 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Domain Adversarial Neural Network Based on Knowledge Distillation for EEG-based Cross-subject Emotion Recognition
May 12, 2023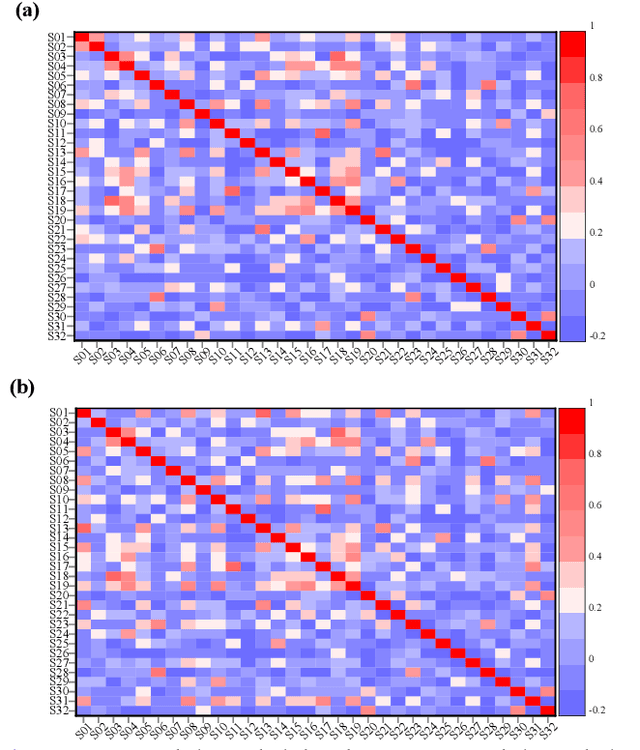


Individual differences of Electroencephalogram (EEG) could cause the domain shift which would significantly degrade the performance of cross-subject strategy. The domain adversarial neural networks (DANN), where the classification loss and domain loss jointly update the parameters of feature extractor, are adopted to deal with the domain shift. However, limited EEG data quantity and strong individual difference are challenges for the DANN with cumbersome feature extractor. In this work, we propose knowledge distillation (KD) based lightweight DANN to enhance cross-subject EEG-based emotion recognition. Specifically, the teacher model with strong context learning ability is utilized to learn complex temporal dynamics and spatial correlations of EEG, and robust lightweight student model is guided by the teacher model to learn more difficult domain-invariant features. In the feature-based KD framework, a transformer-based hierarchical temporalspatial learning model is served as the teacher model. The student model, which is composed of Bi-LSTM units, is a lightweight version of the teacher model. Hence, the student model could be supervised to mimic the robust feature representations of teacher model by leveraging complementary latent temporal features and spatial features. In the DANN-based cross-subject emotion recognition, we combine the obtained student model and a lightweight temporal-spatial feature interaction module as the feature extractor. And the feature aggregation is fed to the emotion classifier and domain classifier for domain-invariant feature learning. To verify the effectiveness of the proposed method, we conduct the subject-independent experiments on the public dataset DEAP with arousal and valence classification. The outstanding performance and t-SNE visualization of latent features verify the advantage and effectiveness of the proposed method.
STILN: A Novel Spatial-Temporal Information Learning Network for EEG-based Emotion Recognition
Nov 22, 2022



The spatial correlations and the temporal contexts are indispensable in Electroencephalogram (EEG)-based emotion recognition. However, the learning of complex spatial correlations among several channels is a challenging problem. Besides, the temporal contexts learning is beneficial to emphasize the critical EEG frames because the subjects only reach the prospective emotion during part of stimuli. Hence, we propose a novel Spatial-Temporal Information Learning Network (STILN) to extract the discriminative features by capturing the spatial correlations and temporal contexts. Specifically, the generated 2D power topographic maps capture the dependencies among electrodes, and they are fed to the CNN-based spatial feature extraction network. Furthermore, Convolutional Block Attention Module (CBAM) recalibrates the weights of power topographic maps to emphasize the crucial brain regions and frequency bands. Meanwhile, Batch Normalizations (BNs) and Instance Normalizations (INs) are appropriately combined to relieve the individual differences. In the temporal contexts learning, we adopt the Bidirectional Long Short-Term Memory Network (Bi-LSTM) network to capture the dependencies among the EEG frames. To validate the effectiveness of the proposed method, subject-independent experiments are conducted on the public DEAP dataset. The proposed method has achieved the outstanding performance, and the accuracies of arousal and valence classification have reached 0.6831 and 0.6752 respectively.
Temporal-spatial Representation Learning Transformer for EEG-based Emotion Recognition
Nov 16, 2022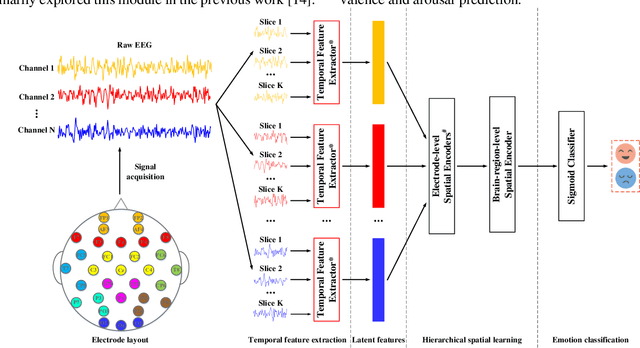
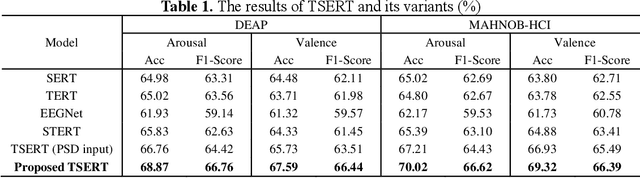
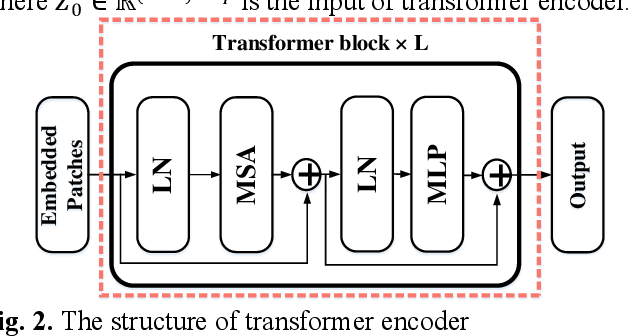
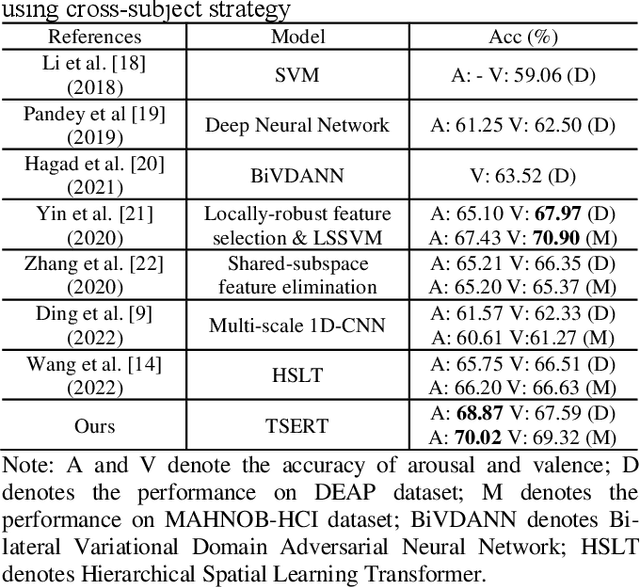
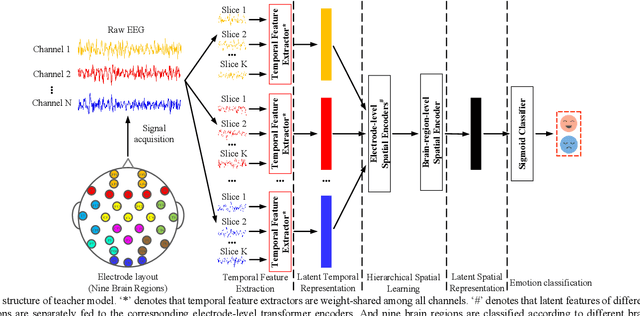
Both the temporal dynamics and spatial correlations of Electroencephalogram (EEG), which contain discriminative emotion information, are essential for the emotion recognition. However, some redundant information within the EEG signals would degrade the performance. Specifically,the subjects reach prospective intense emotions for only a fraction of the stimulus duration. Besides, it is a challenge to extract discriminative features from the complex spatial correlations among a number of electrodes. To deal with the problems, we propose a transformer-based model to robustly capture temporal dynamics and spatial correlations of EEG. Especially, temporal feature extractors which share the weight among all the EEG channels are designed to adaptively extract dynamic context information from raw signals. Furthermore, multi-head self-attention mechanism within the transformers could adaptively localize the vital EEG fragments and emphasize the essential brain regions which contribute to the performance. To verify the effectiveness of the proposed method, we conduct the experiments on two public datasets, DEAP and MAHNOBHCI. The results demonstrate that the proposed method achieves outstanding performance on arousal and valence classification.
Towards Trustworthy Multi-label Sewer Defect Classification via Evidential Deep Learning
Oct 25, 2022



An automatic vision-based sewer inspection plays a key role of sewage system in a modern city. Recent advances focus on utilizing deep learning model to realize the sewer inspection system, benefiting from the capability of data-driven feature representation. However, the inherent uncertainty of sewer defects is ignored, resulting in the missed detection of serious unknown sewer defect categories. In this paper, we propose a trustworthy multi-label sewer defect classification (TMSDC) method, which can quantify the uncertainty of sewer defect prediction via evidential deep learning. Meanwhile, a novel expert base rate assignment (EBRA) is proposed to introduce the expert knowledge for describing reliable evidences in practical situations. Experimental results demonstrate the effectiveness of TMSDC and the superior capability of uncertainty estimation is achieved on the latest public benchmark.
ASD: Towards Attribute Spatial Decomposition for Prior-Free Facial Attribute Recognition
Oct 25, 2022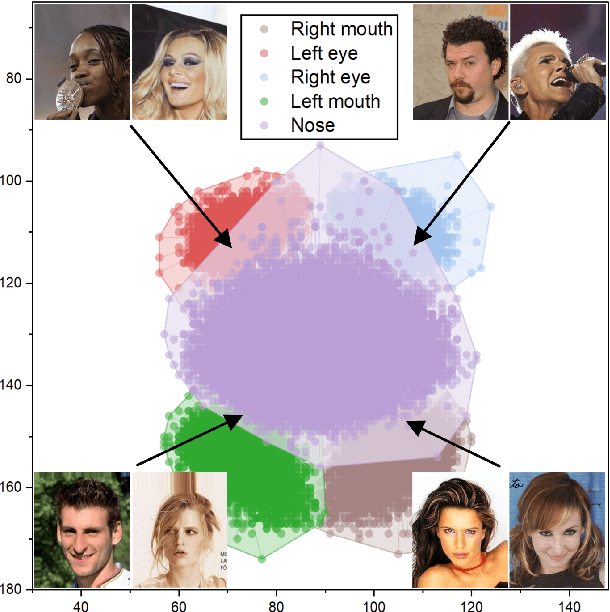
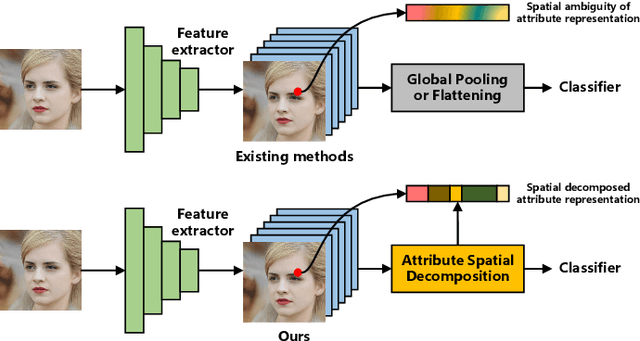
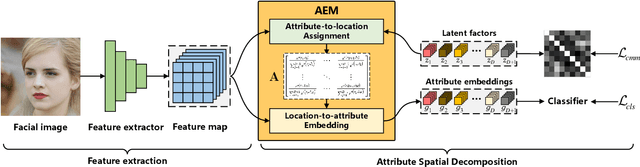

Representing the spatial properties of facial attributes is a vital challenge for facial attribute recognition (FAR). Recent advances have achieved the reliable performances for FAR, benefiting from the description of spatial properties via extra prior information. However, the extra prior information might not be always available, resulting in the restricted application scenario of the prior-based methods. Meanwhile, the spatial ambiguity of facial attributes caused by inherent spatial diversities of facial parts is ignored. To address these issues, we propose a prior-free method for attribute spatial decomposition (ASD), mitigating the spatial ambiguity of facial attributes without any extra prior information. Specifically, assignment-embedding module (AEM) is proposed to enable the procedure of ASD, which consists of two operations: attribute-to-location assignment and location-to-attribute embedding. The attribute-to-location assignment first decomposes the feature map based on latent factors, assigning the magnitude of attribute components on each spatial location. Then, the assigned attribute components from all locations to represent the global-level attribute embeddings. Furthermore, correlation matrix minimization (CMM) is introduced to enlarge the discriminability of attribute embeddings. Experimental results demonstrate the superiority of ASD compared with state-of-the-art prior-based methods, while the reliable performance of ASD for the case of limited training data is further validated.
Towards Accurate Camouflaged Object Detection with Mixture Convolution and Interactive Fusion
Jan 14, 2021
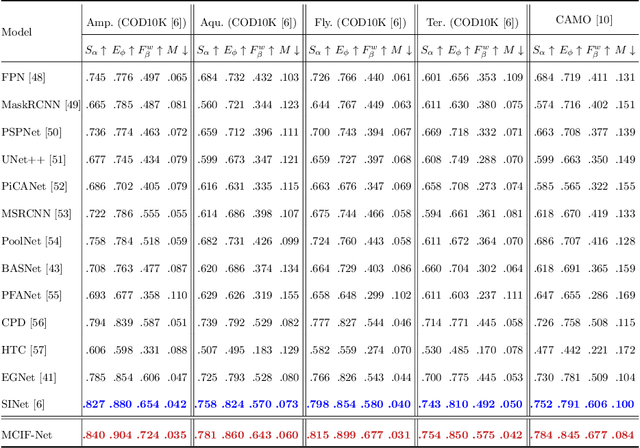
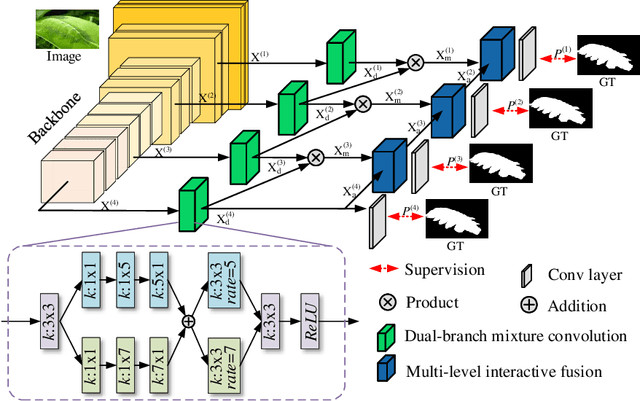
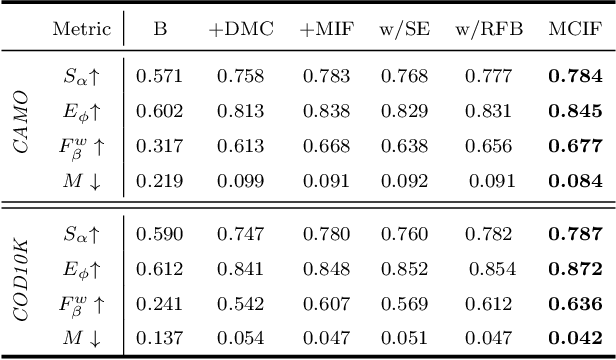
Camouflaged object detection (COD), which aims to identify the objects that conceal themselves into the surroundings, has recently drawn increasing research efforts in the field of computer vision. In practice, the success of deep learning based COD is mainly determined by two key factors, including (i) A significantly large receptive field, which provides rich context information, and (ii) An effective fusion strategy, which aggregates the rich multi-level features for accurate COD. Motivated by these observations, in this paper, we propose a novel deep learning based COD approach, which integrates the large receptive field and effective feature fusion into a unified framework. Specifically, we first extract multi-level features from a backbone network. The resulting features are then fed to the proposed dual-branch mixture convolution modules, each of which utilizes multiple asymmetric convolutional layers and two dilated convolutional layers to extract rich context features from a large receptive field. Finally, we fuse the features using specially-designed multi-level interactive fusion modules, each of which employs an attention mechanism along with feature interaction for effective feature fusion. Our method detects camouflaged objects with an effective fusion strategy, which aggregates the rich context information from a large receptive field. All of these designs meet the requirements of COD well, allowing the accurate detection of camouflaged objects. Extensive experiments on widely-used benchmark datasets demonstrate that our method is capable of accurately detecting camouflaged objects and outperforms the state-of-the-art methods.