 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAug2Search: Enhancing Facebook Marketplace Search with LLM-Generated Synthetic Data Augmentation
May 21, 2025Embedding-Based Retrieval (EBR) is an important technique in modern search engines, enabling semantic match between search queries and relevant results. However, search logging data on platforms like Facebook Marketplace lacks the diversity and details needed for effective EBR model training, limiting the models' ability to capture nuanced search patterns. To address this challenge, we propose Aug2Search, an EBR-based framework leveraging synthetic data generated by Generative AI (GenAI) models, in a multimodal and multitask approach to optimize query-product relevance. This paper investigates the capabilities of GenAI, particularly Large Language Models (LLMs), in generating high-quality synthetic data, and analyzing its impact on enhancing EBR models. We conducted experiments using eight Llama models and 100 million data points from Facebook Marketplace logs. Our synthetic data generation follows three strategies: (1) generate queries, (2) enhance product listings, and (3) generate queries from enhanced listings. We train EBR models on three different datasets: sampled engagement data or original data ((e.g., "Click" and "Listing Interactions")), synthetic data, and a mixture of both engagement and synthetic data to assess their performance across various training sets. Our findings underscore the robustness of Llama models in producing synthetic queries and listings with high coherence, relevance, and diversity, while maintaining low levels of hallucination. Aug2Search achieves an improvement of up to 4% in ROC_AUC with 100 million synthetic data samples, demonstrating the effectiveness of our approach. Moreover, our experiments reveal that with the same volume of training data, models trained exclusively on synthetic data often outperform those trained on original data only or a mixture of original and synthetic data.
Bi-directional Momentum-based Haptic Feedback and Control System for Dexterous Telemanipulation
Sep 30, 2024
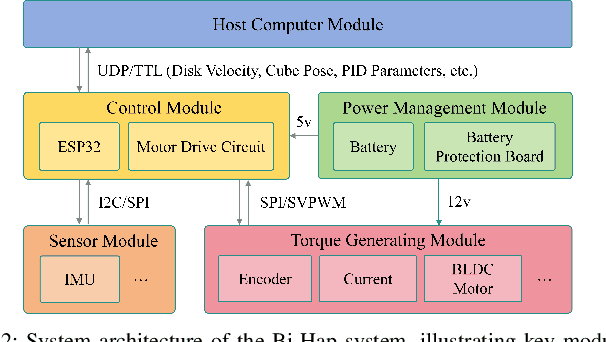


Haptic feedback is essential for dexterous telemanipulation that enables operators to control robotic hands remotely with high skill and precision, mimicking a human hand's natural movement and sensation. However, current haptic methods for dexterous telemanipulation cannot support torque feedback, resulting in object rotation and rolling mismatches. The operator must make tedious adjustments in these tasks, leading to delays, reduced situational awareness, and suboptimal task performance. This work presents a Bi-directional Momentum-based Haptic Feedback and Control (Bi-Hap) system for real-time dexterous telemanipulation. Bi-Hap integrates multi-modal sensors to extract human interactive information with the object and share it with the robot's learning-based controller. A Field-Oriented Control (FOC) algorithm is developed to enable the integrated brushless active momentum wheel to generate precise torque and vibrative feedback, bridging the gap between human intent and robotic actions. Different feedback strategies are designed for varying error states to align with the operator's intuition. Extensive experiments with human subjects using a virtual Shadow Dexterous Hand demonstrate the effectiveness of Bi-Hap in enhancing task performance and user confidence. Bi-Hap achieved real-time feedback capability with low command following latency (delay<0.025s) and highly accurate torque feedback (RMSE<0.010 Nm).
Critic PI2: Master Continuous Planning via Policy Improvement with Path Integrals and Deep Actor-Critic Reinforcement Learning
Nov 13, 2020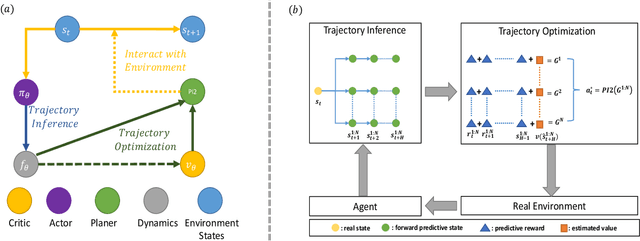
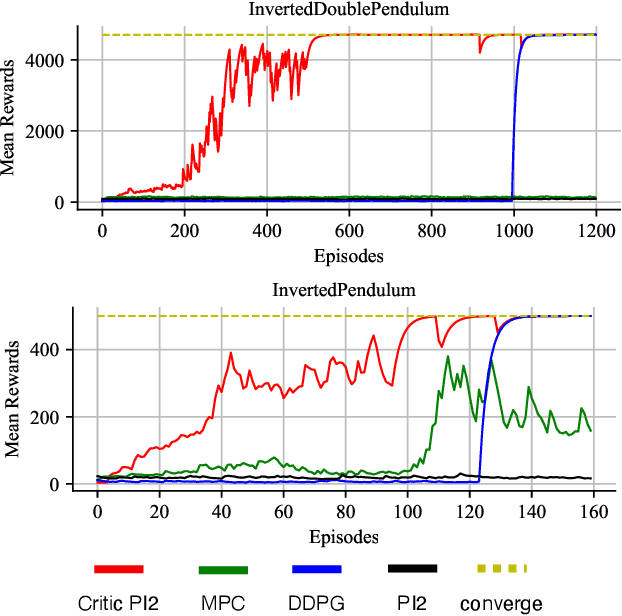
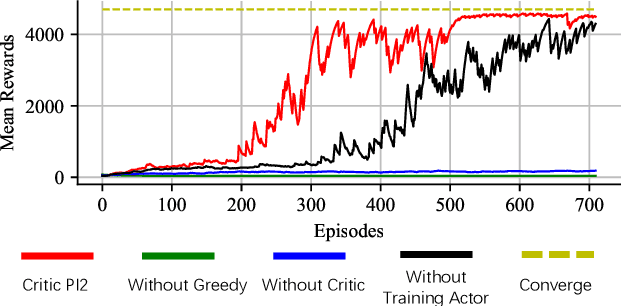
Constructing agents with planning capabilities has long been one of the main challenges in the pursuit of artificial intelligence. Tree-based planning methods from AlphaGo to Muzero have enjoyed huge success in discrete domains, such as chess and Go. Unfortunately, in real-world applications like robot control and inverted pendulum, whose action space is normally continuous, those tree-based planning techniques will be struggling. To address those limitations, in this paper, we present a novel model-based reinforcement learning frameworks called Critic PI2, which combines the benefits from trajectory optimization, deep actor-critic learning, and model-based reinforcement learning. Our method is evaluated for inverted pendulum models with applicability to many continuous control systems. Extensive experiments demonstrate that Critic PI2 achieved a new state of the art in a range of challenging continuous domains. Furthermore, we show that planning with a critic significantly increases the sample efficiency and real-time performance. Our work opens a new direction toward learning the components of a model-based planning system and how to use them.