 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-Aware Uncertainty Evaluation of Vision-Language Model-Based Early Action Anticipation for Human-Robot Interaction
Mar 12, 2026Robots in shared workspaces must interpret human actions from partial, ambiguous observations, where overconfident early predictions can lead to unsafe or disruptive interaction. This challenge is amplified in egocentric views, where viewpoint changes and occlusions increase perceptual noise and ambiguity. As a result, downstream human-robot interaction modules require not only an action hypothesis but also a trustworthy estimate of confidence under partial observation. Recent vision-language model-based approaches have been proposed for short-term action recognition due to their open-vocabulary and context-aware reasoning, but their uncertainty reliability in the temporal-prefix regime is largely uncharacterized. We present the first systematic evaluation of uncertainty in vision-language model-based short-term action recognition for human-robot interaction. We introduce a temporal-prefix evaluation protocol and metrics for calibration and selective prediction. We also characterize miscalibration patterns and failure modes under partial observations. Our study provides the missing reliability evidence needed to use vision-language model predictions in confidence-gated human-robot interaction modules.
Human Motion Intent Inferencing in Teleoperation Through a SINDy Paradigm
Nov 11, 2025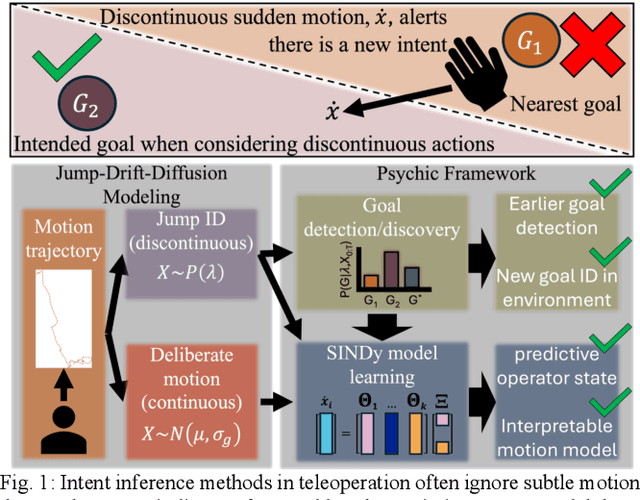
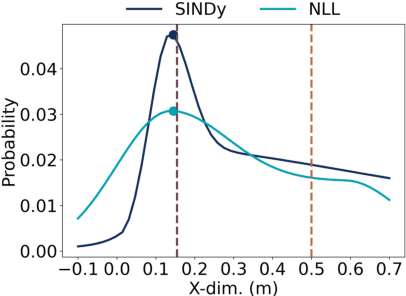
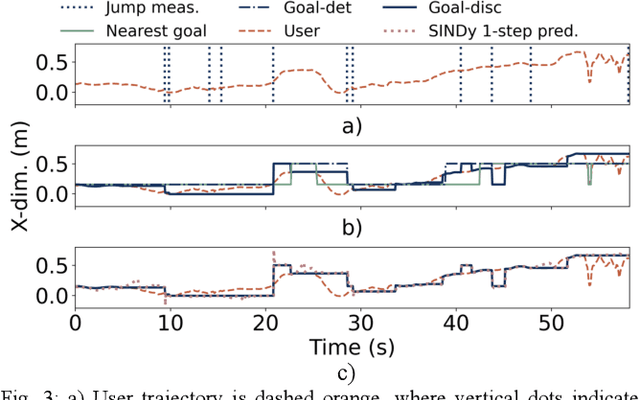
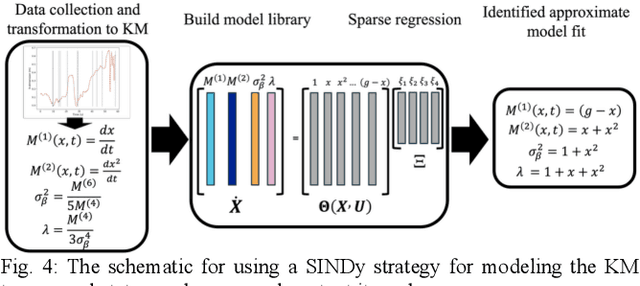
Intent inferencing in teleoperation has been instrumental in aligning operator goals and coordinating actions with robotic partners. However, current intent inference methods often ignore subtle motion that can be strong indicators for a sudden change in intent. Specifically, we aim to tackle 1) if we can detect sudden jumps in operator trajectories, 2) how we appropriately use these sudden jump motions to infer an operator's goal state, and 3) how to incorporate these discontinuous and continuous dynamics to infer operator motion. Our framework, called Psychic, models these small indicative motions through a jump-drift-diffusion stochastic differential equation to cover discontinuous and continuous dynamics. Kramers-Moyal (KM) coefficients allow us to detect jumps with a trajectory which we pair with a statistical outlier detection algorithm to nominate goal transitions. Through identifying jumps, we can perform early detection of existing goals and discover undefined goals in unstructured scenarios. Our framework then applies a Sparse Identification of Nonlinear Dynamics (SINDy) model using KM coefficients with the goal transitions as a control input to infer an operator's motion behavior in unstructured scenarios. We demonstrate Psychic can produce probabilistic reachability sets and compare our strategy to a negative log-likelihood model fit. We perform a retrospective study on 600 operator trajectories in a hands-free teleoperation task to evaluate the efficacy of our opensource package, Psychic, in both offline and online learning.
The Use of Gaze-Derived Confidence of Inferred Operator Intent in Adjusting Safety-Conscious Haptic Assistance
Apr 04, 2025Humans directly completing tasks in dangerous or hazardous conditions is not always possible where these tasks are increasingly be performed remotely by teleoperated robots. However, teleoperation is difficult since the operator feels a disconnect with the robot caused by missing feedback from several senses, including touch, and the lack of depth in the video feedback presented to the operator. To overcome this problem, the proposed system actively infers the operator's intent and provides assistance based on the predicted intent. Furthermore, a novel method of calculating confidence in the inferred intent modifies the human-in-the-loop control. The operator's gaze is employed to intuitively indicate the target before the manipulation with the robot begins. A potential field method is used to provide a guiding force towards the intended target, and a safety boundary reduces risk of damage. Modifying these assistances based on the confidence level in the operator's intent makes the control more natural, and gives the robot an intuitive understanding of its human master. Initial validation results show the ability of the system to improve accuracy, execution time, and reduce operator error.
Transferability-based Chain Motion Mapping from Humans to Humanoids for Teleoperation
Oct 28, 2022



Although data-driven motion mapping methods are promising to allow intuitive robot control and teleoperation that generate human-like robot movement, they normally require tedious pair-wise training for each specific human and robot pair. This paper proposes a transferability-based mapping scheme to allow new robot and human input systems to leverage the mapping of existing trained pairs to form a mapping transfer chain, which will reduce the number of new pair-specific mappings that need to be generated. The first part of the mapping schematic is the development of a Synergy Mapping via Dual-Autoencoder (SyDa) method. This method uses the latent features from two autoencoders to extract the common synergy of the two agents. Secondly, a transferability metric is created that approximates how well the mapping between a pair of agents will perform compared to another pair before creating the motion mapping models. Thus, it can guide the formation of an optimal mapping chain for the new human-robot pair. Experiments with human subjects and a Pepper robot demonstrated 1) The SyDa method improves the accuracy and generalizability of the pair mappings, 2) the SyDa method allows for bidirectional mapping that does not prioritize the direction of mapping motion, and 3) the transferability metric measures how compatible two agents are for accurate teleoperation. The combination of the SyDa method and transferability metric creates generalizable and accurate mapping need to create the transfer mapping chain.
A Multi-Agent Approach for Adaptive Finger Cooperation in Learning-based In-Hand Manipulation
Oct 11, 2022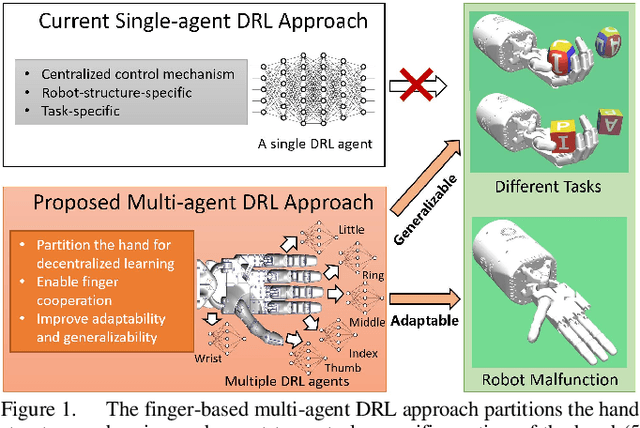
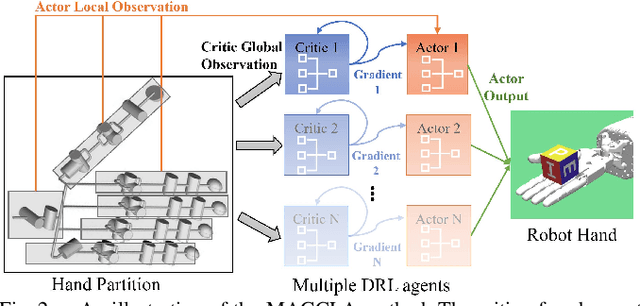
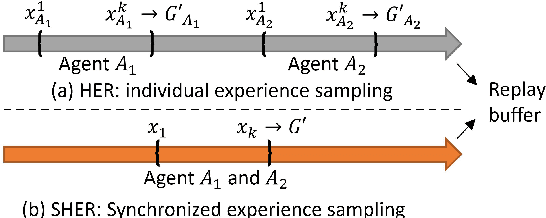
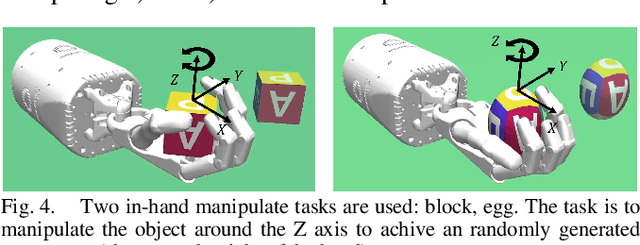
In-hand manipulation is challenging for a multi-finger robotic hand due to its high degrees of freedom and the complex interaction with the object. To enable in-hand manipulation, existing deep reinforcement learning based approaches mainly focus on training a single robot-structure-specific policy through the centralized learning mechanism, lacking adaptability to changes like robot malfunction. To solve this limitation, this work treats each finger as an individual agent and trains multiple agents to control their assigned fingers to complete the in-hand manipulation task cooperatively. We propose the Multi-Agent Global-Observation Critic and Local-Observation Actor (MAGCLA) method, where the critic can observe all agents' actions globally, and the actor only locally observes its neighbors' actions. Besides, conventional individual experience replay may cause unstable cooperation due to the asynchronous performance increment of each agent, which is critical for in-hand manipulation tasks. To solve this issue, we propose the Synchronized Hindsight Experience Replay (SHER) method to synchronize and efficiently reuse the replayed experience across all agents. The methods are evaluated in two in-hand manipulation tasks on the Shadow dexterous hand. The results show that SHER helps MAGCLA achieve comparable learning efficiency to a single policy, and the MAGCLA approach is more generalizable in different tasks. The trained policies have higher adaptability in the robot malfunction test compared to the baseline multi-agent and single-agent approaches.
Physics-Guided Hierarchical Reward Mechanism for LearningBased Multi-Finger Object Grasping
May 26, 2022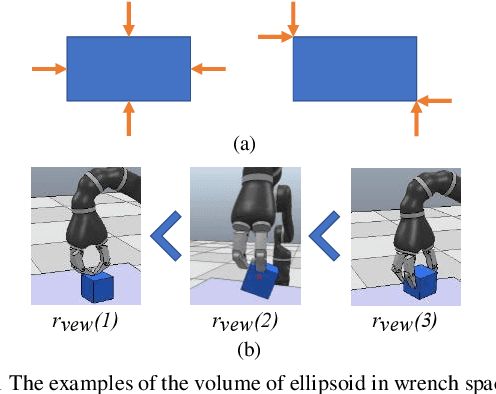
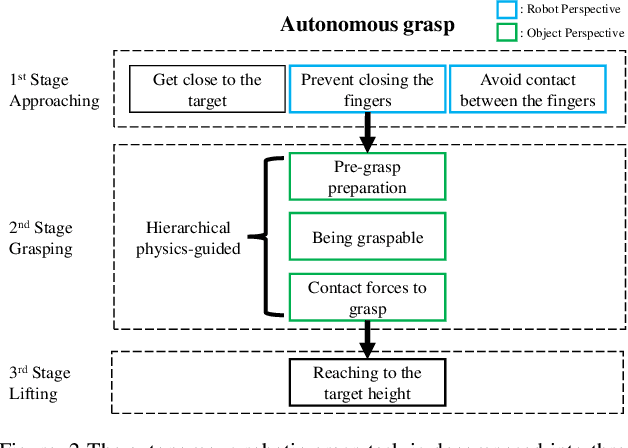
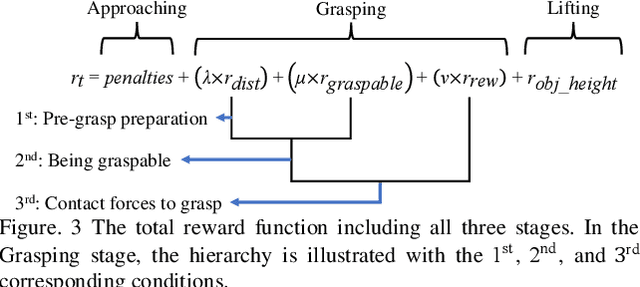

Autonomous grasping is challenging due to the high computational cost caused by multi-fingered robotic hands and their interactions with objects. Various analytical methods have been developed yet their high computational cost limits the adoption in real-world applications. Learning-based grasping can afford real-time motion planning thanks to its high computational efficiency. However, it needs to explore large search spaces during its learning process. The search space causes low learning efficiency, which has been the main barrier to its practical adoption. In this work, we develop a novel Physics-Guided Deep Reinforcement Learning with a Hierarchical Reward Mechanism, which combines the benefits of both analytical methods and learning-based methods for autonomous grasping. Different from conventional observation-based grasp learning, physics-informed metrics are utilized to convey correlations between features associated with hand structures and objects to improve learning efficiency and learning outcomes. Further, a hierarchical reward mechanism is developed to enable the robot to learn the grasping task in a prioritized way. It is validated in a grasping task with a MICO robot arm in simulation and physical experiments. The results show that our method outperformed the baseline in task performance by 48% and learning efficiency by 40%.
Forming Human-Robot Cooperation for Tasks with General Goal using Evolutionary Value Learning
Dec 19, 2020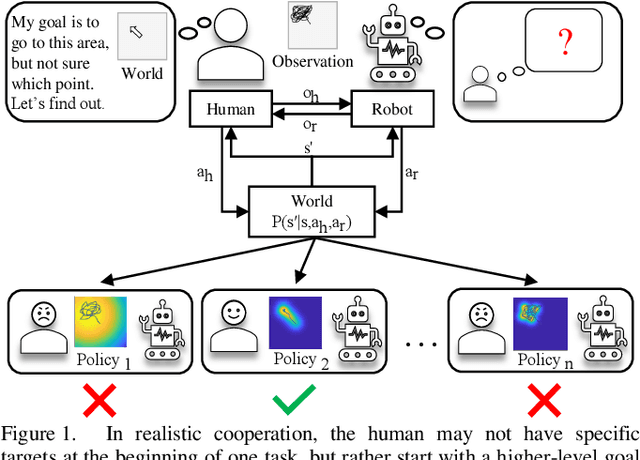
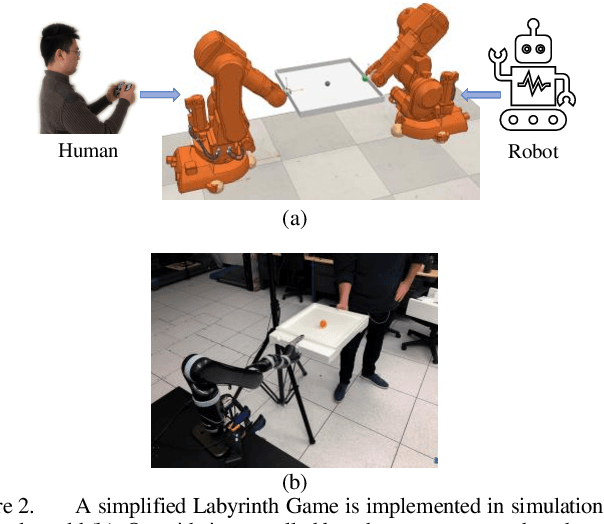
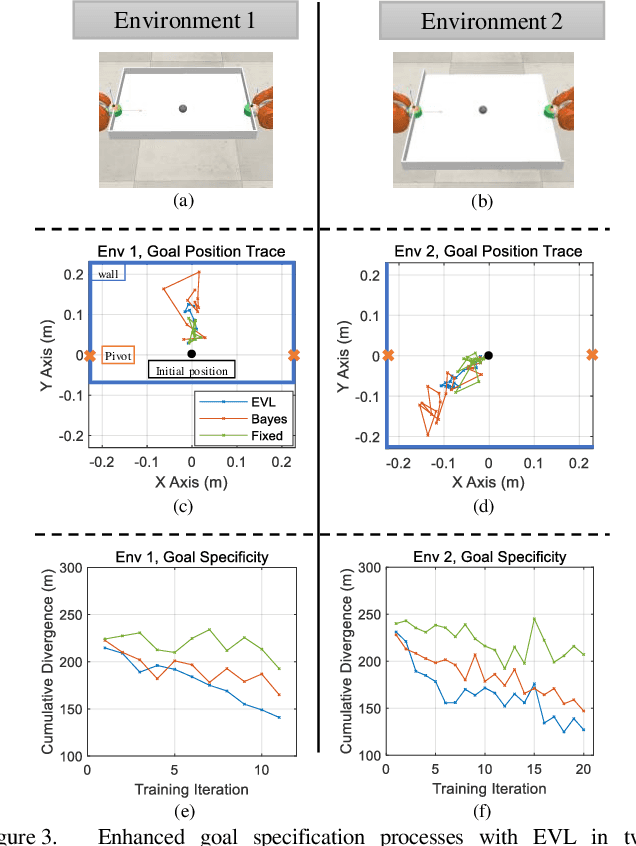
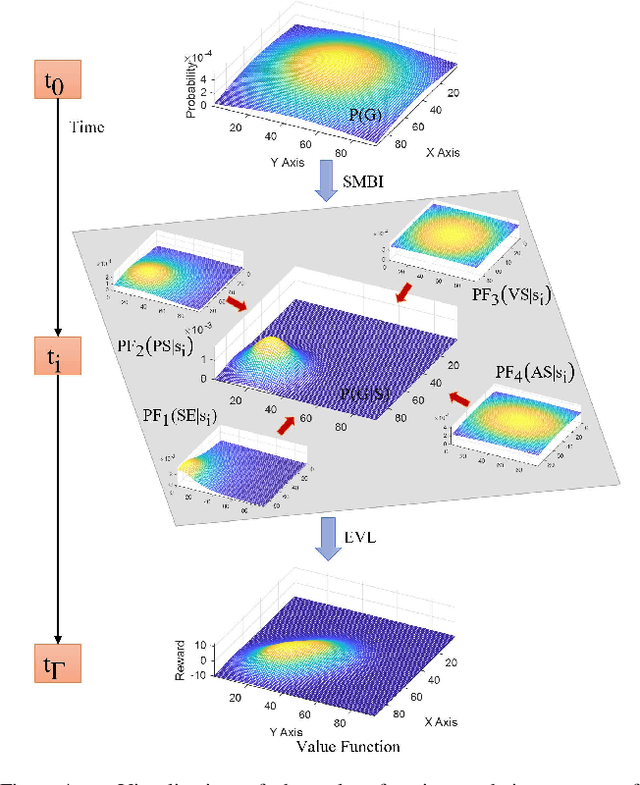
In human-robot cooperation, the robot cooperates with the human to accomplish the task together. Existing approaches assume the human has a specific goal during the cooperation, and the robot infers and acts toward it. However, in real-world environments, a human usually only has a general goal (e.g., general direction or area in motion planning) at the beginning of the cooperation which needs to be clarified to a specific goal (e.g., an exact position) during cooperation. The specification process is interactive and dynamic, which depends on the environment and the behavior of the partners. The robot that does not consider the goal specification process may cause frustration to the human partner, elongate the time to come to an agreement, and compromise or fail team performance. We present Evolutionary Value Learning (EVL) approach which uses a State-based Multivariate Bayesian Inference method to model the dynamics of goal specification process in HRC, and an Evolutionary Value Updating method to actively enhance the process of goal specification and cooperation formation. This enables the robot to simultaneously help the human to specify the goal and learn a cooperative policy in a Reinforcement Learning manner. In experiments with real human subjects, the robot equipped with EVL outperforms existing methods with faster goal specification processes and better team performance.
Robust Robot-assisted Tele-grasping Through Intent-Uncertainty-Aware Planning
May 19, 2020
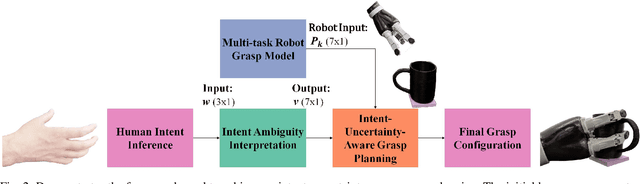
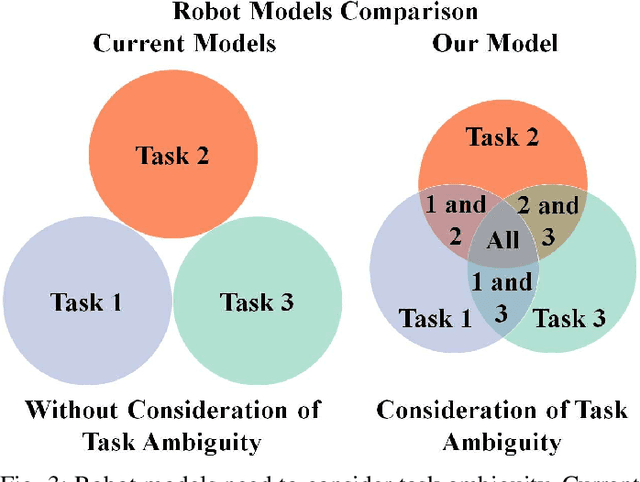
In teleoperation, research has mainly focused on target approaching, where we deal with the more challenging object manipulation task by advancing the shared control technique. Appropriately manipulating an object is challenging due to the fine motion constraint requirements for a specific manipulation task. Although these motion constraints are critical for task success, they often are subtle when observing ambiguous human motion. The disembodiment problem and physical discrepancy between the human and robot hands bring additional uncertainty, further exaggerating the complications of the object manipulation task. Moreover, there is a lack of planning and modeling techniques that can effectively combine the human and robot agents' motion input while considering the ambiguity of the human intent. To overcome this challenge, we built a multi-task robot grasping model and developed an intent-uncertainty-aware grasp planner to generate robust grasp poses given the ambiguous human intent inference inputs. With these validated modeling and planning techniques, it is expected to extend teleoperated robots' functionality and adoption in practical telemanipulation scenarios.
A General Arbitration Model for Robust Human-Robot Shared Control with Multi-Source Uncertainty Modeling
Mar 11, 2020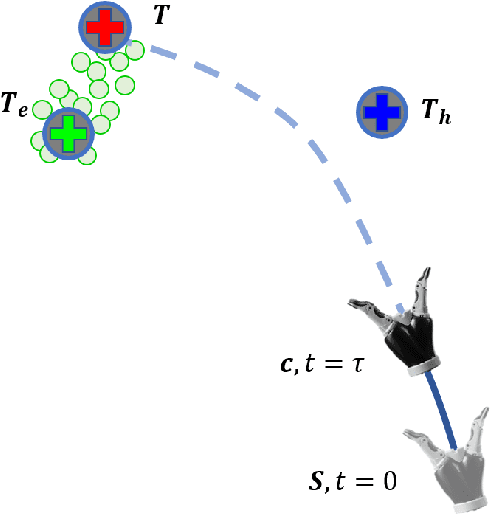
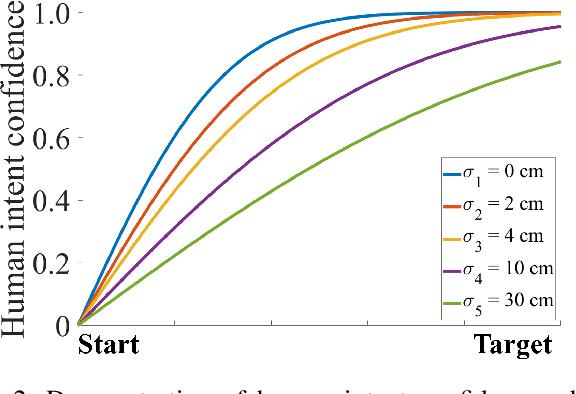

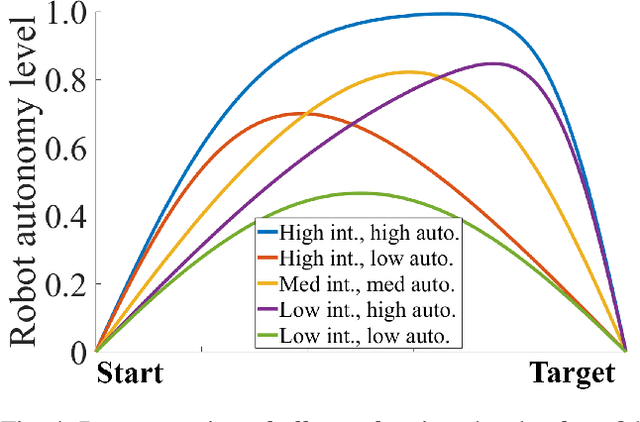
Shared control in teleoperation leverages both human and robot's strengths and has demonstrated great advantages of reducing the difficulties in teleoperating a robot and increasing the task performance. One fundamental question in shared control is how to effectively allocate the control power to the human and robot. Researchers have been subjectively defining the arbitrate policies following conflicting principles, which resulted in great inconsistency in the policies. We attribute this inconsistency to the inconsiderateness of the multi-resource uncertainty in the human-robot system. To fill the gap, we developed a multi-source uncertainty model that was applicable to various types of uncertainty in real world, and then a general arbitration model was developed to comprehensively fuse the uncertainty and regulate the arbitration weight assigned to the robotic agent. Beside traditional macro performance metrics, we introduced objective and quantitative metrics of robotic helpfulness and friendliness that evaluated the assistive robot's cooperation at micro and macro levels. Results from simulations and experiments showed the new arbitration model was more effective and friendly over the existing policies and was robust to coping with multi-source uncertainty. With this new arbitration model, we expect the increased adoption of human-robot shared control in practical and complex teleoperation tasks.
An Intent-based Task-aware Shared Control Framework for Intuitive Object Telemanipulation
Mar 07, 2020
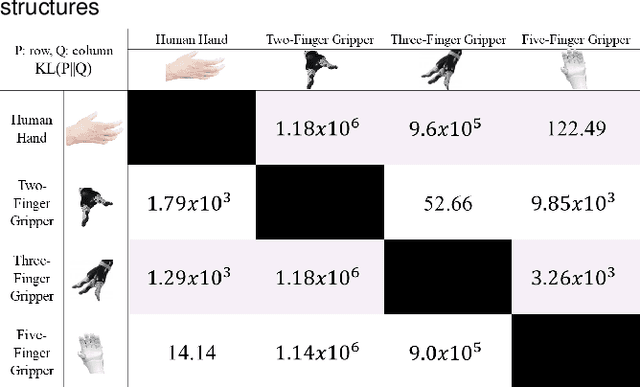


Shared control in teleoperation for providing robot assistance to accomplish object manipulation is a new challenging problem. This has unique challenges, on top of teleoperation challenges in general, due to difficulties of physical discrepancy between human hands and robot hands as well as the fine motion constraints to constitute task success. In this work we are interested in the scientific underpinnings of robot assistance for telemanipulation by defining an arbitration strategy for a physically discrepant robot hand structure which flexibly reproduce actions that accommodate the operator's motion inputs as well as autonomously regulate the actions to compensate task constraints that facilitate subsequent manipulation. The overall objective is to present a control strategy where the focus is on generating poses which are better suited for human perception of successful teleoperated object manipulation and feeling of being in control of the robot, rather than developing objective stable grasp configurations for task success. Identifying the commonalities between human and robot feature sets enable the accommodation for the arbitration framework to indicate and appear to intuitively follow the user. Additionally, it is imperative to understand how users perceive good arbitration in object telemanipulation. We have also conducted a user study to analyze the effect of factors including task predictability, perceived following, and user preference.