 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSiNES: Contrastive Siamese Network for Entity Standardization
Jun 05, 2023Entity standardization maps noisy mentions from free-form text to standard entities in a knowledge base. The unique challenge of this task relative to other entity-related tasks is the lack of surrounding context and numerous variations in the surface form of the mentions, especially when it comes to generalization across domains where labeled data is scarce. Previous research mostly focuses on developing models either heavily relying on context, or dedicated solely to a specific domain. In contrast, we propose CoSiNES, a generic and adaptable framework with Contrastive Siamese Network for Entity Standardization that effectively adapts a pretrained language model to capture the syntax and semantics of the entities in a new domain. We construct a new dataset in the technology domain, which contains 640 technical stack entities and 6,412 mentions collected from industrial content management systems. We demonstrate that CoSiNES yields higher accuracy and faster runtime than baselines derived from leading methods in this domain. CoSiNES also achieves competitive performance in four standard datasets from the chemistry, medicine, and biomedical domains, demonstrating its cross-domain applicability.
Project CodeNet: A Large-Scale AI for Code Dataset for Learning a Diversity of Coding Tasks
May 25, 2021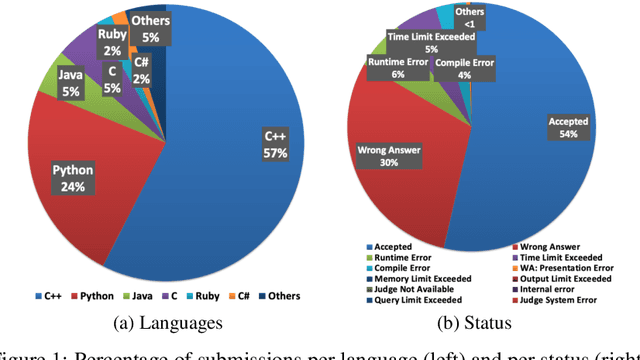
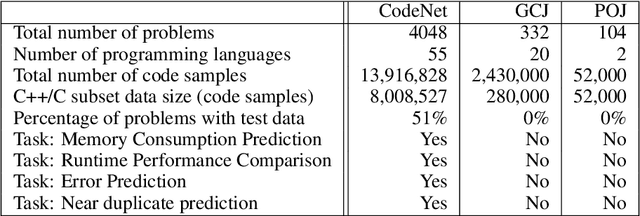
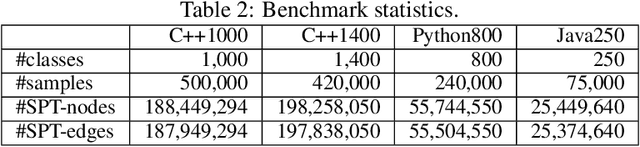
Advancements in deep learning and machine learning algorithms have enabled breakthrough progress in computer vision, speech recognition, natural language processing and beyond. In addition, over the last several decades, software has been built into the fabric of every aspect of our society. Together, these two trends have generated new interest in the fast-emerging research area of AI for Code. As software development becomes ubiquitous across all industries and code infrastructure of enterprise legacy applications ages, it is more critical than ever to increase software development productivity and modernize legacy applications. Over the last decade, datasets like ImageNet, with its large scale and diversity, have played a pivotal role in algorithmic advancements from computer vision to language and speech understanding. In this paper, we present Project CodeNet, a first-of-its-kind, very large scale, diverse, and high-quality dataset to accelerate the algorithmic advancements in AI for Code. It consists of 14M code samples and about 500M lines of code in 55 different programming languages. Project CodeNet is not only unique in its scale, but also in the diversity of coding tasks it can help benchmark: from code similarity and classification for advances in code recommendation algorithms, and code translation between a large variety programming languages, to advances in code performance (both runtime, and memory) improvement techniques. CodeNet also provides sample input and output test sets for over 7M code samples, which can be critical for determining code equivalence in different languages. As a usability feature, we provide several preprocessing tools in Project CodeNet to transform source codes into representations that can be readily used as inputs into machine learning models.
NeuNetS: An Automated Synthesis Engine for Neural Network Design
Jan 17, 2019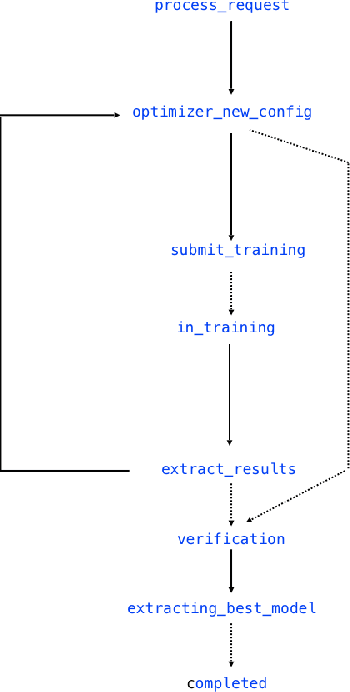
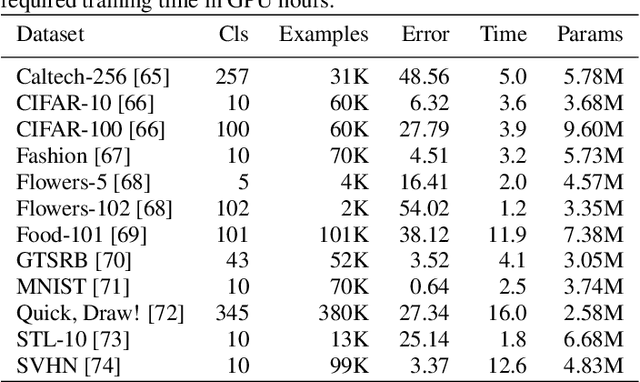
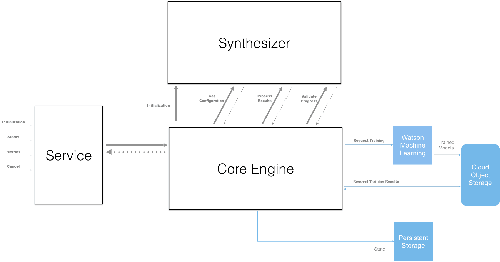
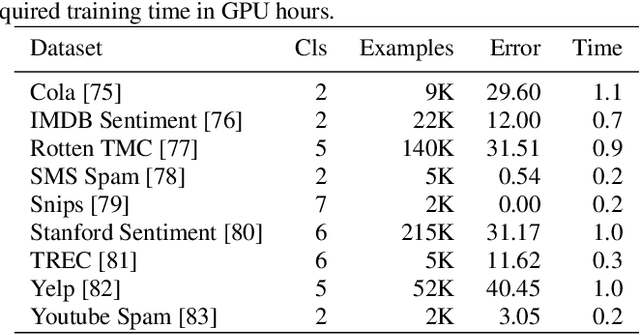
Application of neural networks to a vast variety of practical applications is transforming the way AI is applied in practice. Pre-trained neural network models available through APIs or capability to custom train pre-built neural network architectures with customer data has made the consumption of AI by developers much simpler and resulted in broad adoption of these complex AI models. While prebuilt network models exist for certain scenarios, to try and meet the constraints that are unique to each application, AI teams need to think about developing custom neural network architectures that can meet the tradeoff between accuracy and memory footprint to achieve the tight constraints of their unique use-cases. However, only a small proportion of data science teams have the skills and experience needed to create a neural network from scratch, and the demand far exceeds the supply. In this paper, we present NeuNetS : An automated Neural Network Synthesis engine for custom neural network design that is available as part of IBM's AI OpenScale's product. NeuNetS is available for both Text and Image domains and can build neural networks for specific tasks in a fraction of the time it takes today with human effort, and with accuracy similar to that of human-designed AI models.