 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Multi-phase Liver Tumor Segmentation via Evidence-based Uncertainty
May 09, 2023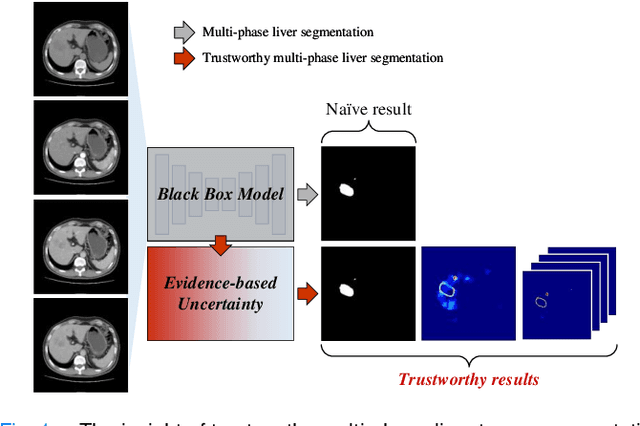
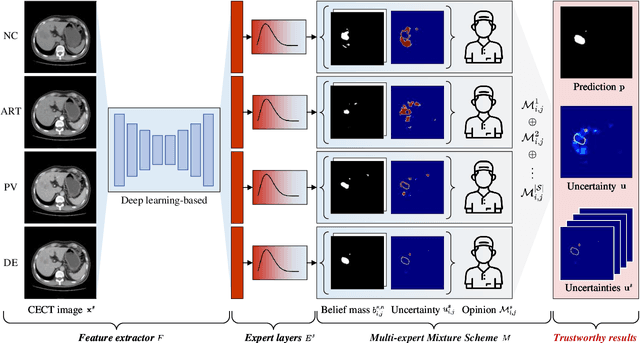
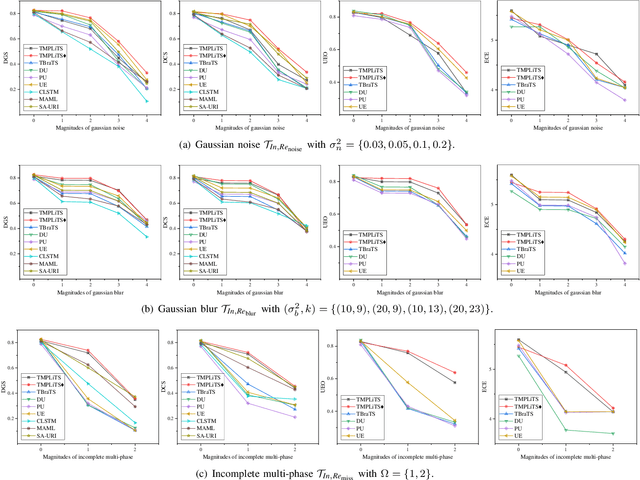
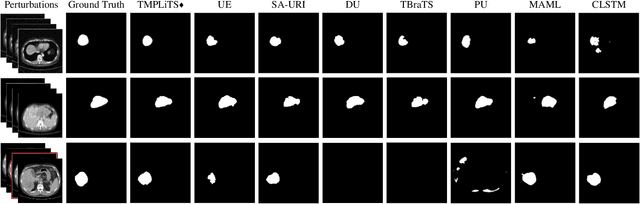
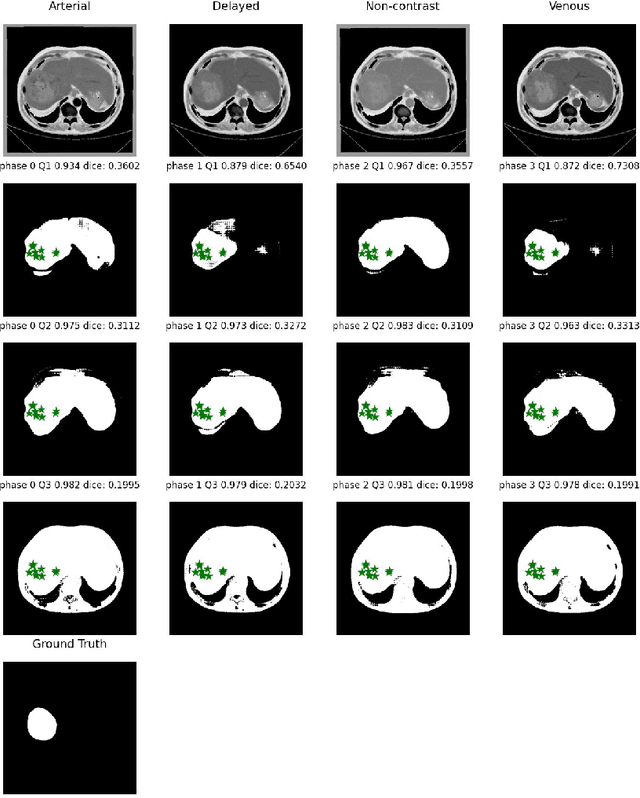
Multi-phase liver contrast-enhanced computed tomography (CECT) images convey the complementary multi-phase information for liver tumor segmentation (LiTS), which are crucial to assist the diagnosis of liver cancer clinically. However, the performances of existing multi-phase liver tumor segmentation (MPLiTS)-based methods suffer from redundancy and weak interpretability, % of the fused result, resulting in the implicit unreliability of clinical applications. In this paper, we propose a novel trustworthy multi-phase liver tumor segmentation (TMPLiTS), which is a unified framework jointly conducting segmentation and uncertainty estimation. The trustworthy results could assist the clinicians to make a reliable diagnosis. Specifically, Dempster-Shafer Evidence Theory (DST) is introduced to parameterize the segmentation and uncertainty as evidence following Dirichlet distribution. The reliability of segmentation results among multi-phase CECT images is quantified explicitly. Meanwhile, a multi-expert mixture scheme (MEMS) is proposed to fuse the multi-phase evidences, which can guarantee the effect of fusion procedure based on theoretical analysis. Experimental results demonstrate the superiority of TMPLiTS compared with the state-of-the-art methods. Meanwhile, the robustness of TMPLiTS is verified, where the reliable performance can be guaranteed against the perturbations.
When SAM Meets Medical Images: An Investigation of Segment Anything Model (SAM) on Multi-phase Liver Tumor Segmentation
May 04, 2023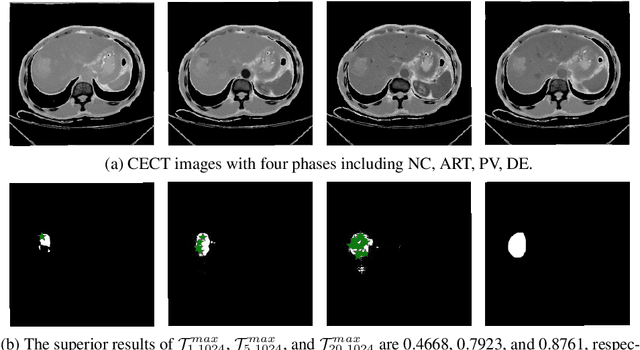
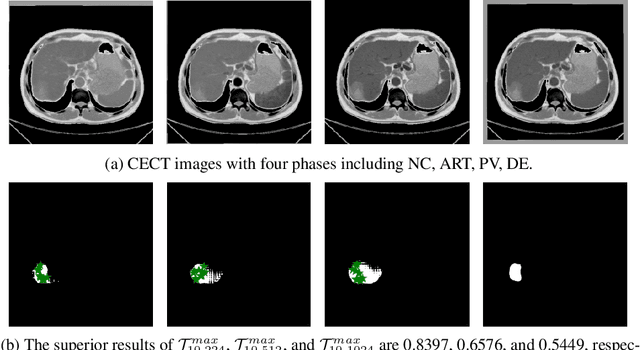
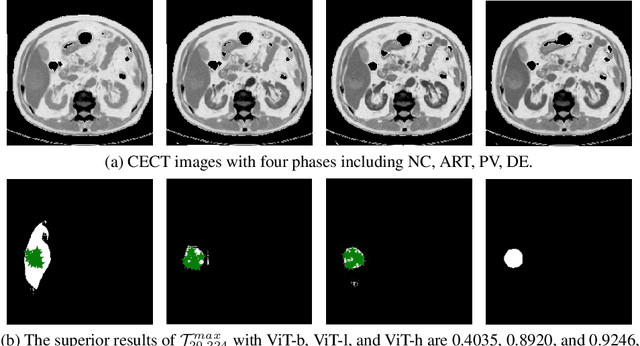
Learning to segmentation without large-scale samples is an inherent capability of human. Recently, Segment Anything Model (SAM) performs the significant zero-shot image segmentation, attracting considerable attention from the computer vision community. Here, we investigate the capability of SAM for medical image analysis, especially for multi-phase liver tumor segmentation (MPLiTS), in terms of prompts, data resolution, phases. Experimental results demonstrate that there might be a large gap between SAM and expected performance. Fortunately, the qualitative results show that SAM is a powerful annotation tool for the community of interactive medical image segmentation.
Temporal-spatial Representation Learning Transformer for EEG-based Emotion Recognition
Nov 16, 2022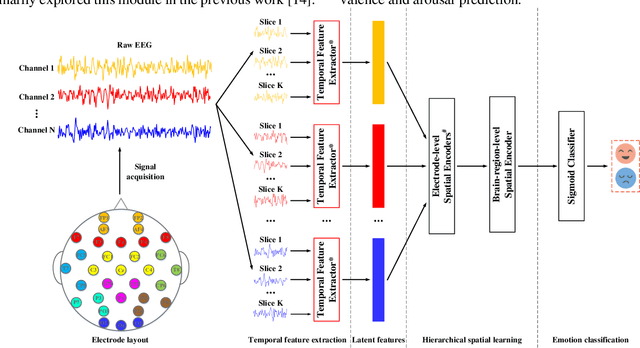
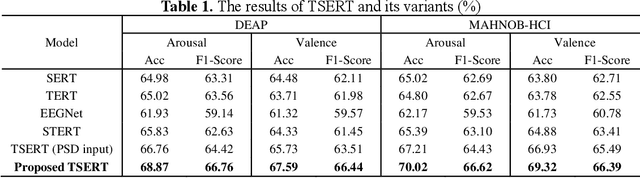
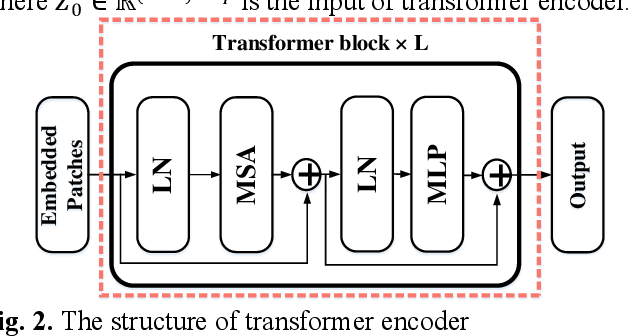
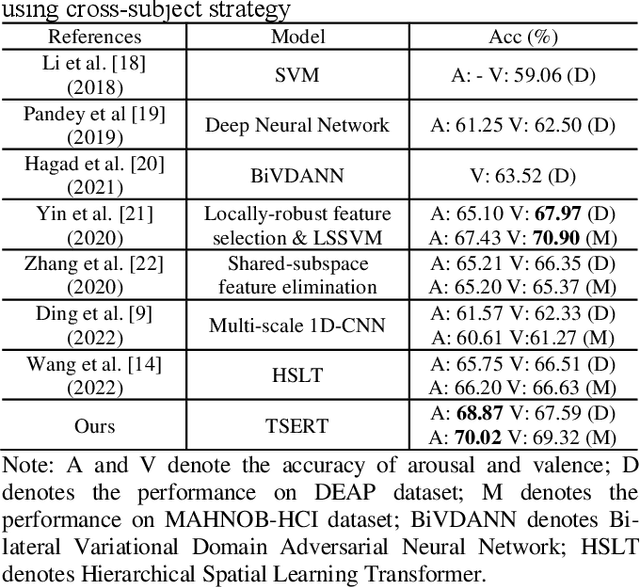
Both the temporal dynamics and spatial correlations of Electroencephalogram (EEG), which contain discriminative emotion information, are essential for the emotion recognition. However, some redundant information within the EEG signals would degrade the performance. Specifically,the subjects reach prospective intense emotions for only a fraction of the stimulus duration. Besides, it is a challenge to extract discriminative features from the complex spatial correlations among a number of electrodes. To deal with the problems, we propose a transformer-based model to robustly capture temporal dynamics and spatial correlations of EEG. Especially, temporal feature extractors which share the weight among all the EEG channels are designed to adaptively extract dynamic context information from raw signals. Furthermore, multi-head self-attention mechanism within the transformers could adaptively localize the vital EEG fragments and emphasize the essential brain regions which contribute to the performance. To verify the effectiveness of the proposed method, we conduct the experiments on two public datasets, DEAP and MAHNOBHCI. The results demonstrate that the proposed method achieves outstanding performance on arousal and valence classification.
ASD: Towards Attribute Spatial Decomposition for Prior-Free Facial Attribute Recognition
Oct 25, 2022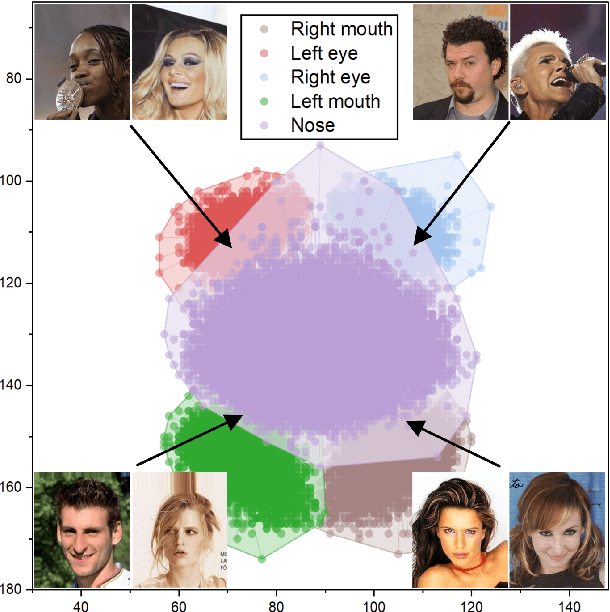
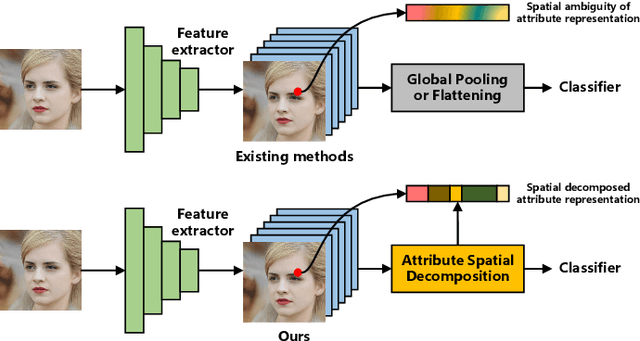
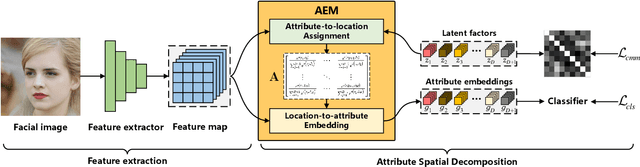

Representing the spatial properties of facial attributes is a vital challenge for facial attribute recognition (FAR). Recent advances have achieved the reliable performances for FAR, benefiting from the description of spatial properties via extra prior information. However, the extra prior information might not be always available, resulting in the restricted application scenario of the prior-based methods. Meanwhile, the spatial ambiguity of facial attributes caused by inherent spatial diversities of facial parts is ignored. To address these issues, we propose a prior-free method for attribute spatial decomposition (ASD), mitigating the spatial ambiguity of facial attributes without any extra prior information. Specifically, assignment-embedding module (AEM) is proposed to enable the procedure of ASD, which consists of two operations: attribute-to-location assignment and location-to-attribute embedding. The attribute-to-location assignment first decomposes the feature map based on latent factors, assigning the magnitude of attribute components on each spatial location. Then, the assigned attribute components from all locations to represent the global-level attribute embeddings. Furthermore, correlation matrix minimization (CMM) is introduced to enlarge the discriminability of attribute embeddings. Experimental results demonstrate the superiority of ASD compared with state-of-the-art prior-based methods, while the reliable performance of ASD for the case of limited training data is further validated.
Towards Trustworthy Multi-label Sewer Defect Classification via Evidential Deep Learning
Oct 25, 2022



An automatic vision-based sewer inspection plays a key role of sewage system in a modern city. Recent advances focus on utilizing deep learning model to realize the sewer inspection system, benefiting from the capability of data-driven feature representation. However, the inherent uncertainty of sewer defects is ignored, resulting in the missed detection of serious unknown sewer defect categories. In this paper, we propose a trustworthy multi-label sewer defect classification (TMSDC) method, which can quantify the uncertainty of sewer defect prediction via evidential deep learning. Meanwhile, a novel expert base rate assignment (EBRA) is proposed to introduce the expert knowledge for describing reliable evidences in practical situations. Experimental results demonstrate the effectiveness of TMSDC and the superior capability of uncertainty estimation is achieved on the latest public benchmark.
TNTC: two-stream network with transformer-based complementarity for gait-based emotion recognition
Oct 26, 2021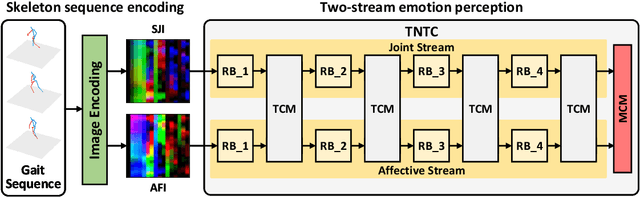
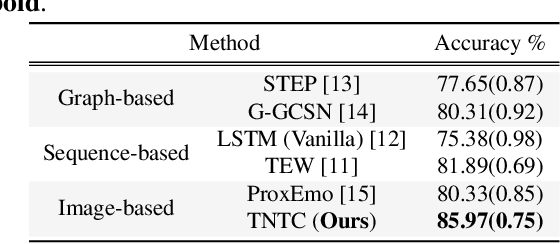

Recognizing the human emotion automatically from visual characteristics plays a vital role in many intelligent applications. Recently, gait-based emotion recognition, especially gait skeletons-based characteristic, has attracted much attention, while many available methods have been proposed gradually. The popular pipeline is to first extract affective features from joint skeletons, and then aggregate the skeleton joint and affective features as the feature vector for classifying the emotion. However, the aggregation procedure of these emerged methods might be rigid, resulting in insufficiently exploiting the complementary relationship between skeleton joint and affective features. Meanwhile, the long range dependencies in both spatial and temporal domains of the gait sequence are scarcely considered. To address these issues, we propose a novel two-stream network with transformer-based complementarity, termed as TNTC. Skeleton joint and affective features are encoded into two individual images as the inputs of two streams, respectively. A new transformer-based complementarity module (TCM) is proposed to bridge the complementarity between two streams hierarchically via capturing long range dependencies. Experimental results demonstrate TNTC outperforms state-of-the-art methods on the latest dataset in terms of accuracy.