 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Conflict Measurement in Decision Making for Out-of-Distribution Detection
May 10, 2025Quantum Dempster-Shafer Theory (QDST) uses quantum interference effects to derive a quantum mass function (QMF) as a fuzzy metric type from information obtained from various data sources. In addition, QDST uses quantum parallel computing to speed up computation. Nevertheless, the effective management of conflicts between multiple QMFs in QDST is a challenging question. This work aims to address this problem by proposing a Quantum Conflict Indicator (QCI) that measures the conflict between two QMFs in decision-making. Then, the properties of the QCI are carefully investigated. The obtained results validate its compliance with desirable conflict measurement properties such as non-negativity, symmetry, boundedness, extreme consistency and insensitivity to refinement. We then apply the proposed QCI in conflict fusion methods and compare its performance with several commonly used fusion approaches. This comparison demonstrates the superiority of the QCI-based conflict fusion method. Moreover, the Class Description Domain Space (C-DDS) and its optimized version, C-DDS+ by utilizing the QCI-based fusion method, are proposed to address the Out-of-Distribution (OOD) detection task. The experimental results show that the proposed approach gives better OOD performance with respect to several state-of-the-art baseline OOD detection methods. Specifically, it achieves an average increase in Area Under the Receiver Operating Characteristic Curve (AUC) of 1.2% and a corresponding average decrease in False Positive Rate at 95% True Negative Rate (FPR95) of 5.4% compared to the optimal baseline method.
FR-SLAM: A SLAM Improvement Method Based on Floor Plan Registration
Jul 16, 2024



Simultaneous Localization and Mapping (SLAM) technology enables the construction of environmental maps and localization, serving as a key technique for indoor autonomous navigation of mobile robots. Traditional SLAM methods typically require exhaustive traversal of all rooms during indoor navigation to obtain a complete map, resulting in lengthy path planning times and prolonged time to reach target points. Moreover, cumulative errors during motion lead to inaccurate robot localization, impacting navigation efficiency.This paper proposes an improved SLAM method, FR-SLAM, based on floor plan registration, utilizing a morphology-based floor plan registration algorithm to align and transform original floor plans. This approach facilitates the rapid acquisition of comprehensive motion maps and efficient path planning, enabling swift navigation to target positions within a shorter timeframe. To enhance registration and robot motion localization accuracy, a real-time update strategy is employed, comparing the current position's building structure with the map and dynamically updating floor plan registration results for precise localization. Comparative tests conducted on real and simulated datasets demonstrate that, compared to other benchmark algorithms, this method achieves higher floor plan registration accuracy and shorter time consumption to reach target positions.
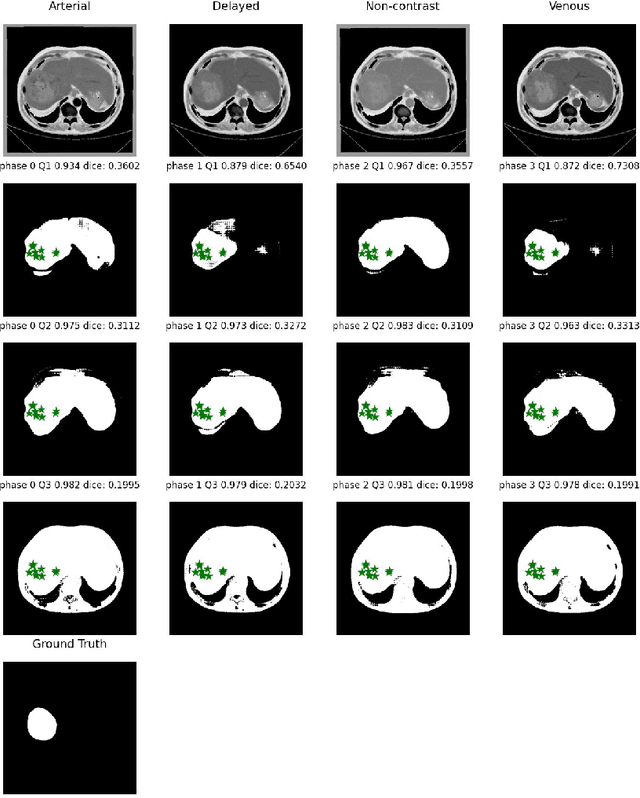
Trustworthy Multi-phase Liver Tumor Segmentation via Evidence-based Uncertainty
May 09, 2023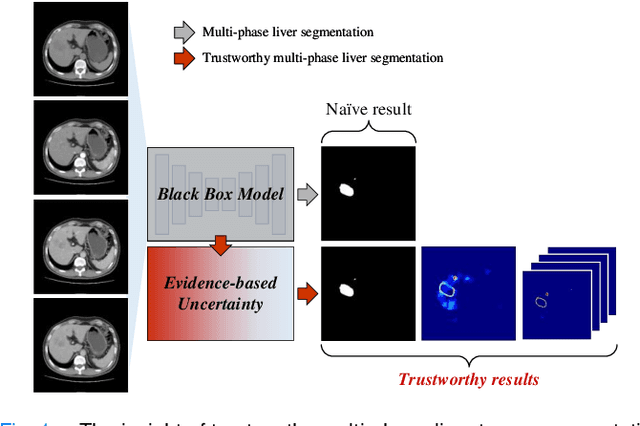
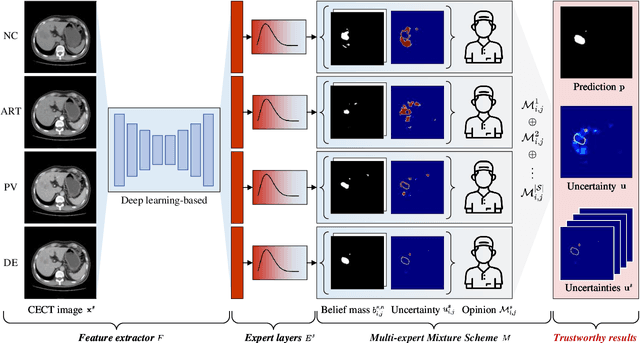
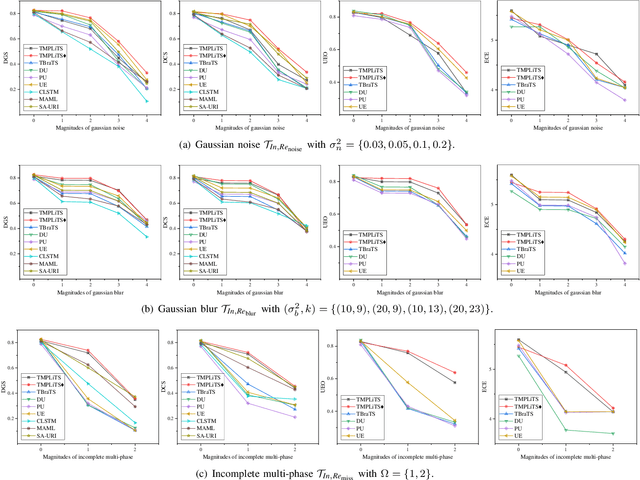
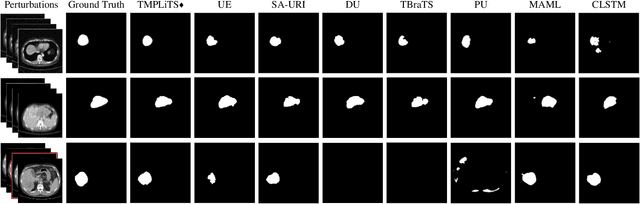
Multi-phase liver contrast-enhanced computed tomography (CECT) images convey the complementary multi-phase information for liver tumor segmentation (LiTS), which are crucial to assist the diagnosis of liver cancer clinically. However, the performances of existing multi-phase liver tumor segmentation (MPLiTS)-based methods suffer from redundancy and weak interpretability, % of the fused result, resulting in the implicit unreliability of clinical applications. In this paper, we propose a novel trustworthy multi-phase liver tumor segmentation (TMPLiTS), which is a unified framework jointly conducting segmentation and uncertainty estimation. The trustworthy results could assist the clinicians to make a reliable diagnosis. Specifically, Dempster-Shafer Evidence Theory (DST) is introduced to parameterize the segmentation and uncertainty as evidence following Dirichlet distribution. The reliability of segmentation results among multi-phase CECT images is quantified explicitly. Meanwhile, a multi-expert mixture scheme (MEMS) is proposed to fuse the multi-phase evidences, which can guarantee the effect of fusion procedure based on theoretical analysis. Experimental results demonstrate the superiority of TMPLiTS compared with the state-of-the-art methods. Meanwhile, the robustness of TMPLiTS is verified, where the reliable performance can be guaranteed against the perturbations.
When SAM Meets Medical Images: An Investigation of Segment Anything Model (SAM) on Multi-phase Liver Tumor Segmentation
May 04, 2023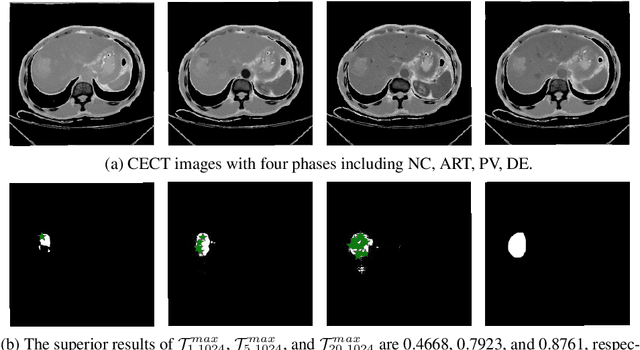
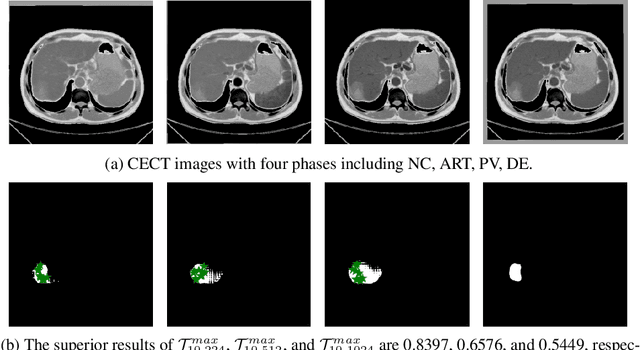
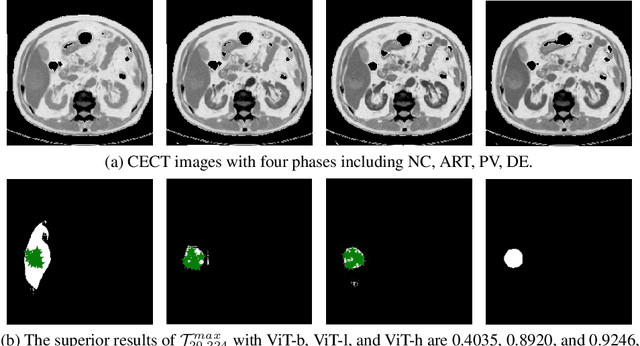
Learning to segmentation without large-scale samples is an inherent capability of human. Recently, Segment Anything Model (SAM) performs the significant zero-shot image segmentation, attracting considerable attention from the computer vision community. Here, we investigate the capability of SAM for medical image analysis, especially for multi-phase liver tumor segmentation (MPLiTS), in terms of prompts, data resolution, phases. Experimental results demonstrate that there might be a large gap between SAM and expected performance. Fortunately, the qualitative results show that SAM is a powerful annotation tool for the community of interactive medical image segmentation.
TNTC: two-stream network with transformer-based complementarity for gait-based emotion recognition
Oct 26, 2021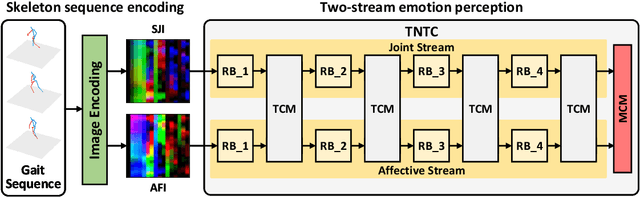

Recognizing the human emotion automatically from visual characteristics plays a vital role in many intelligent applications. Recently, gait-based emotion recognition, especially gait skeletons-based characteristic, has attracted much attention, while many available methods have been proposed gradually. The popular pipeline is to first extract affective features from joint skeletons, and then aggregate the skeleton joint and affective features as the feature vector for classifying the emotion. However, the aggregation procedure of these emerged methods might be rigid, resulting in insufficiently exploiting the complementary relationship between skeleton joint and affective features. Meanwhile, the long range dependencies in both spatial and temporal domains of the gait sequence are scarcely considered. To address these issues, we propose a novel two-stream network with transformer-based complementarity, termed as TNTC. Skeleton joint and affective features are encoded into two individual images as the inputs of two streams, respectively. A new transformer-based complementarity module (TCM) is proposed to bridge the complementarity between two streams hierarchically via capturing long range dependencies. Experimental results demonstrate TNTC outperforms state-of-the-art methods on the latest dataset in terms of accuracy.
A self-supervised learning-based 6-DOF grasp planning method for manipulator
Jan 30, 2021
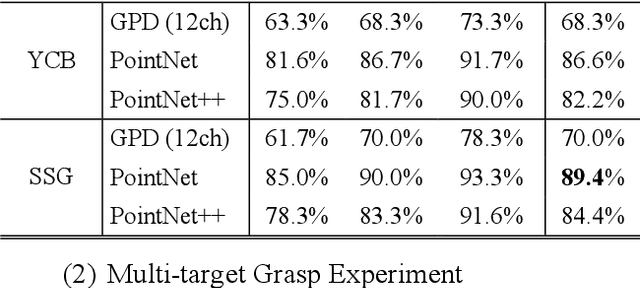
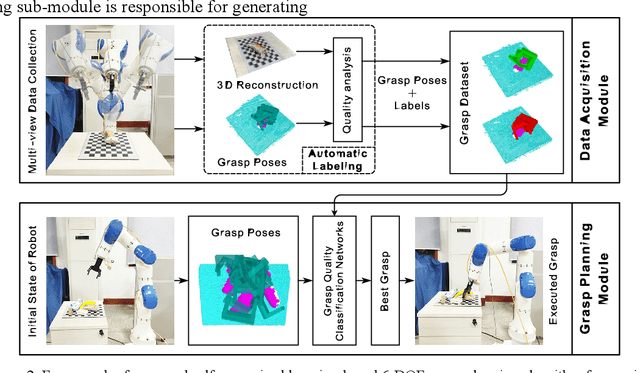
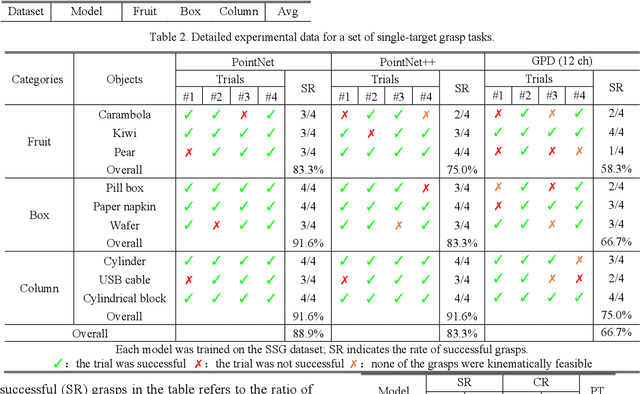
To realize a robust robotic grasping system for unknown objects in an unstructured environment, large amounts of grasp data and 3D model data for the object are required, the sizes of which directly affect the rate of successful grasps. To reduce the time cost of data acquisition and labeling and increase the rate of successful grasps, we developed a self-supervised learning mechanism to control grasp tasks performed by manipulators. First, a manipulator automatically collects the point cloud for the objects from multiple perspectives to increase the efficiency of data acquisition. The complete point cloud for the objects is obtained by utilizing the hand-eye vision of the manipulator, and the TSDF algorithm. Then, the point cloud data for the objects is used to generate a series of six-degrees-of-freedom grasp poses, and the force-closure decision algorithm is used to add the grasp quality label to each grasp pose to realize the automatic labeling of grasp data. Finally, the point cloud in the gripper closing area corresponding to each grasp pose is obtained; it is then used to train the grasp-quality classification model for the manipulator. The results of data acquisition experiments demonstrate that the proposed method allows high-quality data to be obtained. The simulated results prove the effectiveness of the proposed grasp-data acquisition method. The results of performing actual grasping experiments demonstrate that the proposed self-supervised learning method can increase the rate of successful grasps for the manipulator.
Calibration of the internal and external parameters of wheeled robot mobile chasses and inertial measurement units based on nonlinear optimization
May 17, 2020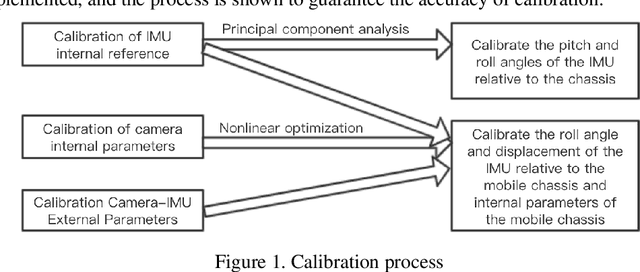
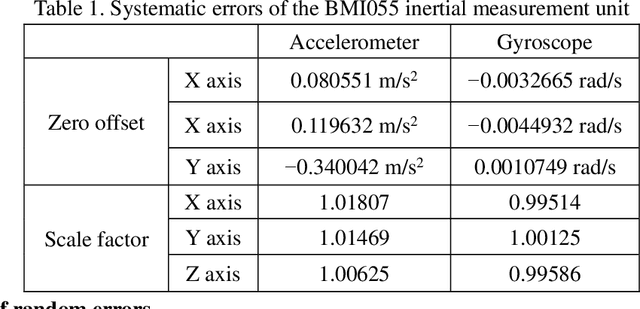
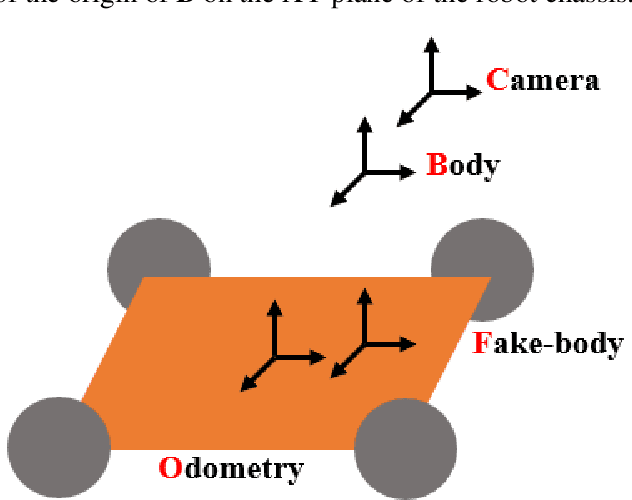
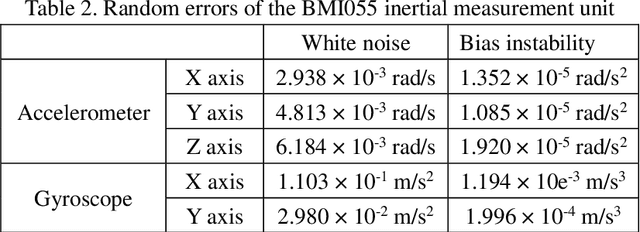
Mobile robot positioning, mapping, and navigation systems generally employ an inertial measurement unit (IMU) to obtain the acceleration and angular velocity of the robot. However, errors in the internal and external parameters of an IMU arising from defective calibration directly affect the accuracy of robot positioning and pose estimation. While this issue has been addressed by the mature internal reference calibration methods available for IMUs, external reference calibration methods between the IMU and the chassis of a mobile robot are lacking. This study addresses this issue by proposing a novel chassis-IMU internal and external parameter calibration algorithm based on nonlinear optimization, which is designed for robots equipped with cameras, IMUs, and wheel speed odometers, and functions under the premise of accurate calibrations for the internal parameters of the IMU and the internal and external parameters of the camera. All of the internal and external reference calibrations are conducted using the robot's existing equipment without the need for additional calibration aids. The feasibility of the method is verified by its application to a Mecanum wheel omnidirectional mobile platform as an example, as well as suitable for other type chassis of mobile robots. The proposed calibration method is thereby demonstrated to guarantee the accuracy of robot pose estimation.
Enrichment of Qualitative Beliefs for Reasoning under Uncertainty
Sep 11, 2007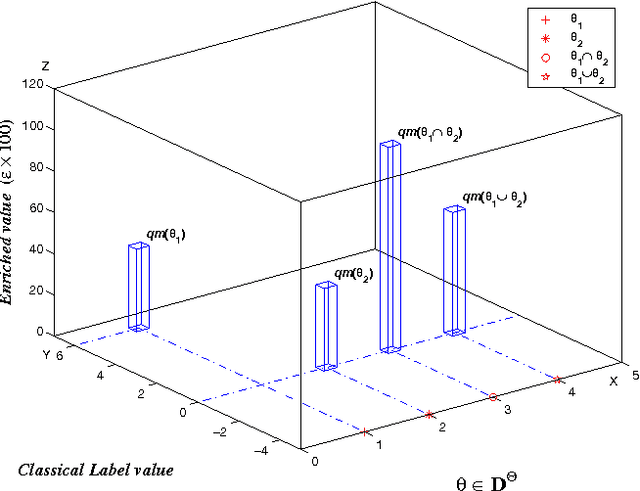
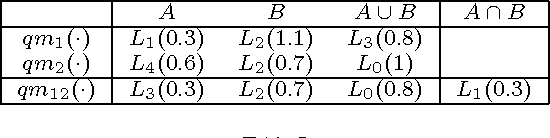
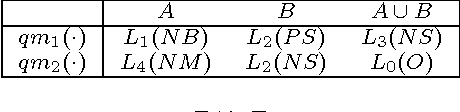

This paper deals with enriched qualitative belief functions for reasoning under uncertainty and for combining information expressed in natural language through linguistic labels. In this work, two possible enrichments (quantitative and/or qualitative) of linguistic labels are considered and operators (addition, multiplication, division, etc) for dealing with them are proposed and explained. We denote them $qe$-operators, $qe$ standing for "qualitative-enriched" operators. These operators can be seen as a direct extension of the classical qualitative operators ($q$-operators) proposed recently in the Dezert-Smarandache Theory of plausible and paradoxist reasoning (DSmT). $q$-operators are also justified in details in this paper. The quantitative enrichment of linguistic label is a numerical supporting degree in $[0,\infty)$, while the qualitative enrichment takes its values in a finite ordered set of linguistic values. Quantitative enrichment is less precise than qualitative enrichment, but it is expected more close with what human experts can easily provide when expressing linguistic labels with supporting degrees. Two simple examples are given to show how the fusion of qualitative-enriched belief assignments can be done.