 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRight vs. Right: Can LLMs Make Tough Choices?
Dec 27, 2024



An ethical dilemma describes a choice between two "right" options involving conflicting moral values. We present a comprehensive evaluation of how LLMs navigate ethical dilemmas. Specifically, we investigate LLMs on their (1) sensitivity in comprehending ethical dilemmas, (2) consistency in moral value choice, (3) consideration of consequences, and (4) ability to align their responses to a moral value preference explicitly or implicitly specified in a prompt. Drawing inspiration from a leading ethical framework, we construct a dataset comprising 1,730 ethical dilemmas involving four pairs of conflicting values. We evaluate 20 well-known LLMs from six families. Our experiments reveal that: (1) LLMs exhibit pronounced preferences between major value pairs, and prioritize truth over loyalty, community over individual, and long-term over short-term considerations. (2) The larger LLMs tend to support a deontological perspective, maintaining their choices of actions even when negative consequences are specified. (3) Explicit guidelines are more effective in guiding LLMs' moral choice than in-context examples. Lastly, our experiments highlight the limitation of LLMs in comprehending different formulations of ethical dilemmas.
Reasoner Outperforms: Generative Stance Detection with Rationalization for Social Media
Dec 13, 2024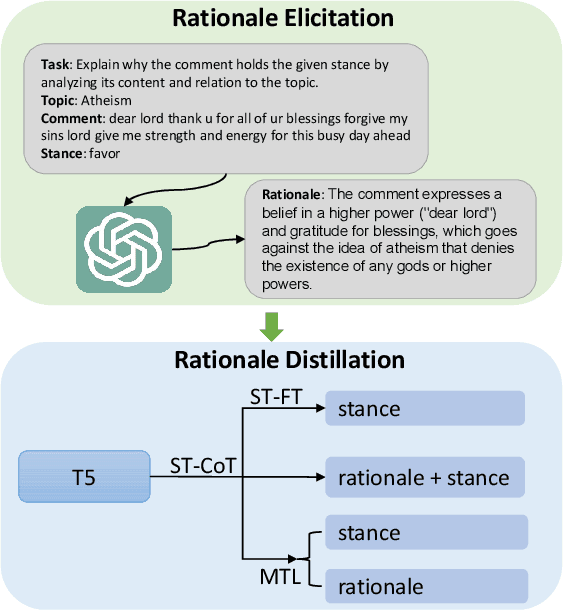

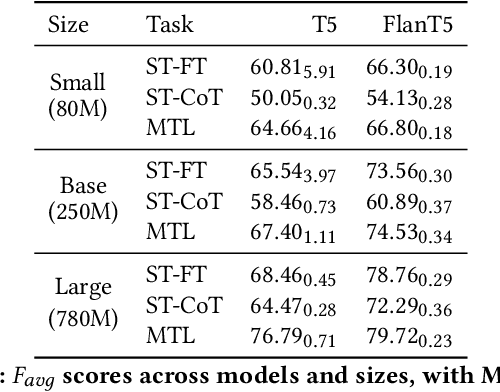
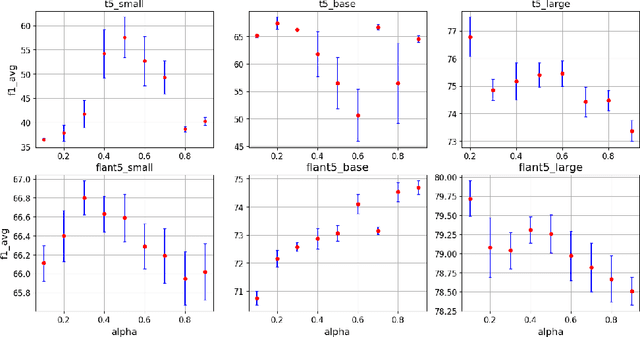
Stance detection is crucial for fostering a human-centric Web by analyzing user-generated content to identify biases and harmful narratives that undermine trust. With the development of Large Language Models (LLMs), existing approaches treat stance detection as a classification problem, providing robust methodologies for modeling complex group interactions and advancing capabilities in natural language tasks. However, these methods often lack interpretability, limiting their ability to offer transparent and understandable justifications for predictions. This study adopts a generative approach, where stance predictions include explicit, interpretable rationales, and integrates them into smaller language models through single-task and multitask learning. We find that incorporating reasoning into stance detection enables the smaller model (FlanT5) to outperform GPT-3.5's zero-shot performance, achieving an improvement of up to 9.57%. Moreover, our results show that reasoning capabilities enhance multitask learning performance but may reduce effectiveness in single-task settings. Crucially, we demonstrate that faithful rationales improve rationale distillation into SLMs, advancing efforts to build interpretable, trustworthy systems for addressing discrimination, fostering trust, and promoting equitable engagement on social media.
A Benchmark for Cross-Domain Argumentative Stance Classification on Social Media
Oct 11, 2024
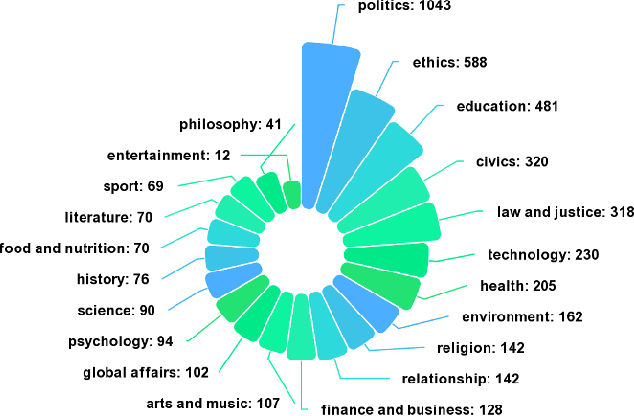
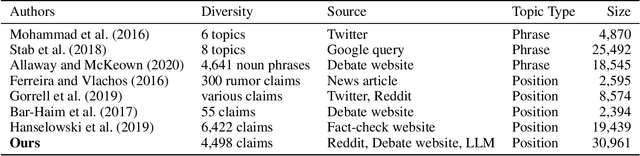

Argumentative stance classification plays a key role in identifying authors' viewpoints on specific topics. However, generating diverse pairs of argumentative sentences across various domains is challenging. Existing benchmarks often come from a single domain or focus on a limited set of topics. Additionally, manual annotation for accurate labeling is time-consuming and labor-intensive. To address these challenges, we propose leveraging platform rules, readily available expert-curated content, and large language models to bypass the need for human annotation. Our approach produces a multidomain benchmark comprising 4,498 topical claims and 30,961 arguments from three sources, spanning 21 domains. We benchmark the dataset in fully supervised, zero-shot, and few-shot settings, shedding light on the strengths and limitations of different methodologies. We release the dataset and code in this study at hidden for anonymity.
Towards a Holistic Evaluation of LLMs on Factual Knowledge Recall
Apr 24, 2024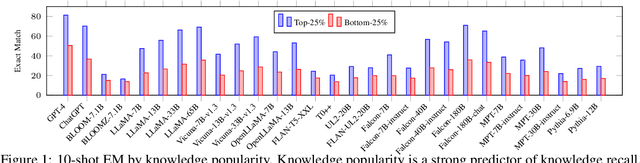



Large language models (LLMs) have shown remarkable performance on a variety of NLP tasks, and are being rapidly adopted in a wide range of use cases. It is therefore of vital importance to holistically evaluate the factuality of their generated outputs, as hallucinations remain a challenging issue. In this work, we focus on assessing LLMs' ability to recall factual knowledge learned from pretraining, and the factors that affect this ability. To that end, we construct FACT-BENCH, a representative benchmark covering 20 domains, 134 property types, 3 answer types, and different knowledge popularity levels. We benchmark 31 models from 10 model families and provide a holistic assessment of their strengths and weaknesses. We observe that instruction-tuning hurts knowledge recall, as pretraining-only models consistently outperform their instruction-tuned counterparts, and positive effects of model scaling, as larger models outperform smaller ones for all model families. However, the best performance from GPT-4 still represents a large gap with the upper-bound. We additionally study the role of in-context exemplars using counterfactual demonstrations, which lead to significant degradation of factual knowledge recall for large models. By further decoupling model known and unknown knowledge, we find the degradation is attributed to exemplars that contradict a model's known knowledge, as well as the number of such exemplars. Lastly, we fine-tune LLaMA-7B in different settings of known and unknown knowledge. In particular, fine-tuning on a model's known knowledge is beneficial, and consistently outperforms fine-tuning on unknown and mixed knowledge. We will make our benchmark publicly available.
CoSiNES: Contrastive Siamese Network for Entity Standardization
Jun 05, 2023Entity standardization maps noisy mentions from free-form text to standard entities in a knowledge base. The unique challenge of this task relative to other entity-related tasks is the lack of surrounding context and numerous variations in the surface form of the mentions, especially when it comes to generalization across domains where labeled data is scarce. Previous research mostly focuses on developing models either heavily relying on context, or dedicated solely to a specific domain. In contrast, we propose CoSiNES, a generic and adaptable framework with Contrastive Siamese Network for Entity Standardization that effectively adapts a pretrained language model to capture the syntax and semantics of the entities in a new domain. We construct a new dataset in the technology domain, which contains 640 technical stack entities and 6,412 mentions collected from industrial content management systems. We demonstrate that CoSiNES yields higher accuracy and faster runtime than baselines derived from leading methods in this domain. CoSiNES also achieves competitive performance in four standard datasets from the chemistry, medicine, and biomedical domains, demonstrating its cross-domain applicability.
Conversation Modeling to Predict Derailment
Mar 20, 2023Conversations among online users sometimes derail, i.e., break down into personal attacks. Such derailment has a negative impact on the healthy growth of cyberspace communities. The ability to predict whether ongoing conversations are likely to derail could provide valuable real-time insight to interlocutors and moderators. Prior approaches predict conversation derailment retrospectively without the ability to forestall the derailment proactively. Some works attempt to make dynamic prediction as the conversation develops, but fail to incorporate multisource information, such as conversation structure and distance to derailment. We propose a hierarchical transformer-based framework that combines utterance-level and conversation-level information to capture fine-grained contextual semantics. We propose a domain-adaptive pretraining objective to integrate conversational structure information and a multitask learning scheme to leverage the distance from each utterance to derailment. An evaluation of our framework on two conversation derailment datasets yields improvement over F1 score for the prediction of derailment. These results demonstrate the effectiveness of incorporating multisource information.
Extracting Incidents, Effects, and Requested Advice from MeToo Posts
Mar 19, 2023



Survivors of sexual harassment frequently share their experiences on social media, revealing their feelings and emotions and seeking advice. We observed that on Reddit, survivors regularly share long posts that describe a combination of (i) a sexual harassment incident, (ii) its effect on the survivor, including their feelings and emotions, and (iii) the advice being sought. We term such posts MeToo posts, even though they may not be so tagged and may appear in diverse subreddits. A prospective helper (such as a counselor or even a casual reader) must understand a survivor's needs from such posts. But long posts can be time-consuming to read and respond to. Accordingly, we address the problem of extracting key information from a long MeToo post. We develop a natural language-based model to identify sentences from a post that describe any of the above three categories. On ten-fold cross-validation of a dataset, our model achieves a macro F1 score of 0.82. In addition, we contribute MeThree, a dataset comprising 8,947 labeled sentences extracted from Reddit posts. We apply the LIWC-22 toolkit on MeThree to understand how different language patterns in sentences of the three categories can reveal differences in emotional tone, authenticity, and other aspects.