 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent Signal Theory: A Computational Framework for Intent-State Control in Human-AI Interaction
May 24, 2026Current AI interaction models treat the prompt as the primary object of exchange, omitting a critical layer: the user's latent source intent, the goal state preceding and motivating the prompt. Here we introduce Intent Signal Theory (IST), a computational framework that formalises this missing intent layer. IST distinguishes four objects routinely conflated: latent source intent (I*), observable intent proxy (I-hat), encoded carrier (P), and model output (O). It formalises dimensional weights, encoding masks, structural and fidelity recovery scores, and public-private intent decomposition. The Theorem of Irreversible Intent Loss establishes that private intent absent from the carrier cannot be recovered beyond generic substitution. Evidence from four companion studies spanning six LLMs, three languages and three task domains shows structural-fidelity splits, human-validated metric dissociation, and weight-tolerance plateaus consistent with IST's predictions. IST reframes prompt engineering as intent-protocol design and identifies a computational layer that current AI systems lack.
BatchLLM: Optimizing Large Batched LLM Inference with Global Prefix Sharing and Throughput-oriented Token Batching
Nov 29, 2024Many LLM tasks are performed in large batches or even offline, and the performance indictor for which is throughput. These tasks usually show the characteristic of prefix sharing, where different prompt input can partially show the common prefix. However, the existing LLM inference engines tend to optimize the streaming requests and show limitations of supporting the large batched tasks with the prefix sharing characteristic. The existing solutions use the LRU-based cache to reuse the KV context of common prefix. The KV context that is about to be reused may prematurely be evicted with the implicit cache management. Even if not evicted, the lifetime of the shared KV context is extended since requests sharing the same context are not scheduled together, resulting in larger memory usage. These streaming oriented systems schedule the requests in the first-come-first-serve or similar order. As a result, the requests with larger ratio of decoding steps may be scheduled too late to be able to mix with the prefill chunks to increase the hardware utilization. Besides, the token and request number based batching can limit the size of token-batch, which keeps the GPU from saturating for the iterations dominated by decoding tokens. We propose BatchLLM to address the above problems. BatchLLM explicitly identifies the common prefixes globally. The requests sharing the same prefix will be scheduled together to reuse the KV context the best, which also shrinks the lifetime of common KV memory. BatchLLM reorders the requests and schedules the requests with larger ratio of decoding first to better mix the decoding tokens with the latter prefill chunks and applies memory-centric token batching to enlarge the token-batch sizes, which helps to increase the GPU utilization. Extensive evaluation shows that BatchLLM outperforms vLLM by 1.1x to 2x on a set of microbenchmarks and two typical industry workloads.
A self-supervised learning-based 6-DOF grasp planning method for manipulator
Jan 30, 2021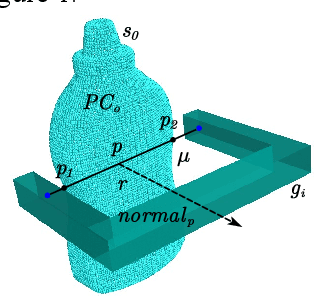
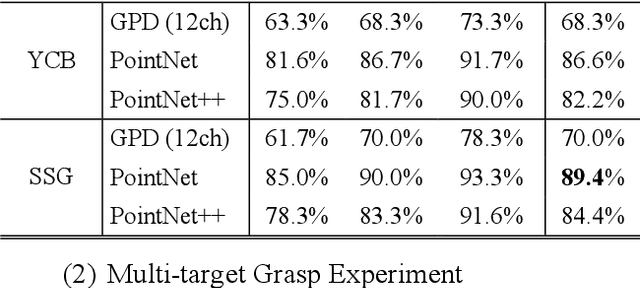
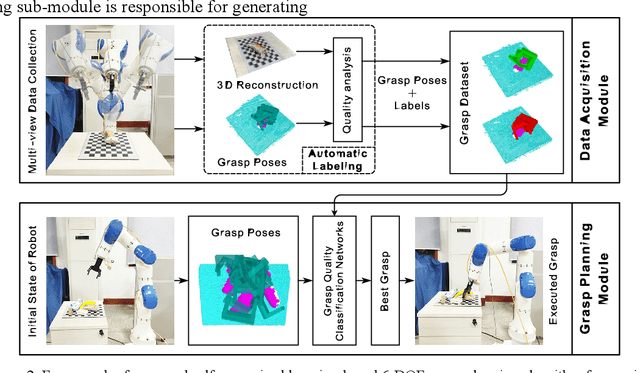
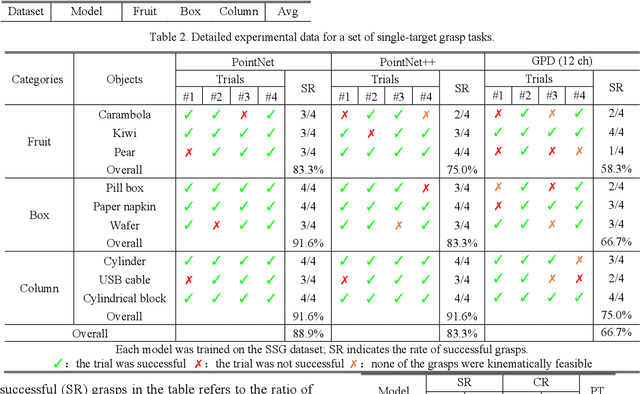
To realize a robust robotic grasping system for unknown objects in an unstructured environment, large amounts of grasp data and 3D model data for the object are required, the sizes of which directly affect the rate of successful grasps. To reduce the time cost of data acquisition and labeling and increase the rate of successful grasps, we developed a self-supervised learning mechanism to control grasp tasks performed by manipulators. First, a manipulator automatically collects the point cloud for the objects from multiple perspectives to increase the efficiency of data acquisition. The complete point cloud for the objects is obtained by utilizing the hand-eye vision of the manipulator, and the TSDF algorithm. Then, the point cloud data for the objects is used to generate a series of six-degrees-of-freedom grasp poses, and the force-closure decision algorithm is used to add the grasp quality label to each grasp pose to realize the automatic labeling of grasp data. Finally, the point cloud in the gripper closing area corresponding to each grasp pose is obtained; it is then used to train the grasp-quality classification model for the manipulator. The results of data acquisition experiments demonstrate that the proposed method allows high-quality data to be obtained. The simulated results prove the effectiveness of the proposed grasp-data acquisition method. The results of performing actual grasping experiments demonstrate that the proposed self-supervised learning method can increase the rate of successful grasps for the manipulator.
Deep Reinforcement Learning with Stage Incentive Mechanism for Robotic Trajectory Planning
Sep 25, 2020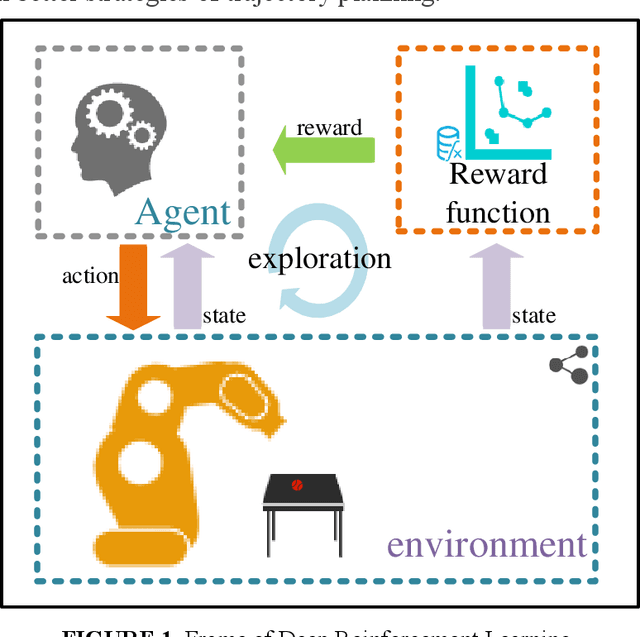

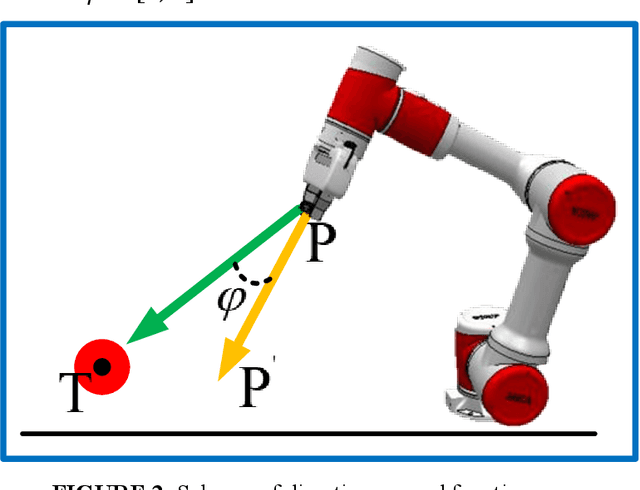
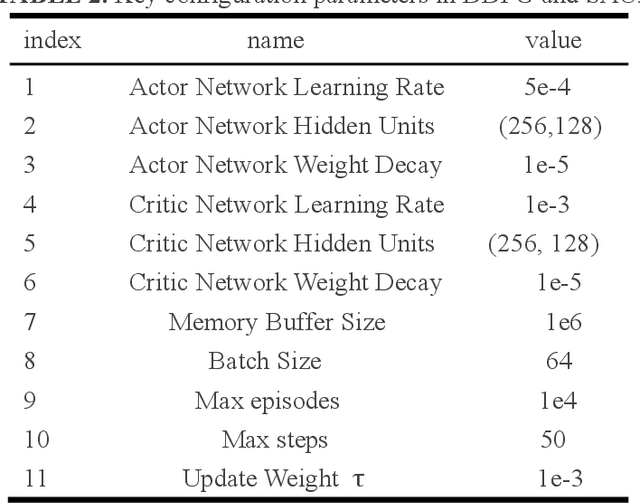
To improve the efficiency of deep reinforcement learning (DRL) based methods for robot manipulator trajectory planning in random working environment. Different from the traditional sparse reward function, we present three dense reward functions in this paper. Firstly, posture reward function is proposed to accelerate the learning process with a more reasonable trajectory by modeling the distance and direction constraints, which can reduce the blindness of exploration. Secondly, to improve the stability, a reward function at stride reward is proposed by modeling the distance and movement distance of joints constraints, it can make the learning process more stable. In order to further improve learning efficiency, we are inspired by the cognitive process of human behavior and propose a stage incentive mechanism, including hard stage incentive reward function and soft stage incentive reward function. Extensive experiments show that the soft stage incentive reward function proposed is able to improve convergence rate by up to 46.9% with the state-of-the-art DRL methods. The percentage increase in convergence mean reward is 4.4%~15.5% and the percentage decreases with respect to standard deviation by 21.9%~63.2%. In the evaluation, the success rate of trajectory planning for robot manipulator is up to 99.6%.
Calibration of the internal and external parameters of wheeled robot mobile chasses and inertial measurement units based on nonlinear optimization
May 17, 2020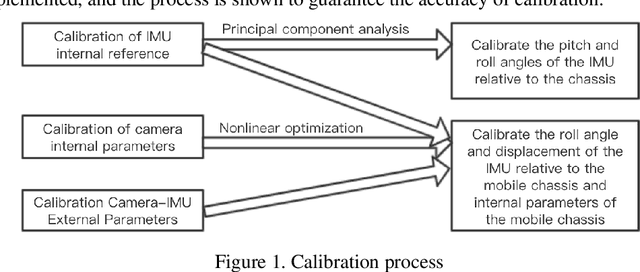
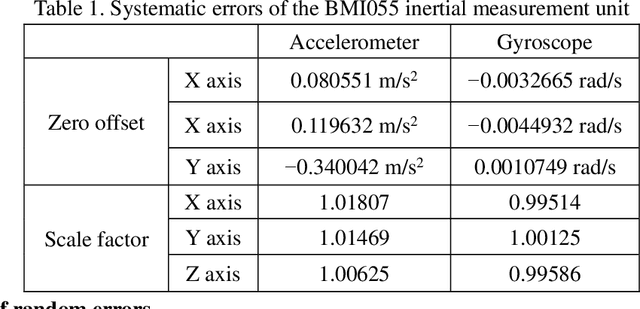
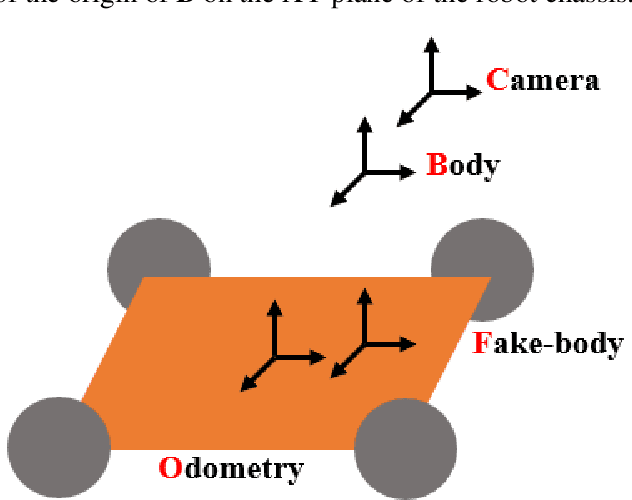
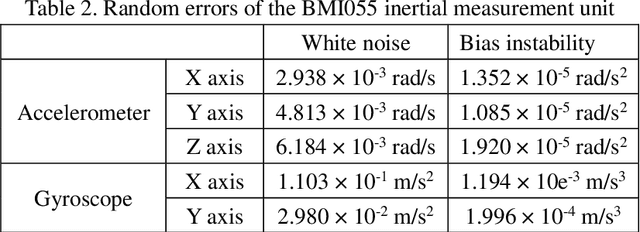
Mobile robot positioning, mapping, and navigation systems generally employ an inertial measurement unit (IMU) to obtain the acceleration and angular velocity of the robot. However, errors in the internal and external parameters of an IMU arising from defective calibration directly affect the accuracy of robot positioning and pose estimation. While this issue has been addressed by the mature internal reference calibration methods available for IMUs, external reference calibration methods between the IMU and the chassis of a mobile robot are lacking. This study addresses this issue by proposing a novel chassis-IMU internal and external parameter calibration algorithm based on nonlinear optimization, which is designed for robots equipped with cameras, IMUs, and wheel speed odometers, and functions under the premise of accurate calibrations for the internal parameters of the IMU and the internal and external parameters of the camera. All of the internal and external reference calibrations are conducted using the robot's existing equipment without the need for additional calibration aids. The feasibility of the method is verified by its application to a Mecanum wheel omnidirectional mobile platform as an example, as well as suitable for other type chassis of mobile robots. The proposed calibration method is thereby demonstrated to guarantee the accuracy of robot pose estimation.
Single upper limb pose estimation method based on improved stacked hourglass network
Apr 16, 2020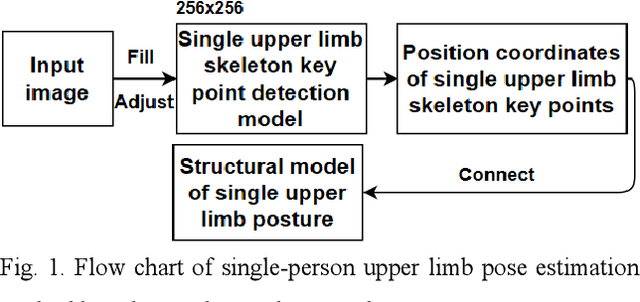
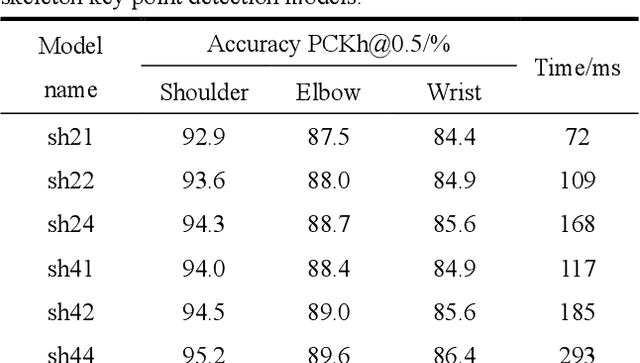
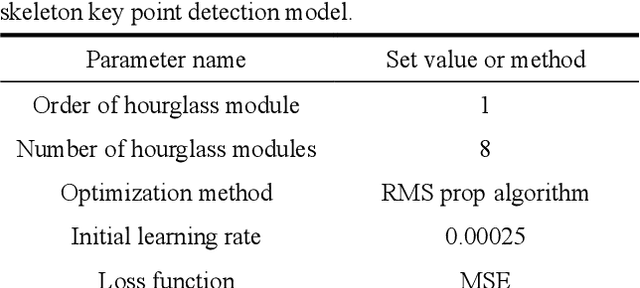

At present, most high-accuracy single-person pose estimation methods have high computational complexity and insufficient real-time performance due to the complex structure of the network model. However, a single-person pose estimation method with high real-time performance also needs to improve its accuracy due to the simple structure of the network model. It is currently difficult to achieve both high accuracy and real-time performance in single-person pose estimation. For use in human-machine cooperative operations, this paper proposes a single-person upper limb pose estimation method based on an end-to-end approach for accurate and real-time limb pose estimation. Using the stacked hourglass network model, a single-person upper limb skeleton key point detection model was designed.Deconvolution was employed to replace the up-sampling operation of the hourglass module in the original model, solving the problem of rough feature maps. Integral regression was used to calculate the position coordinates of key points of the skeleton, reducing quantization errors and calculations. Experiments showed that the developed single-person upper limb skeleton key point detection model achieves high accuracy and that the pose estimation method based on the end-to-end approach provides high accuracy and real-time performance.
Computer-aided diagnosis in histopathological images of the endometrium using a convolutional neural network and attention mechanisms
Apr 24, 2019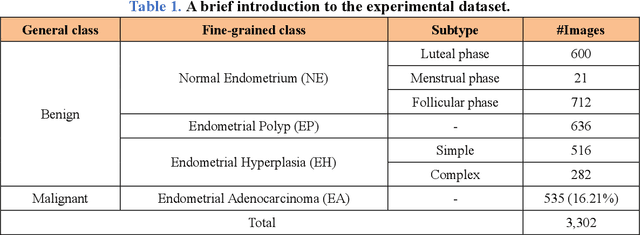
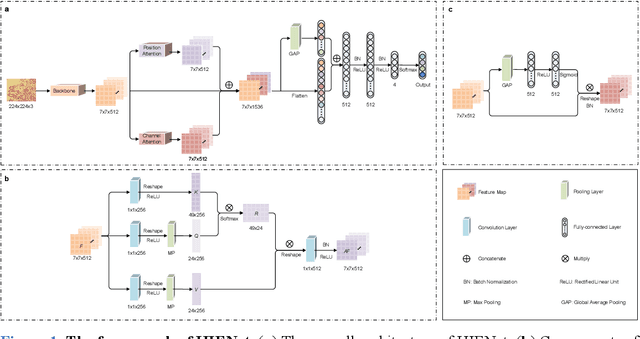
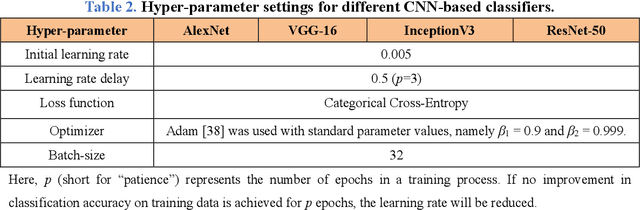
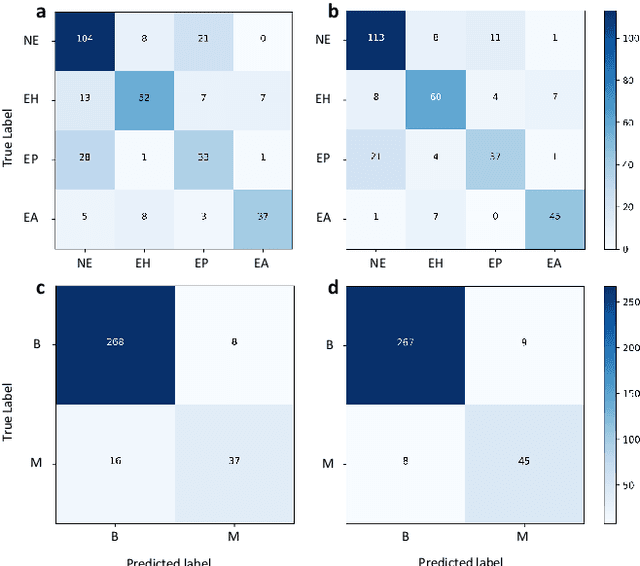
Uterine cancer, also known as endometrial cancer, can seriously affect the female reproductive organs, and histopathological image analysis is the gold standard for diagnosing endometrial cancer. However, due to the limited capability of modeling the complicated relationships between histopathological images and their interpretations, these computer-aided diagnosis (CADx) approaches based on traditional machine learning algorithms often failed to achieve satisfying results. In this study, we developed a CADx approach using a convolutional neural network (CNN) and attention mechanisms, called HIENet. Because HIENet used the attention mechanisms and feature map visualization techniques, it can provide pathologists better interpretability of diagnoses by highlighting the histopathological correlations of local (pixel-level) image features to morphological characteristics of endometrial tissue. In the ten-fold cross-validation process, the CADx approach, HIENet, achieved a 76.91 $\pm$ 1.17% (mean $\pm$ s. d.) classification accuracy for four classes of endometrial tissue, namely normal endometrium, endometrial polyp, endometrial hyperplasia, and endometrial adenocarcinoma. Also, HIENet achieved an area-under-the-curve (AUC) of 0.9579 $\pm$ 0.0103 with an 81.04 $\pm$ 3.87% sensitivity and 94.78 $\pm$ 0.87% specificity in a binary classification task that detected endometrioid adenocarcinoma (Malignant). Besides, in the external validation process, HIENet achieved an 84.50% accuracy in the four-class classification task, and it achieved an AUC of 0.9829 with a 77.97% (95% CI, 65.27%-87.71%) sensitivity and 100% (95% CI, 97.42%-100.00%) specificity. In summary, the proposed CADx approach, HIENet, outperformed three human experts and four end-to-end CNN-based classifiers on this small-scale dataset composed of 3,500 hematoxylin and eosin (H&E) images regarding overall classification performance.
Parallel Convolutional Networks for Image Recognition via a Discriminator
Sep 25, 2018
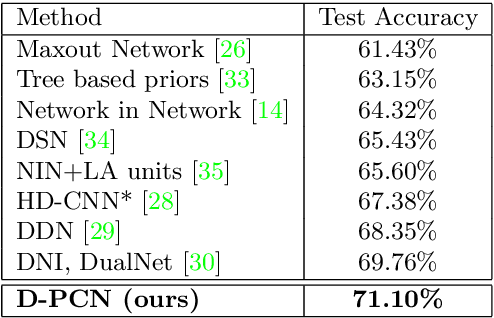

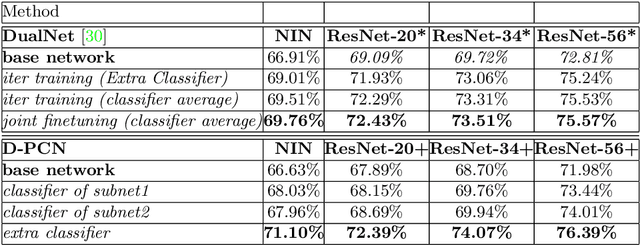
In this paper, we introduce a simple but quite effective recognition framework dubbed D-PCN, aiming at enhancing feature extracting ability of CNN. The framework consists of two parallel CNNs, a discriminator and an extra classifier which takes integrated features from parallel networks and gives final prediction. The discriminator is core which drives parallel networks to focus on different regions and learn different representations. The corresponding training strategy is introduced to ensures utilization of discriminator. We validate D-PCN with several CNN models on benchmark datasets: CIFAR-100, and ImageNet, D-PCN enhances all models. In particular it yields state of the art performance on CIFAR-100 compared with related works. We also conduct visualization experiment on fine-grained Stanford Dogs dataset to verify our motivation. Additionally, we apply D-PCN for segmentation on PASCAL VOC 2012 and also find promotion.
Capsule Deep Neural Network for Recognition of Historical Graffiti Handwriting
Sep 11, 2018

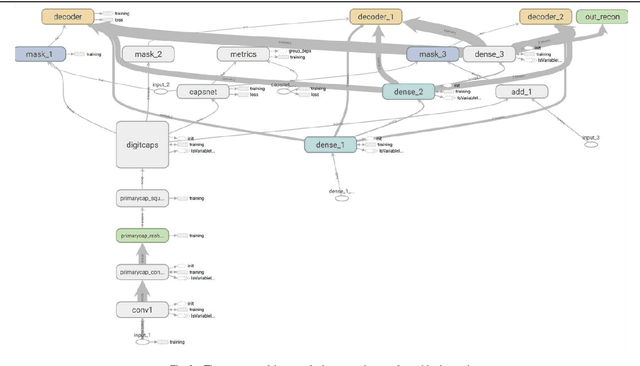

Automatic recognition of the historical letters (XI-XVIII centuries) carved on the stoned walls of St.Sophia cathedral in Kyiv (Ukraine) was demonstrated by means of capsule deep learning neural network. It was applied to the image dataset of the carved Glagolitic and Cyrillic letters (CGCL), which was assembled and pre-processed recently for recognition and prediction by machine learning methods (https://www.kaggle.com/yoctoman/graffiti-st-sophia-cathedral-kyiv). CGCL dataset contains >4000 images for glyphs of 34 letters which are hardly recognized by experts even in contrast to notMNIST dataset with the better images of 10 letters taken from different fonts. Despite the much worse quality of CGCL dataset and extremely low number of samples (in comparison to notMNIST dataset) the capsule network model demonstrated much better results than the previously used convolutional neural network (CNN). The validation accuracy (and validation loss) was higher (lower) for capsule network model than for CNN without data augmentation even. The area under curve (AUC) values for receiver operating characteristic (ROC) were also higher for the capsule network model than for CNN model: 0.88-0.93 (capsule network) and 0.50 (CNN) without data augmentation, 0.91-0.95 (capsule network) and 0.51 (CNN) with lossless data augmentation, and similar results of 0.91-0.93 (capsule network) and 0.9 (CNN) in the regime of lossless data augmentation only. The confusion matrixes were much better for capsule network than for CNN model and gave the much lower type I (false positive) and type II (false negative) values in all three regimes of data augmentation. These results supports the previous claims that capsule-like networks allow to reduce error rates not only on MNIST digit dataset, but on the other notMNIST letter dataset and the more complex CGCL handwriting graffiti letter dataset also.
Parallel Statistical and Machine Learning Methods for Estimation of Physical Load
Aug 14, 2018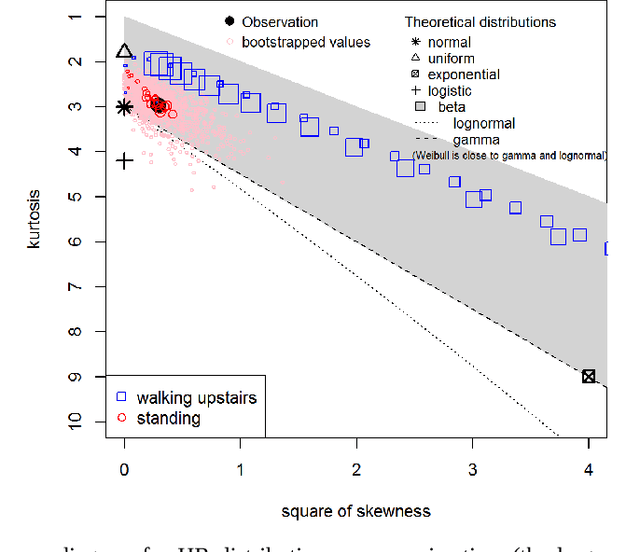
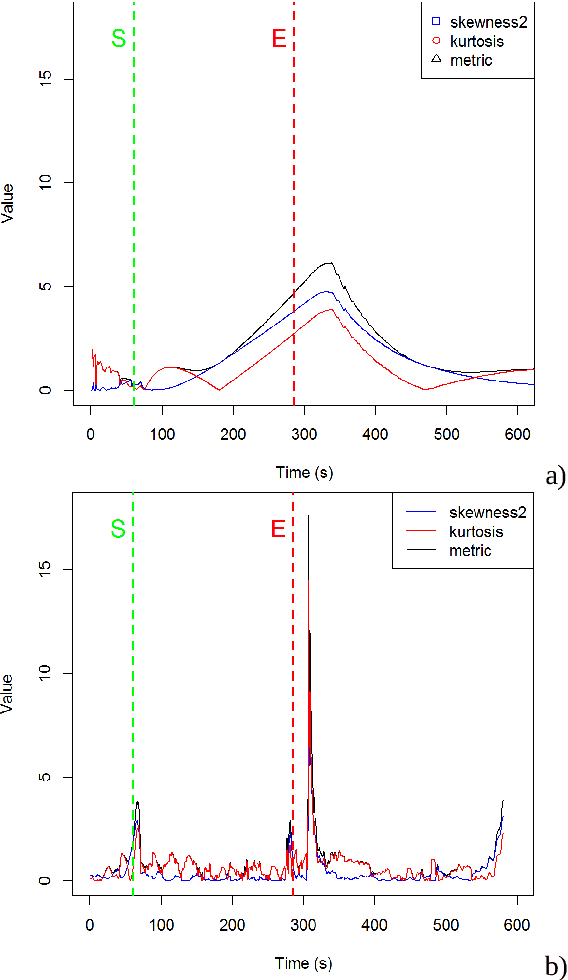
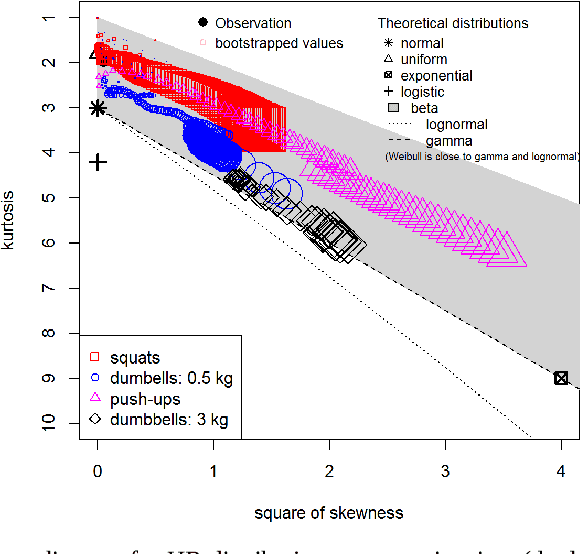
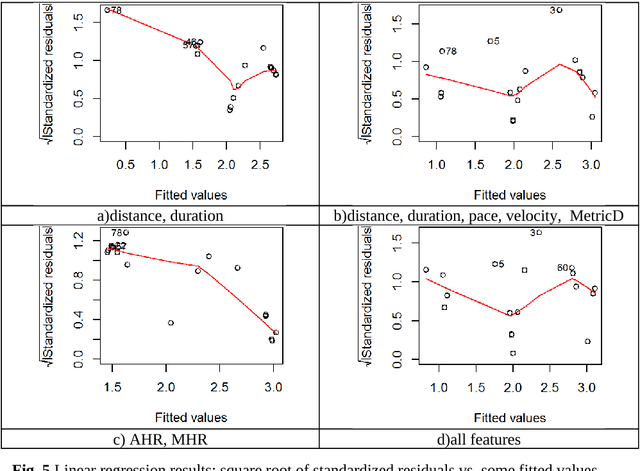
Several statistical and machine learning methods are proposed to estimate the type and intensity of physical load and accumulated fatigue . They are based on the statistical analysis of accumulated and moving window data subsets with construction of a kurtosis-skewness diagram. This approach was applied to the data gathered by the wearable heart monitor for various types and levels of physical activities, and for people with various physical conditions. The different levels of physical activities, loads, and fitness can be distinguished from the kurtosis-skewness diagram, and their evolution can be monitored. Several metrics for estimation of the instant effect and accumulated effect (physical fatigue) of physical loads were proposed. The data and results presented allow to extend application of these methods for modeling and characterization of complex human activity patterns, for example, to estimate the actual and accumulated physical load and fatigue, model the potential dangerous development, and give cautions and advice in real time.