 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyber Deception for Mission Surveillance via Hypergame-Theoretic Deep Reinforcement Learning
Mar 21, 2026Unmanned Aerial Vehicles (UAVs) are valuable for mission-critical systems like surveillance, rescue, or delivery. Not surprisingly, such systems attract cyberattacks, including Denial-of-Service (DoS) attacks to overwhelm the resources of mission drones (MDs). How can we defend UAV mission systems against DoS attacks? We adopt cyber deception as a defense strategy, in which honey drones (HDs) are proposed to bait and divert attacks. The attack and deceptive defense hinge upon radio signal strength: The attacker selects victim MDs based on their signals, and HDs attract the attacker from afar by emitting stronger signals, despite this reducing battery life. We formulate an optimization problem for the attacker and defender to identify their respective strategies for maximizing mission performance while minimizing energy consumption. To address this problem, we propose a novel approach, called HT-DRL. HT-DRL identifies optimal solutions without a long learning convergence time by taking the solutions of hypergame theory into the neural network of deep reinforcement learning. This achieves a systematic way to intelligently deceive attackers. We analyze the performance of diverse defense mechanisms under different attack strategies. Further, the HT-DRL-based HD approach outperforms existing non-HD counterparts up to two times better in mission performance while incurring low energy consumption.
Gricean Norms as a Basis for Effective Collaboration
Mar 18, 2025



Effective human-AI collaboration hinges not only on the AI agent's ability to follow explicit instructions but also on its capacity to navigate ambiguity, incompleteness, invalidity, and irrelevance in communication. Gricean conversational and inference norms facilitate collaboration by aligning unclear instructions with cooperative principles. We propose a normative framework that integrates Gricean norms and cognitive frameworks -- common ground, relevance theory, and theory of mind -- into large language model (LLM) based agents. The normative framework adopts the Gricean maxims of quantity, quality, relation, and manner, along with inference, as Gricean norms to interpret unclear instructions, which are: ambiguous, incomplete, invalid, or irrelevant. Within this framework, we introduce Lamoids, GPT-4 powered agents designed to collaborate with humans. To assess the influence of Gricean norms in human-AI collaboration, we evaluate two versions of a Lamoid: one with norms and one without. In our experiments, a Lamoid collaborates with a human to achieve shared goals in a grid world (Doors, Keys, and Gems) by interpreting both clear and unclear natural language instructions. Our results reveal that the Lamoid with Gricean norms achieves higher task accuracy and generates clearer, more accurate, and contextually relevant responses than the Lamoid without norms. This improvement stems from the normative framework, which enhances the agent's pragmatic reasoning, fostering effective human-AI collaboration and enabling context-aware communication in LLM-based agents.
Right vs. Right: Can LLMs Make Tough Choices?
Dec 27, 2024



An ethical dilemma describes a choice between two "right" options involving conflicting moral values. We present a comprehensive evaluation of how LLMs navigate ethical dilemmas. Specifically, we investigate LLMs on their (1) sensitivity in comprehending ethical dilemmas, (2) consistency in moral value choice, (3) consideration of consequences, and (4) ability to align their responses to a moral value preference explicitly or implicitly specified in a prompt. Drawing inspiration from a leading ethical framework, we construct a dataset comprising 1,730 ethical dilemmas involving four pairs of conflicting values. We evaluate 20 well-known LLMs from six families. Our experiments reveal that: (1) LLMs exhibit pronounced preferences between major value pairs, and prioritize truth over loyalty, community over individual, and long-term over short-term considerations. (2) The larger LLMs tend to support a deontological perspective, maintaining their choices of actions even when negative consequences are specified. (3) Explicit guidelines are more effective in guiding LLMs' moral choice than in-context examples. Lastly, our experiments highlight the limitation of LLMs in comprehending different formulations of ethical dilemmas.
Reasoner Outperforms: Generative Stance Detection with Rationalization for Social Media
Dec 13, 2024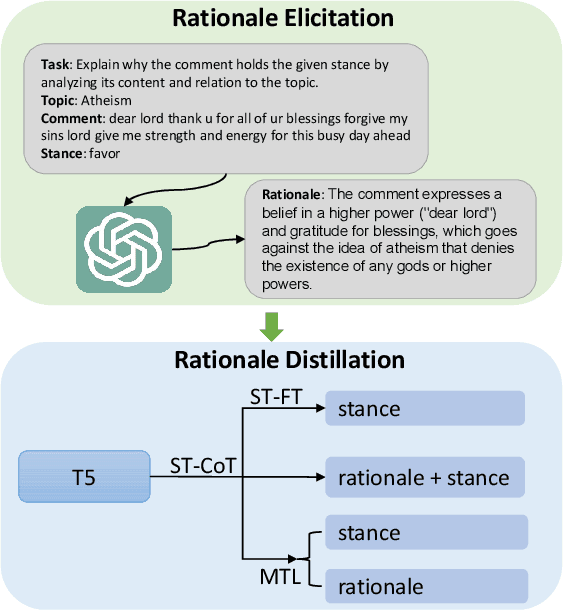

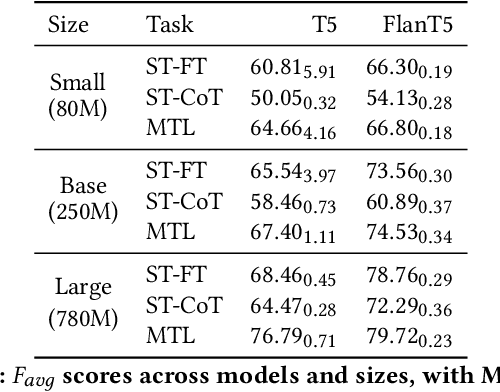
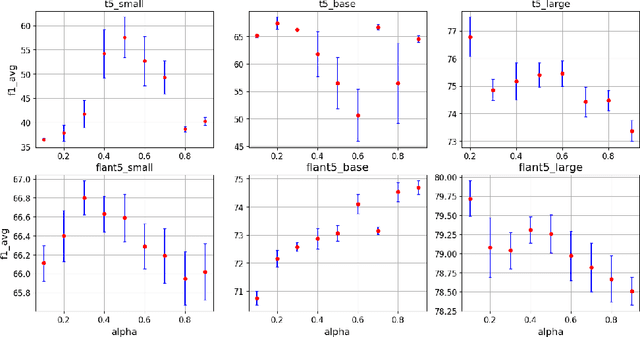
Stance detection is crucial for fostering a human-centric Web by analyzing user-generated content to identify biases and harmful narratives that undermine trust. With the development of Large Language Models (LLMs), existing approaches treat stance detection as a classification problem, providing robust methodologies for modeling complex group interactions and advancing capabilities in natural language tasks. However, these methods often lack interpretability, limiting their ability to offer transparent and understandable justifications for predictions. This study adopts a generative approach, where stance predictions include explicit, interpretable rationales, and integrates them into smaller language models through single-task and multitask learning. We find that incorporating reasoning into stance detection enables the smaller model (FlanT5) to outperform GPT-3.5's zero-shot performance, achieving an improvement of up to 9.57%. Moreover, our results show that reasoning capabilities enhance multitask learning performance but may reduce effectiveness in single-task settings. Crucially, we demonstrate that faithful rationales improve rationale distillation into SLMs, advancing efforts to build interpretable, trustworthy systems for addressing discrimination, fostering trust, and promoting equitable engagement on social media.
A Benchmark for Cross-Domain Argumentative Stance Classification on Social Media
Oct 11, 2024
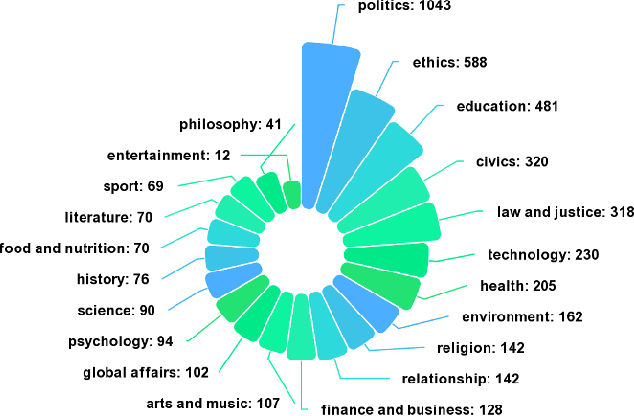
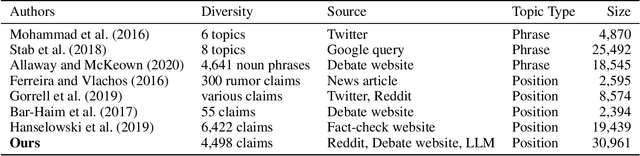

Argumentative stance classification plays a key role in identifying authors' viewpoints on specific topics. However, generating diverse pairs of argumentative sentences across various domains is challenging. Existing benchmarks often come from a single domain or focus on a limited set of topics. Additionally, manual annotation for accurate labeling is time-consuming and labor-intensive. To address these challenges, we propose leveraging platform rules, readily available expert-curated content, and large language models to bypass the need for human annotation. Our approach produces a multidomain benchmark comprising 4,498 topical claims and 30,961 arguments from three sources, spanning 21 domains. We benchmark the dataset in fully supervised, zero-shot, and few-shot settings, shedding light on the strengths and limitations of different methodologies. We release the dataset and code in this study at hidden for anonymity.
Value-Based Rationales Improve Social Experience: A Multiagent Simulation Study
Aug 04, 2024



We propose Exanna, a framework to realize agents that incorporate values in decision making. An Exannaagent considers the values of itself and others when providing rationales for its actions and evaluating the rationales provided by others. Via multiagent simulation, we demonstrate that considering values in decision making and producing rationales, especially for norm-deviating actions, leads to (1) higher conflict resolution, (2) better social experience, (3) higher privacy, and (4) higher flexibility.
Extracting Norms from Contracts Via ChatGPT: Opportunities and Challenges
Apr 02, 2024We investigate the effectiveness of ChatGPT in extracting norms from contracts. Norms provide a natural way to engineer multiagent systems by capturing how to govern the interactions between two or more autonomous parties. We extract norms of commitment, prohibition, authorization, and power, along with associated norm elements (the parties involved, antecedents, and consequents) from contracts. Our investigation reveals ChatGPT's effectiveness and limitations in norm extraction from contracts. ChatGPT demonstrates promising performance in norm extraction without requiring training or fine-tuning, thus obviating the need for annotated data, which is not generally available in this domain. However, we found some limitations of ChatGPT in extracting these norms that lead to incorrect norm extractions. The limitations include oversight of crucial details, hallucination, incorrect parsing of conjunctions, and empty norm elements. Enhanced norm extraction from contracts can foster the development of more transparent and trustworthy formal agent interaction specifications, thereby contributing to the improvement of multiagent systems.
Decision Theory-Guided Deep Reinforcement Learning for Fast Learning
Feb 08, 2024
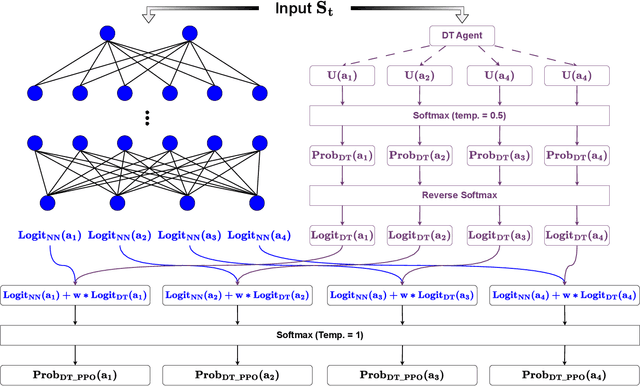
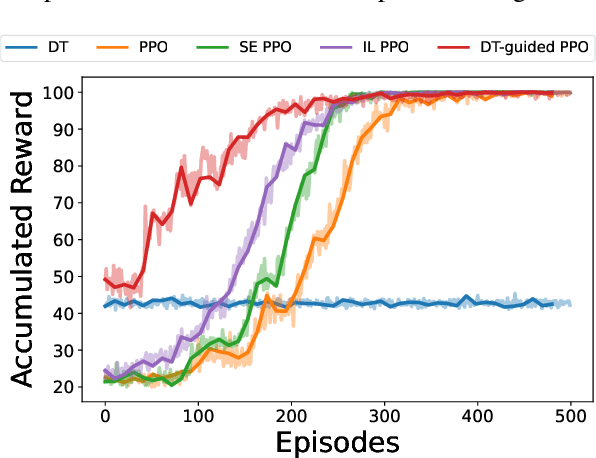
This paper introduces a novel approach, Decision Theory-guided Deep Reinforcement Learning (DT-guided DRL), to address the inherent cold start problem in DRL. By integrating decision theory principles, DT-guided DRL enhances agents' initial performance and robustness in complex environments, enabling more efficient and reliable convergence during learning. Our investigation encompasses two primary problem contexts: the cart pole and maze navigation challenges. Experimental results demonstrate that the integration of decision theory not only facilitates effective initial guidance for DRL agents but also promotes a more structured and informed exploration strategy, particularly in environments characterized by large and intricate state spaces. The results of experiment demonstrate that DT-guided DRL can provide significantly higher rewards compared to regular DRL. Specifically, during the initial phase of training, the DT-guided DRL yields up to an 184% increase in accumulated reward. Moreover, even after reaching convergence, it maintains a superior performance, ending with up to 53% more reward than standard DRL in large maze problems. DT-guided DRL represents an advancement in mitigating a fundamental challenge of DRL by leveraging functions informed by human (designer) knowledge, setting a foundation for further research in this promising interdisciplinary domain.
Norm Enforcement with a Soft Touch: Faster Emergence, Happier Agents
Jan 29, 2024



A multiagent system can be viewed as a society of autonomous agents, whose interactions can be effectively regulated via social norms. In general, the norms of a society are not hardcoded but emerge from the agents' interactions. Specifically, how the agents in a society react to each other's behavior and respond to the reactions of others determines which norms emerge in the society. We think of these reactions by an agent to the satisfactory or unsatisfactory behaviors of another agent as communications from the first agent to the second agent. Understanding these communications is a kind of social intelligence: these communications provide natural drivers for norm emergence by pushing agents toward certain behaviors, which can become established as norms. Whereas it is well-known that sanctioning can lead to the emergence of norms, we posit that a broader kind of social intelligence can prove more effective in promoting cooperation in a multiagent system. Accordingly, we develop Nest, a framework that models social intelligence in the form of a wider variety of communications and understanding of them than in previous work. To evaluate Nest, we develop a simulated pandemic environment and conduct simulation experiments to compare Nest with baselines considering a combination of three kinds of social communication: sanction, tell, and hint. We find that societies formed of Nest agents achieve norms faster; moreover, Nest agents effectively avoid undesirable consequences, which are negative sanctions and deviation from goals, and yield higher satisfaction for themselves than baseline agents despite requiring only an equivalent amount of information.
Moral Judgments in Narratives on Reddit: Investigating Moral Sparks via Social Commonsense and Linguistic Signals
Oct 30, 2023
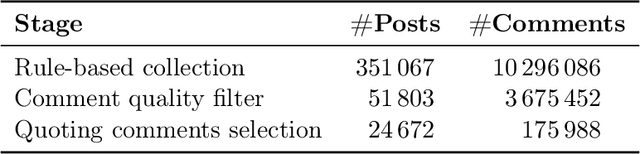
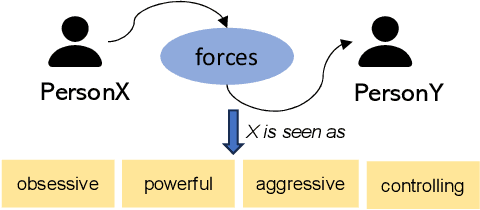

Given the increasing realism of social interactions online, social media offers an unprecedented avenue to evaluate real-life moral scenarios. We examine posts from Reddit, where authors and commenters share their moral judgments on who is blameworthy. We employ computational techniques to investigate factors influencing moral judgments, including (1) events activating social commonsense and (2) linguistic signals. To this end, we focus on excerpt-which we term moral sparks-from original posts that commenters include to indicate what motivates their moral judgments. By examining over 24,672 posts and 175,988 comments, we find that event-related negative personal traits (e.g., immature and rude) attract attention and stimulate blame, implying a dependent relationship between moral sparks and blameworthiness. Moreover, language that impacts commenters' cognitive processes to depict events and characters enhances the probability of an excerpt become a moral spark, while factual and concrete descriptions tend to inhibit this effect.