 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKPLM-STA: Physically-Accurate Shadow Synthesis for Human Relighting via Keypoint-Based Light Modeling
Nov 11, 2025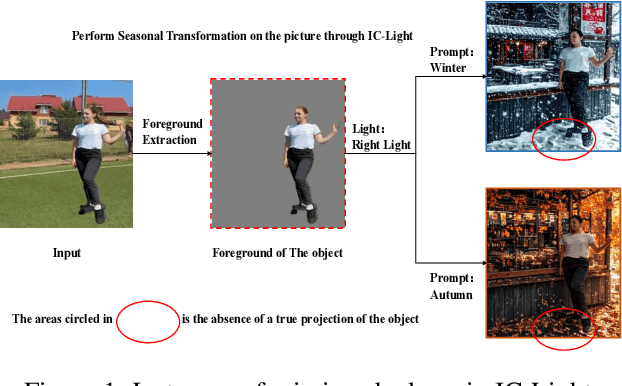


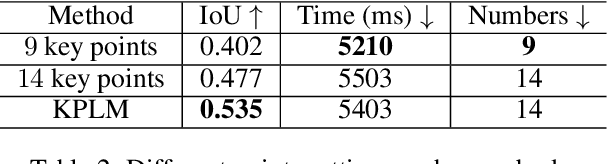
Image composition aims to seamlessly integrate a foreground object into a background, where generating realistic and geometrically accurate shadows remains a persistent challenge. While recent diffusion-based methods have outperformed GAN-based approaches, existing techniques, such as the diffusion-based relighting framework IC-Light, still fall short in producing shadows with both high appearance realism and geometric precision, especially in composite images. To address these limitations, we propose a novel shadow generation framework based on a Keypoints Linear Model (KPLM) and a Shadow Triangle Algorithm (STA). KPLM models articulated human bodies using nine keypoints and one bounding block, enabling physically plausible shadow projection and dynamic shading across joints, thereby enhancing visual realism. STA further improves geometric accuracy by computing shadow angles, lengths, and spatial positions through explicit geometric formulations. Extensive experiments demonstrate that our method achieves state-of-the-art performance on shadow realism benchmarks, particularly under complex human poses, and generalizes effectively to multi-directional relighting scenarios such as those supported by IC-Light.
Human Motion Intent Inferencing in Teleoperation Through a SINDy Paradigm
Nov 11, 2025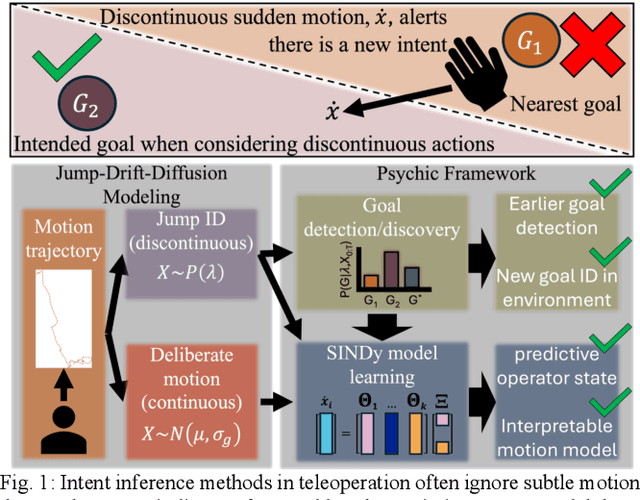
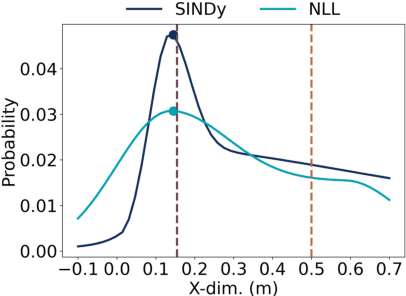
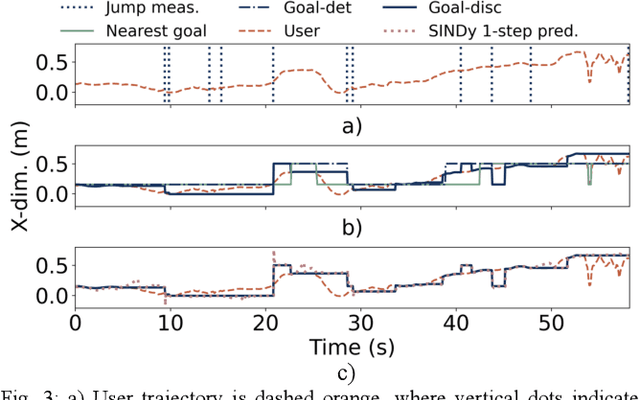
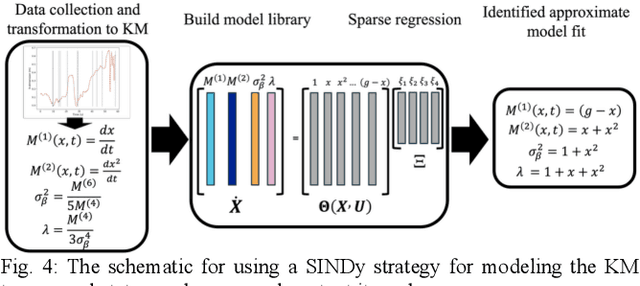
Intent inferencing in teleoperation has been instrumental in aligning operator goals and coordinating actions with robotic partners. However, current intent inference methods often ignore subtle motion that can be strong indicators for a sudden change in intent. Specifically, we aim to tackle 1) if we can detect sudden jumps in operator trajectories, 2) how we appropriately use these sudden jump motions to infer an operator's goal state, and 3) how to incorporate these discontinuous and continuous dynamics to infer operator motion. Our framework, called Psychic, models these small indicative motions through a jump-drift-diffusion stochastic differential equation to cover discontinuous and continuous dynamics. Kramers-Moyal (KM) coefficients allow us to detect jumps with a trajectory which we pair with a statistical outlier detection algorithm to nominate goal transitions. Through identifying jumps, we can perform early detection of existing goals and discover undefined goals in unstructured scenarios. Our framework then applies a Sparse Identification of Nonlinear Dynamics (SINDy) model using KM coefficients with the goal transitions as a control input to infer an operator's motion behavior in unstructured scenarios. We demonstrate Psychic can produce probabilistic reachability sets and compare our strategy to a negative log-likelihood model fit. We perform a retrospective study on 600 operator trajectories in a hands-free teleoperation task to evaluate the efficacy of our opensource package, Psychic, in both offline and online learning.
Deep learning models are vulnerable, but adversarial examples are even more vulnerable
Nov 07, 2025Understanding intrinsic differences between adversarial examples and clean samples is key to enhancing DNN robustness and detection against adversarial attacks. This study first empirically finds that image-based adversarial examples are notably sensitive to occlusion. Controlled experiments on CIFAR-10 used nine canonical attacks (e.g., FGSM, PGD) to generate adversarial examples, paired with original samples for evaluation. We introduce Sliding Mask Confidence Entropy (SMCE) to quantify model confidence fluctuation under occlusion. Using 1800+ test images, SMCE calculations supported by Mask Entropy Field Maps and statistical distributions show adversarial examples have significantly higher confidence volatility under occlusion than originals. Based on this, we propose Sliding Window Mask-based Adversarial Example Detection (SWM-AED), which avoids catastrophic overfitting of conventional adversarial training. Evaluations across classifiers and attacks on CIFAR-10 demonstrate robust performance, with accuracy over 62% in most cases and up to 96.5%.
The Use of Gaze-Derived Confidence of Inferred Operator Intent in Adjusting Safety-Conscious Haptic Assistance
Apr 04, 2025Humans directly completing tasks in dangerous or hazardous conditions is not always possible where these tasks are increasingly be performed remotely by teleoperated robots. However, teleoperation is difficult since the operator feels a disconnect with the robot caused by missing feedback from several senses, including touch, and the lack of depth in the video feedback presented to the operator. To overcome this problem, the proposed system actively infers the operator's intent and provides assistance based on the predicted intent. Furthermore, a novel method of calculating confidence in the inferred intent modifies the human-in-the-loop control. The operator's gaze is employed to intuitively indicate the target before the manipulation with the robot begins. A potential field method is used to provide a guiding force towards the intended target, and a safety boundary reduces risk of damage. Modifying these assistances based on the confidence level in the operator's intent makes the control more natural, and gives the robot an intuitive understanding of its human master. Initial validation results show the ability of the system to improve accuracy, execution time, and reduce operator error.
Improving reliability of uncertainty-aware gaze estimation with probability calibration
Jan 24, 2025



Current deep learning powered appearance based uncertainty-aware gaze estimation models produce inconsistent and unreliable uncertainty estimation that limits their adoptions in downstream applications. In this study, we propose a workflow to improve the accuracy of uncertainty estimation using probability calibration with a few post hoc samples. The probability calibration process employs a simple secondary regression model to compensate for inaccuracies in estimated uncertainties from the deep learning model. Training of the secondary model is detached from the main deep learning model and thus no expensive weight tuning is required. The added calibration process is lightweight and relatively independent from the deep learning process, making it fast to run and easy to implement. We evaluated the effectiveness of the calibration process under four potential application scenarios with two datasets that have distinctive image characteristics due to the data collection setups. The calibration process is most effective when the calibration and testing data share similar characteristics. Even under suboptimal circumstances that calibration and testing data differ, the calibration process can still make corrections to reduce prediction errors in uncertainty estimates made by uncalibrated models.
Real-time Dexterous Telemanipulation with an End-Effect-Oriented Learning-based Approach
Aug 01, 2024



Dexterous telemanipulation is crucial in advancing human-robot systems, especially in tasks requiring precise and safe manipulation. However, it faces significant challenges due to the physical differences between human and robotic hands, the dynamic interaction with objects, and the indirect control and perception of the remote environment. Current approaches predominantly focus on mapping the human hand onto robotic counterparts to replicate motions, which exhibits a critical oversight: it often neglects the physical interaction with objects and relegates the interaction burden to the human to adapt and make laborious adjustments in response to the indirect and counter-intuitive observation of the remote environment. This work develops an End-Effects-Oriented Learning-based Dexterous Telemanipulation (EFOLD) framework to address telemanipulation tasks. EFOLD models telemanipulation as a Markov Game, introducing multiple end-effect features to interpret the human operator's commands during interaction with objects. These features are used by a Deep Reinforcement Learning policy to control the robot and reproduce such end effects. EFOLD was evaluated with real human subjects and two end-effect extraction methods for controlling a virtual Shadow Robot Hand in telemanipulation tasks. EFOLD achieved real-time control capability with low command following latency (delay<0.11s) and highly accurate tracking (MSE<0.084 rad).
Arondight: Red Teaming Large Vision Language Models with Auto-generated Multi-modal Jailbreak Prompts
Jul 21, 2024



Large Vision Language Models (VLMs) extend and enhance the perceptual abilities of Large Language Models (LLMs). Despite offering new possibilities for LLM applications, these advancements raise significant security and ethical concerns, particularly regarding the generation of harmful content. While LLMs have undergone extensive security evaluations with the aid of red teaming frameworks, VLMs currently lack a well-developed one. To fill this gap, we introduce Arondight, a standardized red team framework tailored specifically for VLMs. Arondight is dedicated to resolving issues related to the absence of visual modality and inadequate diversity encountered when transitioning existing red teaming methodologies from LLMs to VLMs. Our framework features an automated multi-modal jailbreak attack, wherein visual jailbreak prompts are produced by a red team VLM, and textual prompts are generated by a red team LLM guided by a reinforcement learning agent. To enhance the comprehensiveness of VLM security evaluation, we integrate entropy bonuses and novelty reward metrics. These elements incentivize the RL agent to guide the red team LLM in creating a wider array of diverse and previously unseen test cases. Our evaluation of ten cutting-edge VLMs exposes significant security vulnerabilities, particularly in generating toxic images and aligning multi-modal prompts. In particular, our Arondight achieves an average attack success rate of 84.5\% on GPT-4 in all fourteen prohibited scenarios defined by OpenAI in terms of generating toxic text. For a clearer comparison, we also categorize existing VLMs based on their safety levels and provide corresponding reinforcement recommendations. Our multimodal prompt dataset and red team code will be released after ethics committee approval. CONTENT WARNING: THIS PAPER CONTAINS HARMFUL MODEL RESPONSES.
FinRobot: An Open-Source AI Agent Platform for Financial Applications using Large Language Models
May 23, 2024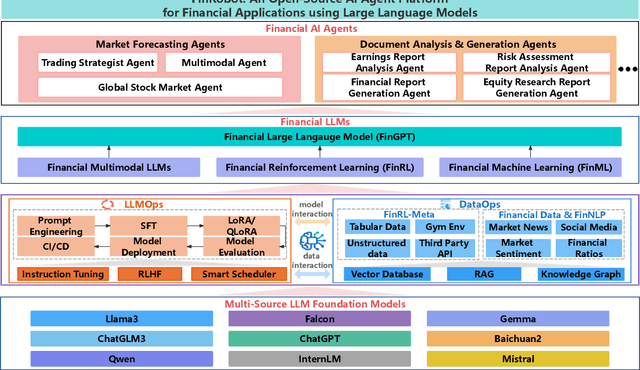
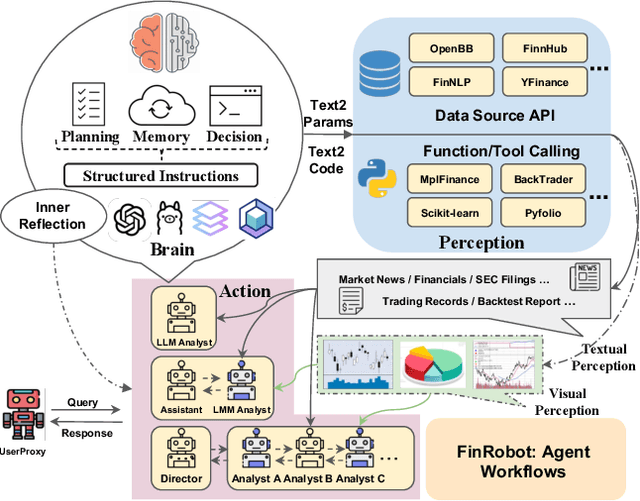
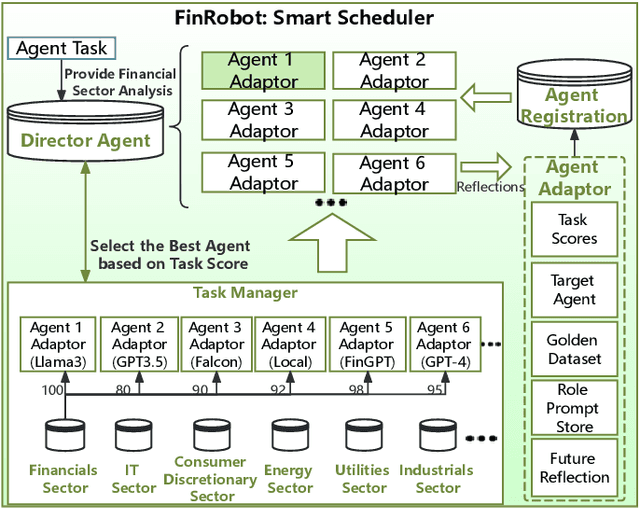

As financial institutions and professionals increasingly incorporate Large Language Models (LLMs) into their workflows, substantial barriers, including proprietary data and specialized knowledge, persist between the finance sector and the AI community. These challenges impede the AI community's ability to enhance financial tasks effectively. Acknowledging financial analysis's critical role, we aim to devise financial-specialized LLM-based toolchains and democratize access to them through open-source initiatives, promoting wider AI adoption in financial decision-making. In this paper, we introduce FinRobot, a novel open-source AI agent platform supporting multiple financially specialized AI agents, each powered by LLM. Specifically, the platform consists of four major layers: 1) the Financial AI Agents layer that formulates Financial Chain-of-Thought (CoT) by breaking sophisticated financial problems down into logical sequences; 2) the Financial LLM Algorithms layer dynamically configures appropriate model application strategies for specific tasks; 3) the LLMOps and DataOps layer produces accurate models by applying training/fine-tuning techniques and using task-relevant data; 4) the Multi-source LLM Foundation Models layer that integrates various LLMs and enables the above layers to access them directly. Finally, FinRobot provides hands-on for both professional-grade analysts and laypersons to utilize powerful AI techniques for advanced financial analysis. We open-source FinRobot at \url{https://github.com/AI4Finance-Foundation/FinRobot}.
Stable In-hand Manipulation with Finger Specific Multi-agent Shadow Reward
Sep 13, 2023



Deep Reinforcement Learning has shown its capability to solve the high degrees of freedom in control and the complex interaction with the object in the multi-finger dexterous in-hand manipulation tasks. Current DRL approaches prefer sparse rewards to dense rewards for the ease of training but lack behavior constraints during the manipulation process, leading to aggressive and unstable policies that are insufficient for safety-critical in-hand manipulation tasks. Dense rewards can regulate the policy to learn stable manipulation behaviors with continuous reward constraints but are hard to empirically define and slow to converge optimally. This work proposes the Finger-specific Multi-agent Shadow Reward (FMSR) method to determine the stable manipulation constraints in the form of dense reward based on the state-action occupancy measure, a general utility of DRL that is approximated during the learning process. Information Sharing (IS) across neighboring agents enables consensus training to accelerate the convergence. The methods are evaluated in two in-hand manipulation tasks on the Shadow Hand. The results show FMSR+IS converges faster in training, achieving a higher task success rate and better manipulation stability than conventional dense reward. The comparison indicates FMSR+IS achieves a comparable success rate even with the behavior constraint but much better manipulation stability than the policy trained with a sparse reward.
Curriculum-based Sensing Reduction in Simulation to Real-World Transfer for In-hand Manipulation
Sep 13, 2023



Simulation to Real-World Transfer allows affordable and fast training of learning-based robots for manipulation tasks using Deep Reinforcement Learning methods. Currently, Sim2Real uses Asymmetric Actor-Critic approaches to reduce the rich idealized features in simulation to the accessible ones in the real world. However, the feature reduction from the simulation to the real world is conducted through an empirically defined one-step curtail. Small feature reduction does not sufficiently remove the actor's features, which may still cause difficulty setting up the physical system, while large feature reduction may cause difficulty and inefficiency in training. To address this issue, we proposed Curriculum-based Sensing Reduction to enable the actor to start with the same rich feature space as the critic and then get rid of the hard-to-extract features step-by-step for higher training performance and better adaptation for real-world feature space. The reduced features are replaced with random signals from a Deep Random Generator to remove the dependency between the output and the removed features and avoid creating new dependencies. The methods are evaluated on the Allegro robot hand in a real-world in-hand manipulation task. The results show that our methods have faster training and higher task performance than baselines and can solve real-world tasks when selected tactile features are reduced.