 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapability Thresholds and Manufacturing Topology: How Embodied Intelligence Triggers Phase Transitions in Economic Geography
Mar 03, 2026The fundamental topology of manufacturing has not undergone a paradigm-level transformation since Henry Ford's moving assembly line in 1913. Every major innovation of the past century, from the Toyota Production System to Industry 4.0, has optimized within the Fordist paradigm without altering its structural logic: centralized mega-factories, located near labor pools, producing at scale. We argue that embodied intelligence is poised to break this century-long stasis, not by making existing factories more efficient, but by triggering phase transitions in manufacturing economic geography itself. When embodied AI capabilities cross critical thresholds in dexterity, generalization, reliability, and tactile-vision fusion, the consequences extend far beyond cost reduction: they restructure where factories are built, how supply chains are organized, and what constitutes viable production scale. We formalize this by defining a Capability Space C = (d, g, r, t) and showing that the site-selection objective function undergoes topological reorganization when capability vectors cross critical surfaces. Through three pathways, weight inversion, batch collapse, and human-infrastructure decoupling, we show that embodied intelligence enables demand-proximal micro-manufacturing, eliminates "manufacturing deserts," and reverses geographic concentration driven by labor arbitrage. We further introduce Machine Climate Advantage: once human workers are removed, optimal factory locations are determined by machine-optimal conditions (low humidity, high irradiance, thermal stability), factors orthogonal to traditional siting logic, creating a production geography with no historical precedent. This paper establishes Embodied Intelligence Economics, the study of how physical AI capability thresholds reshape the spatial and structural logic of production.
Closer to Language than Steam: AI as the Cognitive Engine of a New Productivity Revolution
Jun 12, 2025Artificial Intelligence (AI) is reframed as a cognitive engine driving a novel productivity revolution distinct from the Industrial Revolution's physical thrust. This paper develops a theoretical framing of AI as a cognitive revolution akin to written language - a transformative augmentation of human intellect rather than another mechanized tool. We compare AI's emergence to historical leaps in information technology to show how it amplifies knowledge work. Examples from various domains demonstrate AI's impact as a driver of productivity in cognitive tasks. We adopt a multidisciplinary perspective combining computer science advances with economic insights and sociological perspectives on how AI reshapes work and society. Through conceptual frameworks, we visualize the shift from manual to cognitive productivity. Our central argument is that AI functions as an engine of cognition - comparable to how human language revolutionized knowledge - heralding a new productivity paradigm. We discuss how this revolution demands rethinking of skills, organizations, and policies. This paper, balancing academic rigor with clarity, concludes that AI's promise lies in complementing human cognitive abilities, marking a new chapter in productivity evolution.
Anchoring AI Capabilities in Market Valuations: The Capability Realization Rate Model and Valuation Misalignment Risk
May 15, 2025Recent breakthroughs in artificial intelligence (AI) have triggered surges in market valuations for AI-related companies, often outpacing the realization of underlying capabilities. We examine the anchoring effect of AI capabilities on equity valuations and propose a Capability Realization Rate (CRR) model to quantify the gap between AI potential and realized performance. Using data from the 2023--2025 generative AI boom, we analyze sector-level sensitivity and conduct case studies (OpenAI, Adobe, NVIDIA, Meta, Microsoft, Goldman Sachs) to illustrate patterns of valuation premium and misalignment. Our findings indicate that AI-native firms commanded outsized valuation premiums anchored to future potential, while traditional companies integrating AI experienced re-ratings subject to proof of tangible returns. We argue that CRR can help identify valuation misalignment risk-where market prices diverge from realized AI-driven value. We conclude with policy recommendations to improve transparency, mitigate speculative bubbles, and align AI innovation with sustainable market value.
Adaptive Anomaly Recovery for Telemanipulation: A Diffusion Model Approach to Vision-Based Tracking
Mar 11, 2025



Dexterous telemanipulation critically relies on the continuous and stable tracking of the human operator's commands to ensure robust operation. Vison-based tracking methods are widely used but have low stability due to anomalies such as occlusions, inadequate lighting, and loss of sight. Traditional filtering, regression, and interpolation methods are commonly used to compensate for explicit information such as angles and positions. These approaches are restricted to low-dimensional data and often result in information loss compared to the original high-dimensional image and video data. Recent advances in diffusion-based approaches, which can operate on high-dimensional data, have achieved remarkable success in video reconstruction and generation. However, these methods have not been fully explored in continuous control tasks in robotics. This work introduces the Diffusion-Enhanced Telemanipulation (DET) framework, which incorporates the Frame-Difference Detection (FDD) technique to identify and segment anomalies in video streams. These anomalous clips are replaced after reconstruction using diffusion models, ensuring robust telemanipulation performance under challenging visual conditions. We validated this approach in various anomaly scenarios and compared it with the baseline methods. Experiments show that DET achieves an average RMSE reduction of 17.2% compared to the cubic spline and 51.1% compared to FFT-based interpolation for different occlusion durations.
Bio-Skin: A Cost-Effective Thermostatic Tactile Sensor with Multi-Modal Force and Temperature Detection
Mar 11, 2025
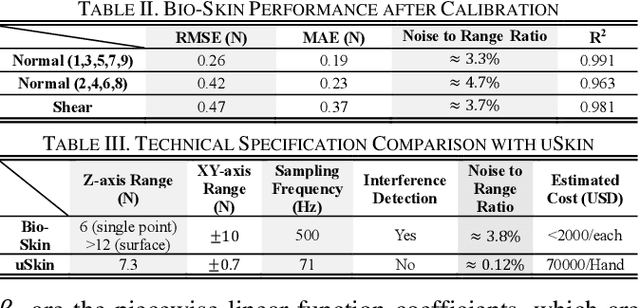

Tactile sensors can significantly enhance the perception of humanoid robotics systems by providing contact information that facilitates human-like interactions. However, existing commercial tactile sensors focus on improving the resolution and sensitivity of single-modal detection with high-cost components and densely integrated design, incurring complex manufacturing processes and unaffordable prices. In this work, we present Bio-Skin, a cost-effective multi-modal tactile sensor that utilizes single-axis Hall-effect sensors for planar normal force measurement and bar-shape piezo resistors for 2D shear force measurement. A thermistor coupling with a heating wire is integrated into a silicone body to achieve temperature sensation and thermostatic function analogous to human skin. We also present a cross-reference framework to validate the two modalities of the force sensing signal, improving the sensing fidelity in a complex electromagnetic environment. Bio-Skin has a multi-layer design, and each layer is manufactured sequentially and subsequently integrated, thereby offering a fast production pathway. After calibration, Bio-Skin demonstrates performance metrics-including signal-to-range ratio, sampling rate, and measurement range-comparable to current commercial products, with one-tenth of the cost. The sensor's real-world performance is evaluated using an Allegro hand in object grasping tasks, while its temperature regulation functionality was assessed in a material detection task.
Impact of Tactile Sensor Quantities and Placements on Learning-based Dexterous Manipulation
Sep 30, 2024



Tactile information effectively enables faster training and better task performance for learning-based in-hand manipulation. Existing approaches are validated in simulated environments with a large number of tactile sensors. However, attaching such sensors to a real robot hand is not applicable due to high cost and physical limitations. To enable real-world adoption of tactile sensors, this study investigates the impact of tactile sensors, including their varying quantities and placements on robot hands, on the dexterous manipulation task performance and analyzes the importance of each. Through empirically decreasing the sensor quantities, we successfully find an optimized set of tactile sensors (21 sensors) configuration, which keeps over 93% task performance with only 20% sensor quantities compared to the original set (92 sensors) for the block manipulation task, leading to a potential reduction of over 80% in sensor manufacturing and design costs. To transform the empirical results into a generalizable understanding, we build a task performance prediction model with a weighted linear regression algorithm and use it to forecast the task performance with different sensor configurations. To show its generalizability, we verified this model in egg and pen manipulation tasks and achieved an average prediction error of 3.12%.
Bi-directional Momentum-based Haptic Feedback and Control System for Dexterous Telemanipulation
Sep 30, 2024
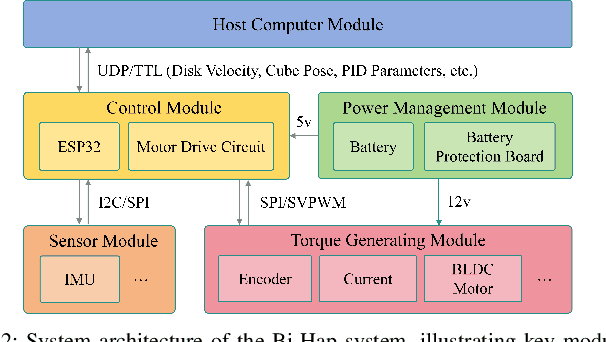


Haptic feedback is essential for dexterous telemanipulation that enables operators to control robotic hands remotely with high skill and precision, mimicking a human hand's natural movement and sensation. However, current haptic methods for dexterous telemanipulation cannot support torque feedback, resulting in object rotation and rolling mismatches. The operator must make tedious adjustments in these tasks, leading to delays, reduced situational awareness, and suboptimal task performance. This work presents a Bi-directional Momentum-based Haptic Feedback and Control (Bi-Hap) system for real-time dexterous telemanipulation. Bi-Hap integrates multi-modal sensors to extract human interactive information with the object and share it with the robot's learning-based controller. A Field-Oriented Control (FOC) algorithm is developed to enable the integrated brushless active momentum wheel to generate precise torque and vibrative feedback, bridging the gap between human intent and robotic actions. Different feedback strategies are designed for varying error states to align with the operator's intuition. Extensive experiments with human subjects using a virtual Shadow Dexterous Hand demonstrate the effectiveness of Bi-Hap in enhancing task performance and user confidence. Bi-Hap achieved real-time feedback capability with low command following latency (delay<0.025s) and highly accurate torque feedback (RMSE<0.010 Nm).
Real-time Dexterous Telemanipulation with an End-Effect-Oriented Learning-based Approach
Aug 01, 2024



Dexterous telemanipulation is crucial in advancing human-robot systems, especially in tasks requiring precise and safe manipulation. However, it faces significant challenges due to the physical differences between human and robotic hands, the dynamic interaction with objects, and the indirect control and perception of the remote environment. Current approaches predominantly focus on mapping the human hand onto robotic counterparts to replicate motions, which exhibits a critical oversight: it often neglects the physical interaction with objects and relegates the interaction burden to the human to adapt and make laborious adjustments in response to the indirect and counter-intuitive observation of the remote environment. This work develops an End-Effects-Oriented Learning-based Dexterous Telemanipulation (EFOLD) framework to address telemanipulation tasks. EFOLD models telemanipulation as a Markov Game, introducing multiple end-effect features to interpret the human operator's commands during interaction with objects. These features are used by a Deep Reinforcement Learning policy to control the robot and reproduce such end effects. EFOLD was evaluated with real human subjects and two end-effect extraction methods for controlling a virtual Shadow Robot Hand in telemanipulation tasks. EFOLD achieved real-time control capability with low command following latency (delay<0.11s) and highly accurate tracking (MSE<0.084 rad).
Stable In-hand Manipulation with Finger Specific Multi-agent Shadow Reward
Sep 13, 2023



Deep Reinforcement Learning has shown its capability to solve the high degrees of freedom in control and the complex interaction with the object in the multi-finger dexterous in-hand manipulation tasks. Current DRL approaches prefer sparse rewards to dense rewards for the ease of training but lack behavior constraints during the manipulation process, leading to aggressive and unstable policies that are insufficient for safety-critical in-hand manipulation tasks. Dense rewards can regulate the policy to learn stable manipulation behaviors with continuous reward constraints but are hard to empirically define and slow to converge optimally. This work proposes the Finger-specific Multi-agent Shadow Reward (FMSR) method to determine the stable manipulation constraints in the form of dense reward based on the state-action occupancy measure, a general utility of DRL that is approximated during the learning process. Information Sharing (IS) across neighboring agents enables consensus training to accelerate the convergence. The methods are evaluated in two in-hand manipulation tasks on the Shadow Hand. The results show FMSR+IS converges faster in training, achieving a higher task success rate and better manipulation stability than conventional dense reward. The comparison indicates FMSR+IS achieves a comparable success rate even with the behavior constraint but much better manipulation stability than the policy trained with a sparse reward.
Curriculum-based Sensing Reduction in Simulation to Real-World Transfer for In-hand Manipulation
Sep 13, 2023



Simulation to Real-World Transfer allows affordable and fast training of learning-based robots for manipulation tasks using Deep Reinforcement Learning methods. Currently, Sim2Real uses Asymmetric Actor-Critic approaches to reduce the rich idealized features in simulation to the accessible ones in the real world. However, the feature reduction from the simulation to the real world is conducted through an empirically defined one-step curtail. Small feature reduction does not sufficiently remove the actor's features, which may still cause difficulty setting up the physical system, while large feature reduction may cause difficulty and inefficiency in training. To address this issue, we proposed Curriculum-based Sensing Reduction to enable the actor to start with the same rich feature space as the critic and then get rid of the hard-to-extract features step-by-step for higher training performance and better adaptation for real-world feature space. The reduced features are replaced with random signals from a Deep Random Generator to remove the dependency between the output and the removed features and avoid creating new dependencies. The methods are evaluated on the Allegro robot hand in a real-world in-hand manipulation task. The results show that our methods have faster training and higher task performance than baselines and can solve real-world tasks when selected tactile features are reduced.