 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Dexterous Telemanipulation with an End-Effect-Oriented Learning-based Approach
Aug 01, 2024



Dexterous telemanipulation is crucial in advancing human-robot systems, especially in tasks requiring precise and safe manipulation. However, it faces significant challenges due to the physical differences between human and robotic hands, the dynamic interaction with objects, and the indirect control and perception of the remote environment. Current approaches predominantly focus on mapping the human hand onto robotic counterparts to replicate motions, which exhibits a critical oversight: it often neglects the physical interaction with objects and relegates the interaction burden to the human to adapt and make laborious adjustments in response to the indirect and counter-intuitive observation of the remote environment. This work develops an End-Effects-Oriented Learning-based Dexterous Telemanipulation (EFOLD) framework to address telemanipulation tasks. EFOLD models telemanipulation as a Markov Game, introducing multiple end-effect features to interpret the human operator's commands during interaction with objects. These features are used by a Deep Reinforcement Learning policy to control the robot and reproduce such end effects. EFOLD was evaluated with real human subjects and two end-effect extraction methods for controlling a virtual Shadow Robot Hand in telemanipulation tasks. EFOLD achieved real-time control capability with low command following latency (delay<0.11s) and highly accurate tracking (MSE<0.084 rad).
Transferability-based Chain Motion Mapping from Humans to Humanoids for Teleoperation
Oct 28, 2022



Although data-driven motion mapping methods are promising to allow intuitive robot control and teleoperation that generate human-like robot movement, they normally require tedious pair-wise training for each specific human and robot pair. This paper proposes a transferability-based mapping scheme to allow new robot and human input systems to leverage the mapping of existing trained pairs to form a mapping transfer chain, which will reduce the number of new pair-specific mappings that need to be generated. The first part of the mapping schematic is the development of a Synergy Mapping via Dual-Autoencoder (SyDa) method. This method uses the latent features from two autoencoders to extract the common synergy of the two agents. Secondly, a transferability metric is created that approximates how well the mapping between a pair of agents will perform compared to another pair before creating the motion mapping models. Thus, it can guide the formation of an optimal mapping chain for the new human-robot pair. Experiments with human subjects and a Pepper robot demonstrated 1) The SyDa method improves the accuracy and generalizability of the pair mappings, 2) the SyDa method allows for bidirectional mapping that does not prioritize the direction of mapping motion, and 3) the transferability metric measures how compatible two agents are for accurate teleoperation. The combination of the SyDa method and transferability metric creates generalizable and accurate mapping need to create the transfer mapping chain.
Physics-Guided Hierarchical Reward Mechanism for LearningBased Multi-Finger Object Grasping
May 26, 2022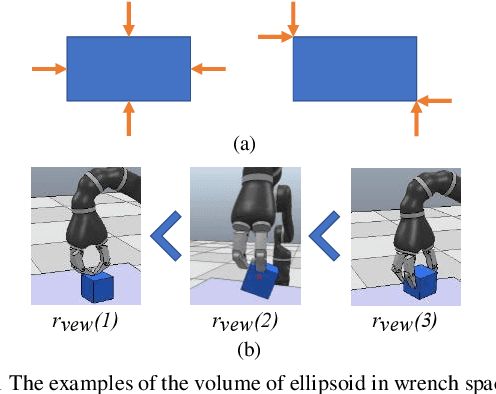
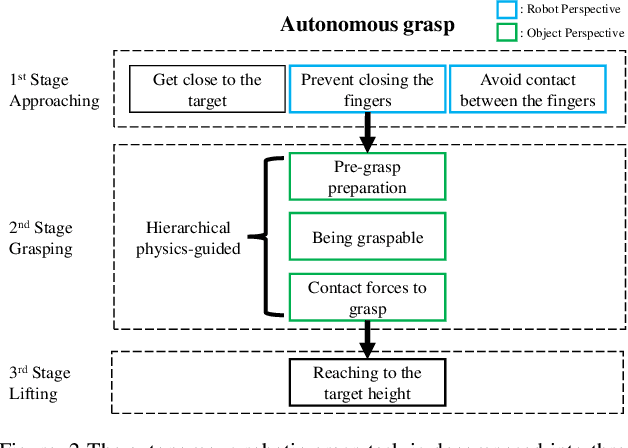
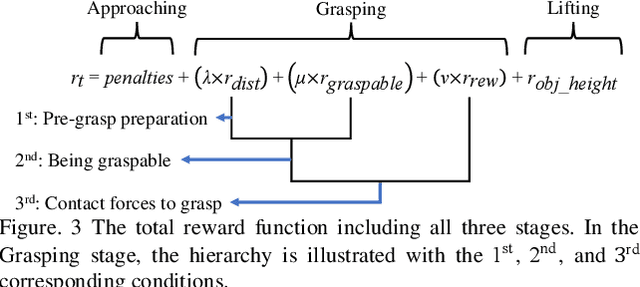

Autonomous grasping is challenging due to the high computational cost caused by multi-fingered robotic hands and their interactions with objects. Various analytical methods have been developed yet their high computational cost limits the adoption in real-world applications. Learning-based grasping can afford real-time motion planning thanks to its high computational efficiency. However, it needs to explore large search spaces during its learning process. The search space causes low learning efficiency, which has been the main barrier to its practical adoption. In this work, we develop a novel Physics-Guided Deep Reinforcement Learning with a Hierarchical Reward Mechanism, which combines the benefits of both analytical methods and learning-based methods for autonomous grasping. Different from conventional observation-based grasp learning, physics-informed metrics are utilized to convey correlations between features associated with hand structures and objects to improve learning efficiency and learning outcomes. Further, a hierarchical reward mechanism is developed to enable the robot to learn the grasping task in a prioritized way. It is validated in a grasping task with a MICO robot arm in simulation and physical experiments. The results show that our method outperformed the baseline in task performance by 48% and learning efficiency by 40%.