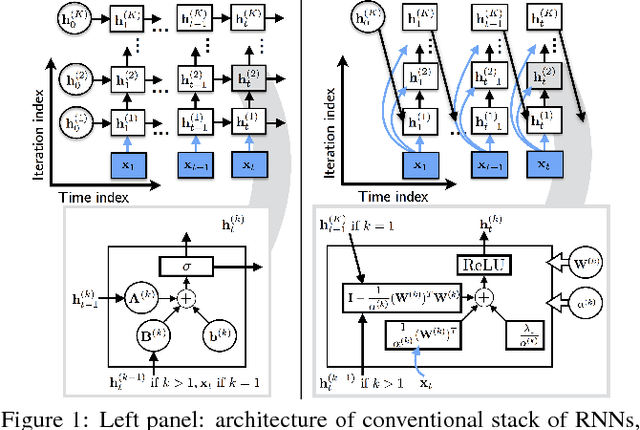
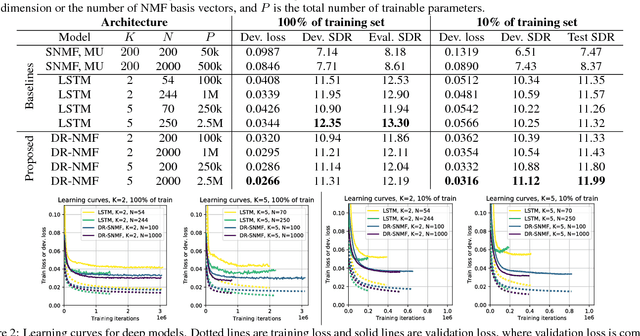
In this paper, we propose a novel recurrent neural network architecture for speech separation. This architecture is constructed by unfolding the iterations of a sequential iterative soft-thresholding algorithm (ISTA) that solves the optimization problem for sparse nonnegative matrix factorization (NMF) of spectrograms. We name this network architecture deep recurrent NMF (DR-NMF). The proposed DR-NMF network has three distinct advantages. First, DR-NMF provides better interpretability than other deep architectures, since the weights correspond to NMF model parameters, even after training. This interpretability also provides principled initializations that enable faster training and convergence to better solutions compared to conventional random initialization. Second, like many deep networks, DR-NMF is an order of magnitude faster at test time than NMF, since computation of the network output only requires evaluating a few layers at each time step. Third, when a limited amount of training data is available, DR-NMF exhibits stronger generalization and separation performance compared to sparse NMF and state-of-the-art long-short term memory (LSTM) networks. When a large amount of training data is available, DR-NMF achieves lower yet competitive separation performance compared to LSTM networks.
Interpretable Recurrent Neural Networks Using Sequential Sparse Recovery
Nov 22, 2016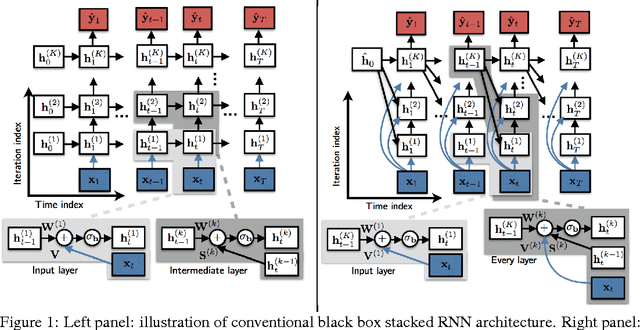
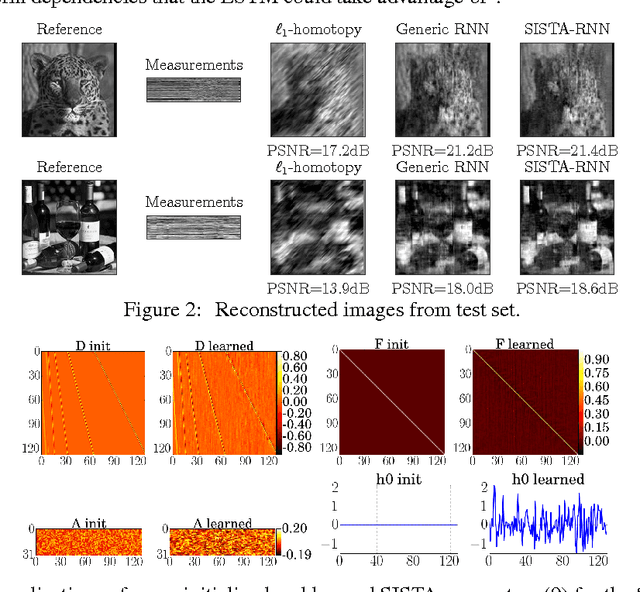
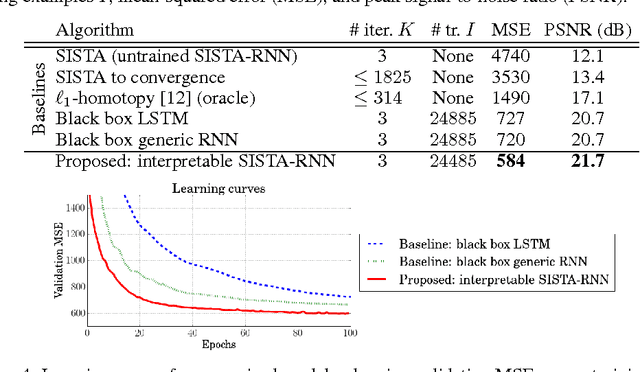
Recurrent neural networks (RNNs) are powerful and effective for processing sequential data. However, RNNs are usually considered "black box" models whose internal structure and learned parameters are not interpretable. In this paper, we propose an interpretable RNN based on the sequential iterative soft-thresholding algorithm (SISTA) for solving the sequential sparse recovery problem, which models a sequence of correlated observations with a sequence of sparse latent vectors. The architecture of the resulting SISTA-RNN is implicitly defined by the computational structure of SISTA, which results in a novel stacked RNN architecture. Furthermore, the weights of the SISTA-RNN are perfectly interpretable as the parameters of a principled statistical model, which in this case include a sparsifying dictionary, iterative step size, and regularization parameters. In addition, on a particular sequential compressive sensing task, the SISTA-RNN trains faster and achieves better performance than conventional state-of-the-art black box RNNs, including long-short term memory (LSTM) RNNs.
Full-Capacity Unitary Recurrent Neural Networks
Oct 31, 2016Recurrent neural networks are powerful models for processing sequential data, but they are generally plagued by vanishing and exploding gradient problems. Unitary recurrent neural networks (uRNNs), which use unitary recurrence matrices, have recently been proposed as a means to avoid these issues. However, in previous experiments, the recurrence matrices were restricted to be a product of parameterized unitary matrices, and an open question remains: when does such a parameterization fail to represent all unitary matrices, and how does this restricted representational capacity limit what can be learned? To address this question, we propose full-capacity uRNNs that optimize their recurrence matrix over all unitary matrices, leading to significantly improved performance over uRNNs that use a restricted-capacity recurrence matrix. Our contribution consists of two main components. First, we provide a theoretical argument to determine if a unitary parameterization has restricted capacity. Using this argument, we show that a recently proposed unitary parameterization has restricted capacity for hidden state dimension greater than 7. Second, we show how a complete, full-capacity unitary recurrence matrix can be optimized over the differentiable manifold of unitary matrices. The resulting multiplicative gradient step is very simple and does not require gradient clipping or learning rate adaptation. We confirm the utility of our claims by empirically evaluating our new full-capacity uRNNs on both synthetic and natural data, achieving superior performance compared to both LSTMs and the original restricted-capacity uRNNs.
Enhancement and Recognition of Reverberant and Noisy Speech by Extending Its Coherence
Sep 02, 2015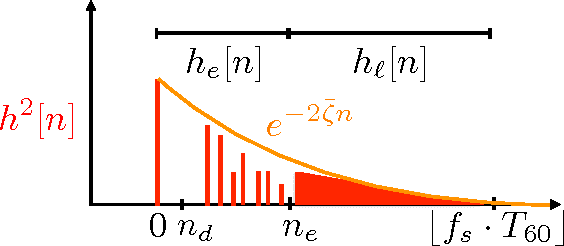
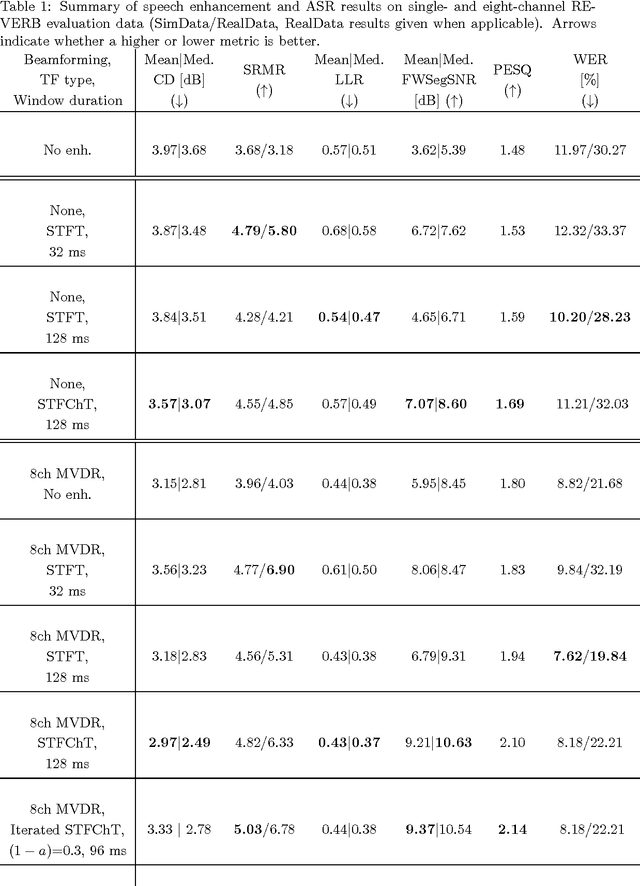
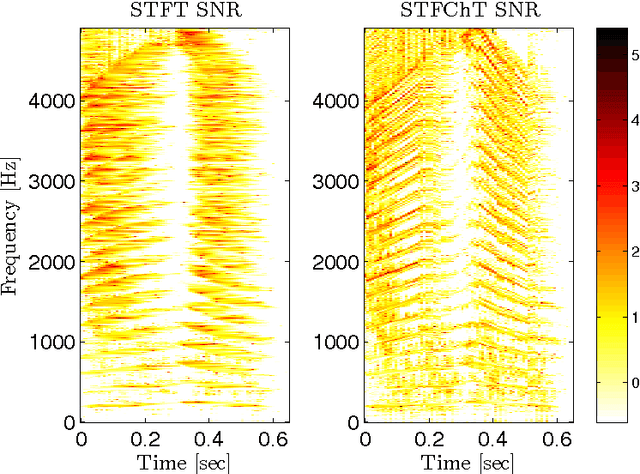
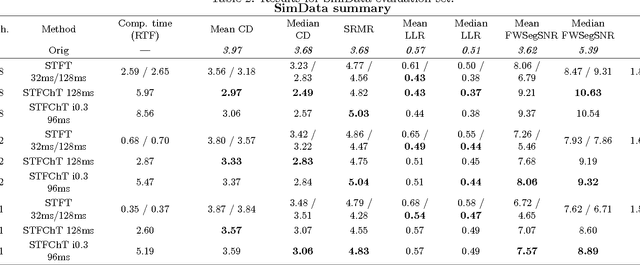
Most speech enhancement algorithms make use of the short-time Fourier transform (STFT), which is a simple and flexible time-frequency decomposition that estimates the short-time spectrum of a signal. However, the duration of short STFT frames are inherently limited by the nonstationarity of speech signals. The main contribution of this paper is a demonstration of speech enhancement and automatic speech recognition in the presence of reverberation and noise by extending the length of analysis windows. We accomplish this extension by performing enhancement in the short-time fan-chirp transform (STFChT) domain, an overcomplete time-frequency representation that is coherent with speech signals over longer analysis window durations than the STFT. This extended coherence is gained by using a linear model of fundamental frequency variation of voiced speech signals. Our approach centers around using a single-channel minimum mean-square error log-spectral amplitude (MMSE-LSA) estimator proposed by Habets, which scales coefficients in a time-frequency domain to suppress noise and reverberation. In the case of multiple microphones, we preprocess the data with either a minimum variance distortionless response (MVDR) beamformer, or a delay-and-sum beamformer (DSB). We evaluate our algorithm on both speech enhancement and recognition tasks for the REVERB challenge dataset. Compared to the same processing done in the STFT domain, our approach achieves significant improvement in terms of objective enhancement metrics (including PESQ---the ITU-T standard measurement for speech quality). In terms of automatic speech recognition (ASR) performance as measured by word error rate (WER), our experiments indicate that the STFT with a long window is more effective for ASR.