 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Cross-Domain Argumentative Stance Classification on Social Media
Paper and Code
Oct 11, 2024
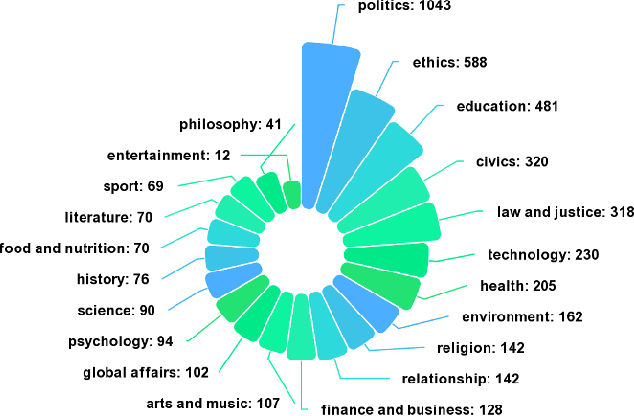
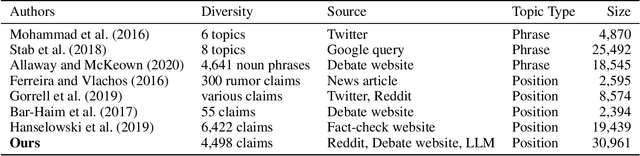

Argumentative stance classification plays a key role in identifying authors' viewpoints on specific topics. However, generating diverse pairs of argumentative sentences across various domains is challenging. Existing benchmarks often come from a single domain or focus on a limited set of topics. Additionally, manual annotation for accurate labeling is time-consuming and labor-intensive. To address these challenges, we propose leveraging platform rules, readily available expert-curated content, and large language models to bypass the need for human annotation. Our approach produces a multidomain benchmark comprising 4,498 topical claims and 30,961 arguments from three sources, spanning 21 domains. We benchmark the dataset in fully supervised, zero-shot, and few-shot settings, shedding light on the strengths and limitations of different methodologies. We release the dataset and code in this study at hidden for anonymity.