 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAug2Search: Enhancing Facebook Marketplace Search with LLM-Generated Synthetic Data Augmentation
May 21, 2025Embedding-Based Retrieval (EBR) is an important technique in modern search engines, enabling semantic match between search queries and relevant results. However, search logging data on platforms like Facebook Marketplace lacks the diversity and details needed for effective EBR model training, limiting the models' ability to capture nuanced search patterns. To address this challenge, we propose Aug2Search, an EBR-based framework leveraging synthetic data generated by Generative AI (GenAI) models, in a multimodal and multitask approach to optimize query-product relevance. This paper investigates the capabilities of GenAI, particularly Large Language Models (LLMs), in generating high-quality synthetic data, and analyzing its impact on enhancing EBR models. We conducted experiments using eight Llama models and 100 million data points from Facebook Marketplace logs. Our synthetic data generation follows three strategies: (1) generate queries, (2) enhance product listings, and (3) generate queries from enhanced listings. We train EBR models on three different datasets: sampled engagement data or original data ((e.g., "Click" and "Listing Interactions")), synthetic data, and a mixture of both engagement and synthetic data to assess their performance across various training sets. Our findings underscore the robustness of Llama models in producing synthetic queries and listings with high coherence, relevance, and diversity, while maintaining low levels of hallucination. Aug2Search achieves an improvement of up to 4% in ROC_AUC with 100 million synthetic data samples, demonstrating the effectiveness of our approach. Moreover, our experiments reveal that with the same volume of training data, models trained exclusively on synthetic data often outperform those trained on original data only or a mixture of original and synthetic data.
Reasoner Outperforms: Generative Stance Detection with Rationalization for Social Media
Dec 13, 2024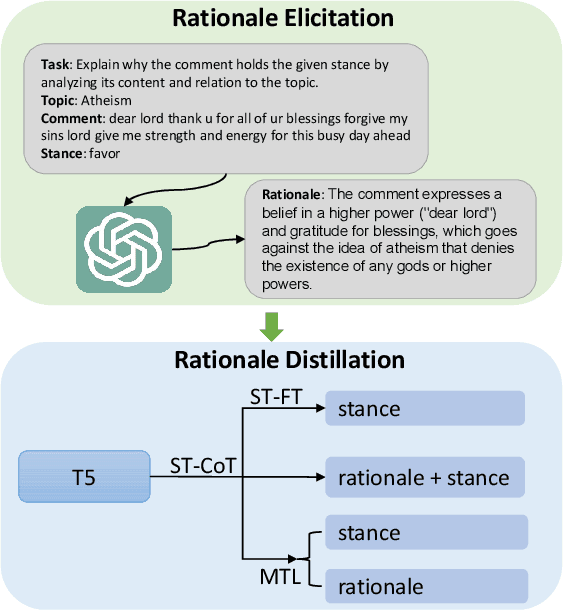

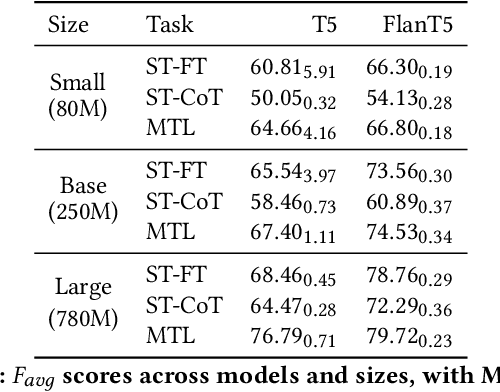
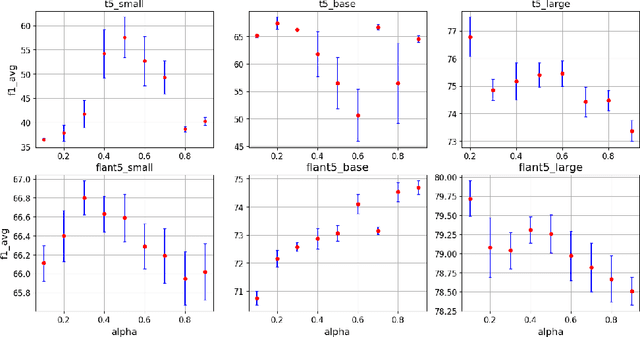
Stance detection is crucial for fostering a human-centric Web by analyzing user-generated content to identify biases and harmful narratives that undermine trust. With the development of Large Language Models (LLMs), existing approaches treat stance detection as a classification problem, providing robust methodologies for modeling complex group interactions and advancing capabilities in natural language tasks. However, these methods often lack interpretability, limiting their ability to offer transparent and understandable justifications for predictions. This study adopts a generative approach, where stance predictions include explicit, interpretable rationales, and integrates them into smaller language models through single-task and multitask learning. We find that incorporating reasoning into stance detection enables the smaller model (FlanT5) to outperform GPT-3.5's zero-shot performance, achieving an improvement of up to 9.57%. Moreover, our results show that reasoning capabilities enhance multitask learning performance but may reduce effectiveness in single-task settings. Crucially, we demonstrate that faithful rationales improve rationale distillation into SLMs, advancing efforts to build interpretable, trustworthy systems for addressing discrimination, fostering trust, and promoting equitable engagement on social media.
A Benchmark for Cross-Domain Argumentative Stance Classification on Social Media
Oct 11, 2024
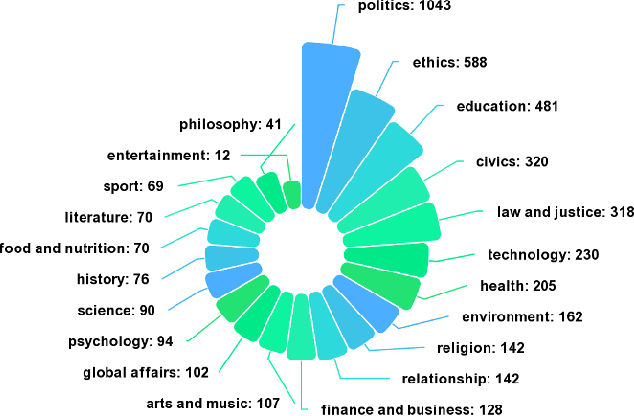
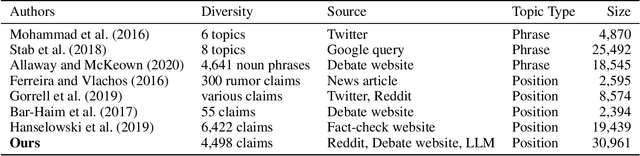

Argumentative stance classification plays a key role in identifying authors' viewpoints on specific topics. However, generating diverse pairs of argumentative sentences across various domains is challenging. Existing benchmarks often come from a single domain or focus on a limited set of topics. Additionally, manual annotation for accurate labeling is time-consuming and labor-intensive. To address these challenges, we propose leveraging platform rules, readily available expert-curated content, and large language models to bypass the need for human annotation. Our approach produces a multidomain benchmark comprising 4,498 topical claims and 30,961 arguments from three sources, spanning 21 domains. We benchmark the dataset in fully supervised, zero-shot, and few-shot settings, shedding light on the strengths and limitations of different methodologies. We release the dataset and code in this study at hidden for anonymity.
Moral Judgments in Narratives on Reddit: Investigating Moral Sparks via Social Commonsense and Linguistic Signals
Oct 30, 2023
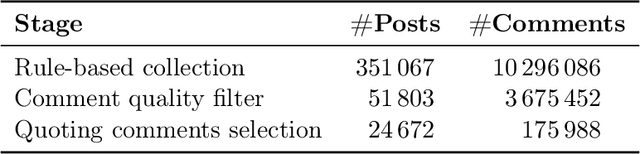
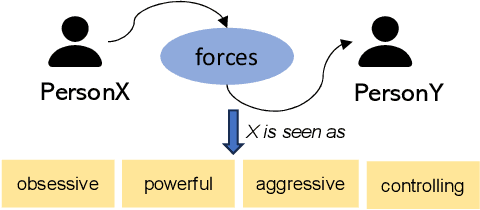

Given the increasing realism of social interactions online, social media offers an unprecedented avenue to evaluate real-life moral scenarios. We examine posts from Reddit, where authors and commenters share their moral judgments on who is blameworthy. We employ computational techniques to investigate factors influencing moral judgments, including (1) events activating social commonsense and (2) linguistic signals. To this end, we focus on excerpt-which we term moral sparks-from original posts that commenters include to indicate what motivates their moral judgments. By examining over 24,672 posts and 175,988 comments, we find that event-related negative personal traits (e.g., immature and rude) attract attention and stimulate blame, implying a dependent relationship between moral sparks and blameworthiness. Moreover, language that impacts commenters' cognitive processes to depict events and characters enhances the probability of an excerpt become a moral spark, while factual and concrete descriptions tend to inhibit this effect.