 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Model Based on Masked Autoencoders Advance CT Scans Classification
Oct 11, 2022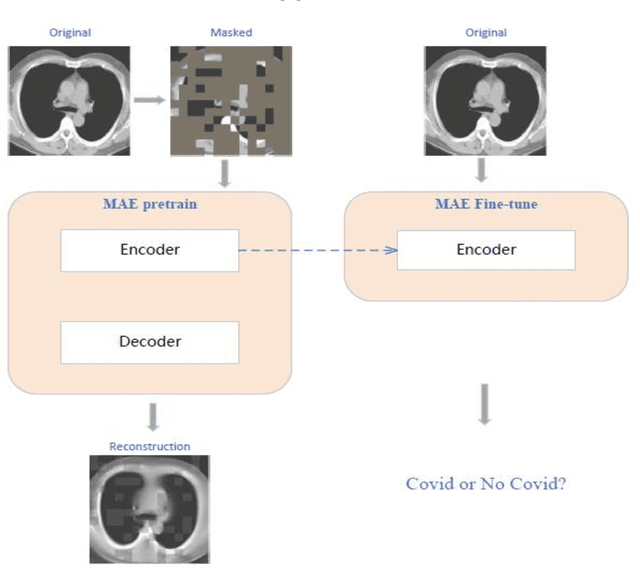
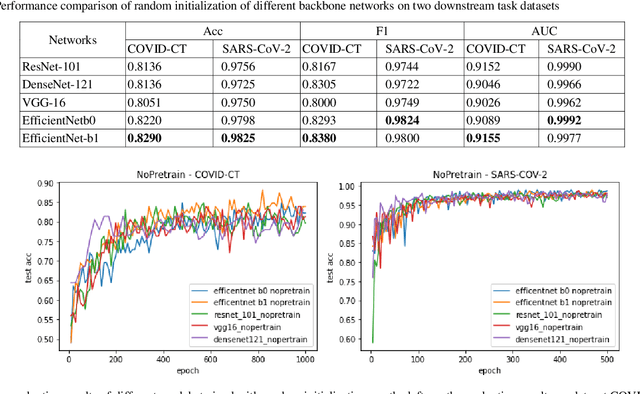
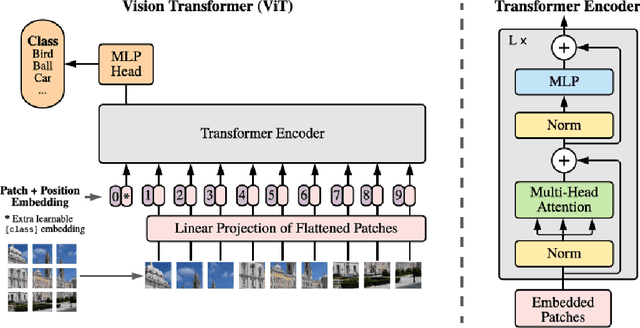
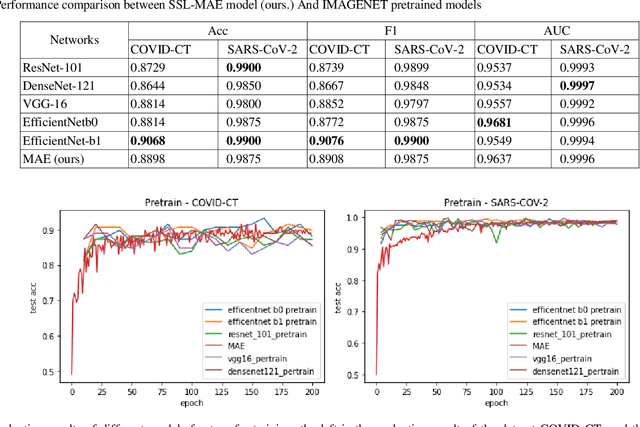
The coronavirus pandemic has been going on since the year 2019, and the trend is still not abating. Therefore, it is particularly important to classify medical CT scans to assist in medical diagnosis. At present, Supervised Deep Learning algorithms have made a great success in the classification task of medical CT scans, but medical image datasets often require professional image annotation, and many research datasets are not publicly available. To solve this problem, this paper is inspired by the self-supervised learning algorithm MAE and uses the MAE model pre-trained on ImageNet to perform transfer learning on CT Scans dataset. This method improves the generalization performance of the model and avoids the risk of overfitting on small datasets. Through extensive experiments on the COVID-CT dataset and the SARS-CoV-2 dataset, we compare the SSL-based method in this paper with other state-of-the-art supervised learning-based pretraining methods. Experimental results show that our method improves the generalization performance of the model more effectively and avoids the risk of overfitting on small datasets. The model achieved almost the same accuracy as supervised learning on both test datasets. Finally, ablation experiments aim to fully demonstrate the effectiveness of our method and how it works.
Prediction of Physical Load Level by Machine Learning Analysis of Heart Activity after Exercises
Dec 20, 2019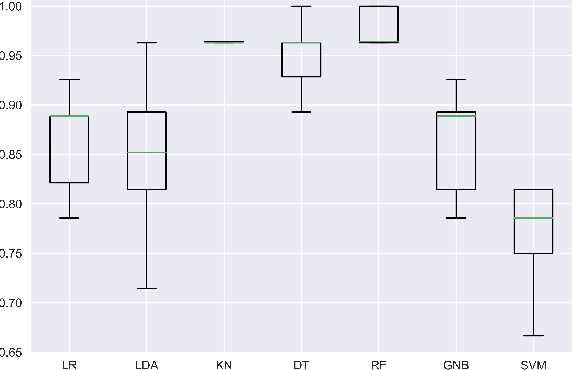
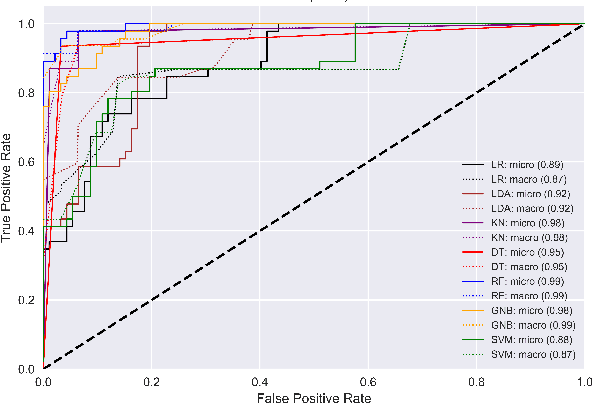
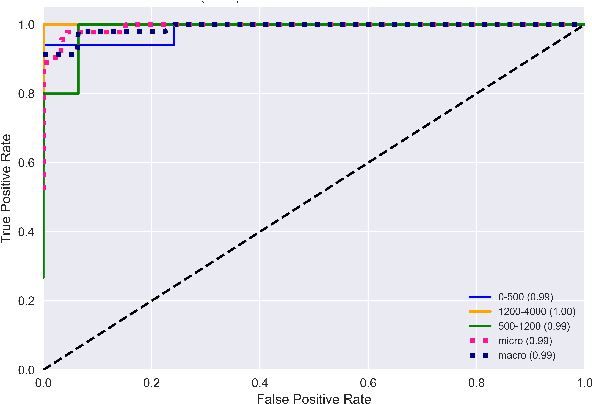
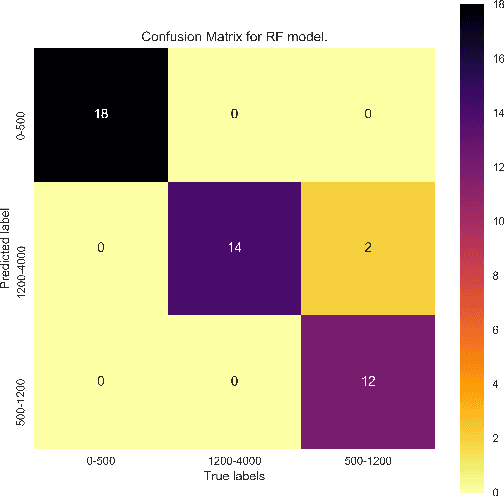
The assessment of energy expenditure in real life is of great importance for monitoring the current physical state of people, especially in work, sport, elderly care, health care, and everyday life even. This work reports about application of some machine learning methods (linear regression, linear discriminant analysis, k-nearest neighbors, decision tree, random forest, Gaussian naive Bayes, support-vector machine) for monitoring energy expenditures in athletes. The classification problem was to predict the known level of the in-exercise loads (in three categories by calories) by the heart rate activity features measured during the short period of time (1 minute only) after training, i.e by features of the post-exercise load. The results obtained shown that the post-exercise heart activity features preserve the information of the in-exercise training loads and allow us to predict their actual in-exercise levels. The best performance can be obtained by the random forest classifier with all 8 heart rate features (micro-averaged area under curve value AUCmicro = 0.87 and macro-averaged one AUCmacro = 0.88) and the k-nearest neighbors classifier with 4 most important heart rate features (AUCmicro = 0.91 and AUCmacro = 0.89). The limitations and perspectives of the ML methods used are outlined, and some practical advices are proposed as to their improvement and implementation for the better prediction of in-exercise energy expenditures.
Batch Size Influence on Performance of Graphic and Tensor Processing Units during Training and Inference Phases
Dec 31, 2018
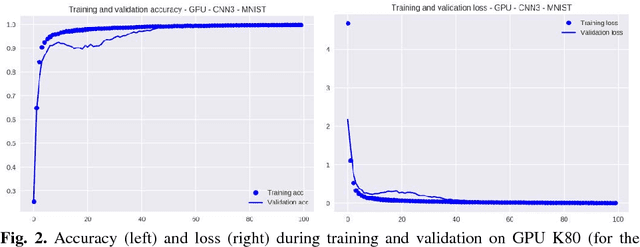
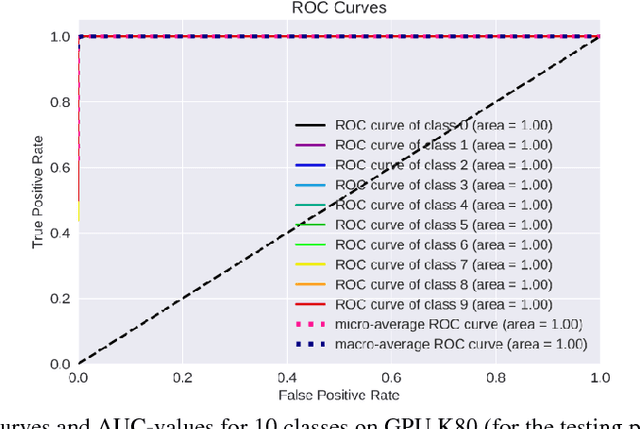
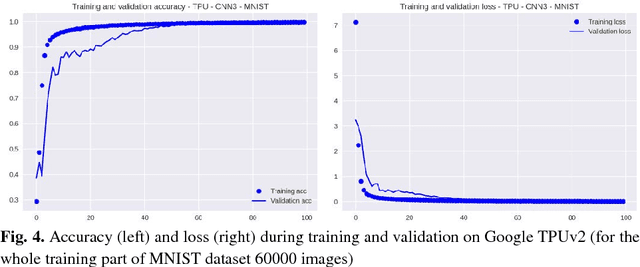
The impact of the maximally possible batch size (for the better runtime) on performance of graphic processing units (GPU) and tensor processing units (TPU) during training and inference phases is investigated. The numerous runs of the selected deep neural network (DNN) were performed on the standard MNIST and Fashion-MNIST datasets. The significant speedup was obtained even for extremely low-scale usage of Google TPUv2 units (8 cores only) in comparison to the quite powerful GPU NVIDIA Tesla K80 card with the speedup up to 10x for training stage (without taking into account the overheads) and speedup up to 2x for prediction stage (with and without taking into account overheads). The precise speedup values depend on the utilization level of TPUv2 units and increase with the increase of the data volume under processing, but for the datasets used in this work (MNIST and Fashion-MNIST with images of sizes 28x28) the speedup was observed for batch sizes >512 images for training phase and >40 000 images for prediction phase. It should be noted that these results were obtained without detriment to the prediction accuracy and loss that were equal for both GPU and TPU runs up to the 3rd significant digit for MNIST dataset, and up to the 2nd significant digit for Fashion-MNIST dataset.
Impact of Ground Truth Annotation Quality on Performance of Semantic Image Segmentation of Traffic Conditions
Dec 30, 2018

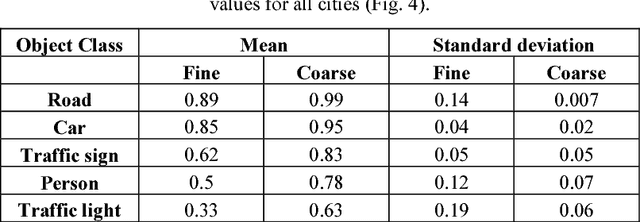
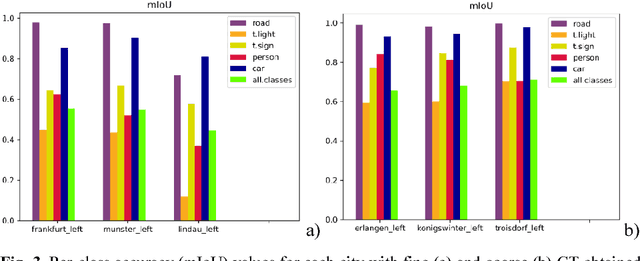
Preparation of high-quality datasets for the urban scene understanding is a labor-intensive task, especially, for datasets designed for the autonomous driving applications. The application of the coarse ground truth (GT) annotations of these datasets without detriment to the accuracy of semantic image segmentation (by the mean intersection over union - mIoU) could simplify and speedup the dataset preparation and model fine tuning before its practical application. Here the results of the comparative analysis for semantic segmentation accuracy obtained by PSPNet deep learning architecture are presented for fine and coarse annotated images from Cityscapes dataset. Two scenarios were investigated: scenario 1 - the fine GT images for training and prediction, and scenario 2 - the fine GT images for training and the coarse GT images for prediction. The obtained results demonstrated that for the most important classes the mean accuracy values of semantic image segmentation for coarse GT annotations are higher than for the fine GT ones, and the standard deviation values are vice versa. It means that for some applications some unimportant classes can be excluded and the model can be tuned further for some classes and specific regions on the coarse GT dataset without loss of the accuracy even. Moreover, this opens the perspectives to use deep neural networks for the preparation of such coarse GT datasets.
Capsule Deep Neural Network for Recognition of Historical Graffiti Handwriting
Sep 11, 2018


Automatic recognition of the historical letters (XI-XVIII centuries) carved on the stoned walls of St.Sophia cathedral in Kyiv (Ukraine) was demonstrated by means of capsule deep learning neural network. It was applied to the image dataset of the carved Glagolitic and Cyrillic letters (CGCL), which was assembled and pre-processed recently for recognition and prediction by machine learning methods (https://www.kaggle.com/yoctoman/graffiti-st-sophia-cathedral-kyiv). CGCL dataset contains >4000 images for glyphs of 34 letters which are hardly recognized by experts even in contrast to notMNIST dataset with the better images of 10 letters taken from different fonts. Despite the much worse quality of CGCL dataset and extremely low number of samples (in comparison to notMNIST dataset) the capsule network model demonstrated much better results than the previously used convolutional neural network (CNN). The validation accuracy (and validation loss) was higher (lower) for capsule network model than for CNN without data augmentation even. The area under curve (AUC) values for receiver operating characteristic (ROC) were also higher for the capsule network model than for CNN model: 0.88-0.93 (capsule network) and 0.50 (CNN) without data augmentation, 0.91-0.95 (capsule network) and 0.51 (CNN) with lossless data augmentation, and similar results of 0.91-0.93 (capsule network) and 0.9 (CNN) in the regime of lossless data augmentation only. The confusion matrixes were much better for capsule network than for CNN model and gave the much lower type I (false positive) and type II (false negative) values in all three regimes of data augmentation. These results supports the previous claims that capsule-like networks allow to reduce error rates not only on MNIST digit dataset, but on the other notMNIST letter dataset and the more complex CGCL handwriting graffiti letter dataset also.
Open Source Dataset and Machine Learning Techniques for Automatic Recognition of Historical Graffiti
Aug 31, 2018

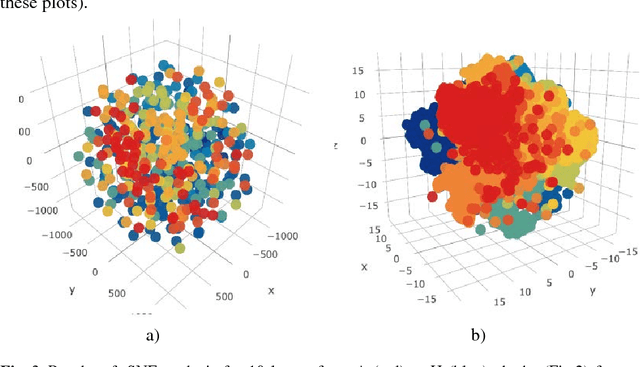
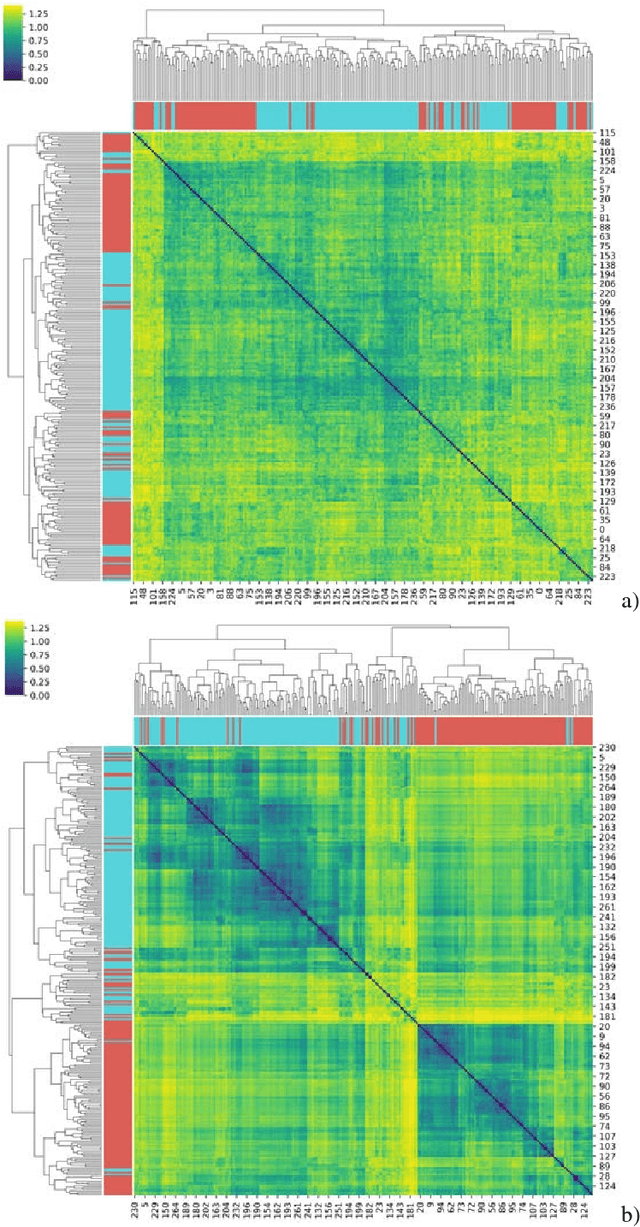
Machine learning techniques are presented for automatic recognition of the historical letters (XI-XVIII centuries) carved on the stoned walls of St.Sophia cathedral in Kyiv (Ukraine). A new image dataset of these carved Glagolitic and Cyrillic letters (CGCL) was assembled and pre-processed for recognition and prediction by machine learning methods. The dataset consists of more than 4000 images for 34 types of letters. The explanatory data analysis of CGCL and notMNIST datasets shown that the carved letters can hardly be differentiated by dimensionality reduction methods, for example, by t-distributed stochastic neighbor embedding (tSNE) due to the worse letter representation by stone carving in comparison to hand writing. The multinomial logistic regression (MLR) and a 2D convolutional neural network (CNN) models were applied. The MLR model demonstrated the area under curve (AUC) values for receiver operating characteristic (ROC) are not lower than 0.92 and 0.60 for notMNIST and CGCL, respectively. The CNN model gave AUC values close to 0.99 for both notMNIST and CGCL (despite the much smaller size and quality of CGCL in comparison to notMNIST) under condition of the high lossy data augmentation. CGCL dataset was published to be available for the data science community as an open source resource.
Parallel Statistical and Machine Learning Methods for Estimation of Physical Load
Aug 14, 2018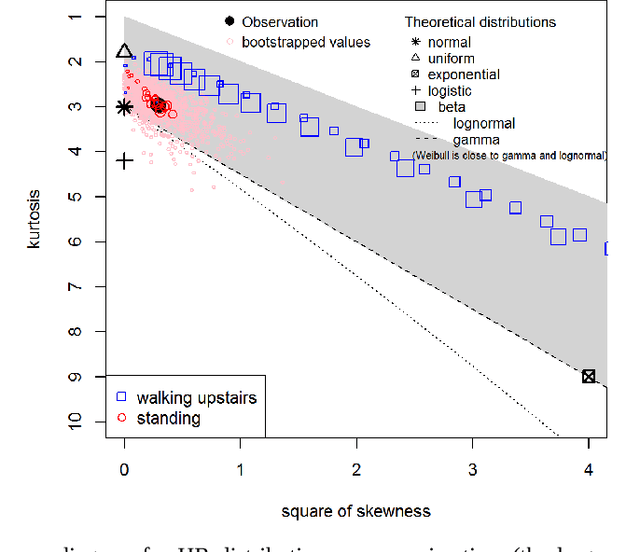
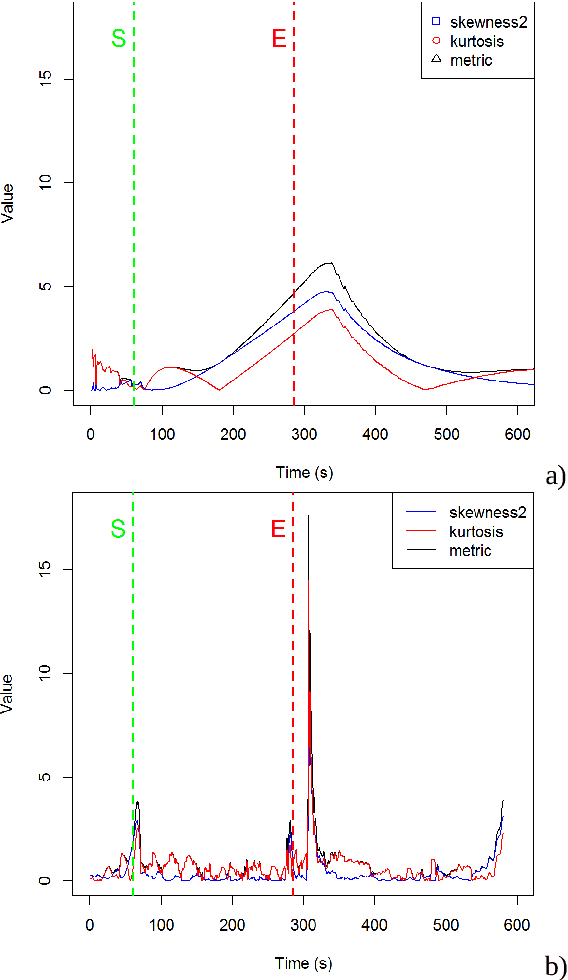
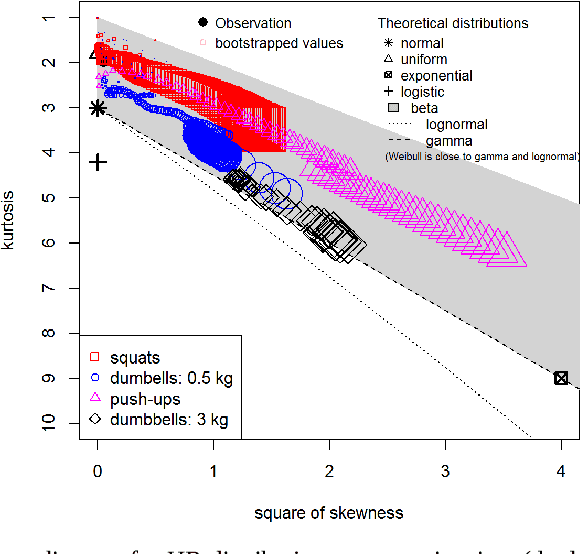
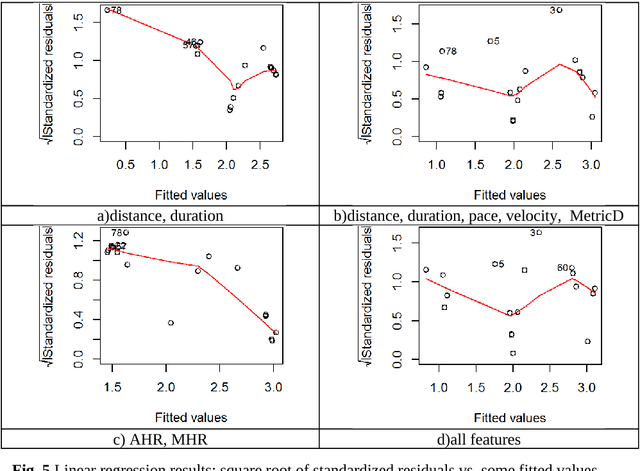
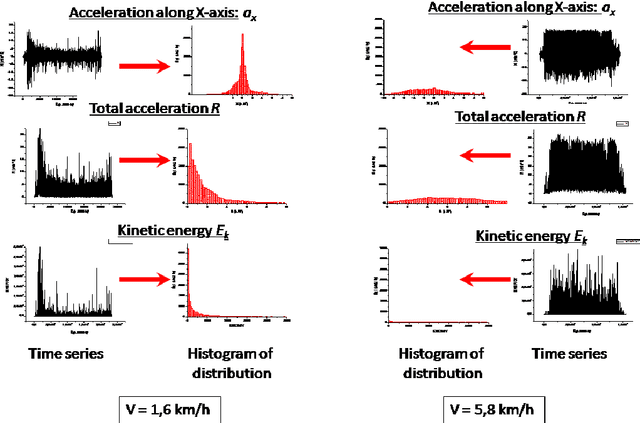
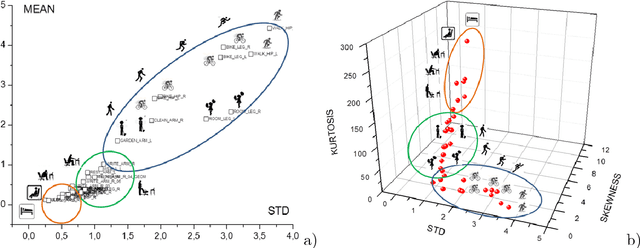
Several statistical and machine learning methods are proposed to estimate the type and intensity of physical load and accumulated fatigue . They are based on the statistical analysis of accumulated and moving window data subsets with construction of a kurtosis-skewness diagram. This approach was applied to the data gathered by the wearable heart monitor for various types and levels of physical activities, and for people with various physical conditions. The different levels of physical activities, loads, and fitness can be distinguished from the kurtosis-skewness diagram, and their evolution can be monitored. Several metrics for estimation of the instant effect and accumulated effect (physical fatigue) of physical loads were proposed. The data and results presented allow to extend application of these methods for modeling and characterization of complex human activity patterns, for example, to estimate the actual and accumulated physical load and fatigue, model the potential dangerous development, and give cautions and advice in real time.
Performance Evaluation of Deep Learning Networks for Semantic Segmentation of Traffic Stereo-Pair Images
Jun 05, 2018
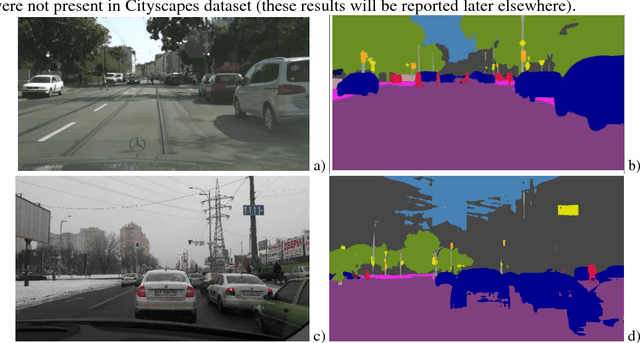
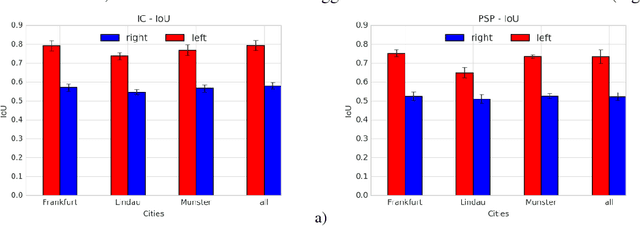
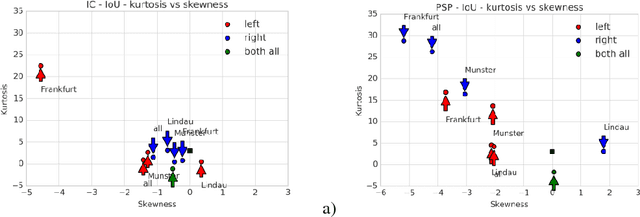
Semantic image segmentation is one the most demanding task, especially for analysis of traffic conditions for self-driving cars. Here the results of application of several deep learning architectures (PSPNet and ICNet) for semantic image segmentation of traffic stereo-pair images are presented. The images from Cityscapes dataset and custom urban images were analyzed as to the segmentation accuracy and image inference time. For the models pre-trained on Cityscapes dataset, the inference time was equal in the limits of standard deviation, but the segmentation accuracy was different for various cities and stereo channels even. The distributions of accuracy (mean intersection over union - mIoU) values for each city and channel are asymmetric, long-tailed, and have many extreme outliers, especially for PSPNet network in comparison to ICNet network. Some statistical properties of these distributions (skewness, kurtosis) allow us to distinguish these two networks and open the question about relations between architecture of deep learning networks and statistical distribution of the predicted results (mIoU here). The results obtained demonstrated the different sensitivity of these networks to: (1) the local street view peculiarities in different cities that should be taken into account during the targeted fine tuning the models before their practical applications, (2) the right and left data channels in stereo-pairs. For both networks, the difference in the predicted results (mIoU here) for the right and left data channels in stereo-pairs is out of the limits of statistical error in relation to mIoU values. It means that the traffic stereo pairs can be effectively used not only for depth calculations (as it is usually used), but also as an additional data channel that can provide much more information about scene objects than simple duplication of the same street view images.
Chest X-Ray Analysis of Tuberculosis by Deep Learning with Segmentation and Augmentation
Mar 03, 2018
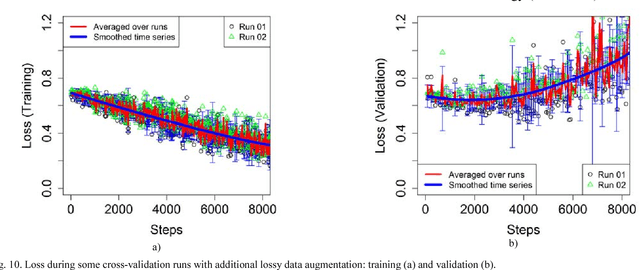
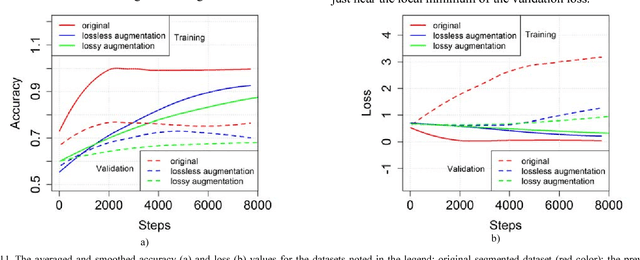
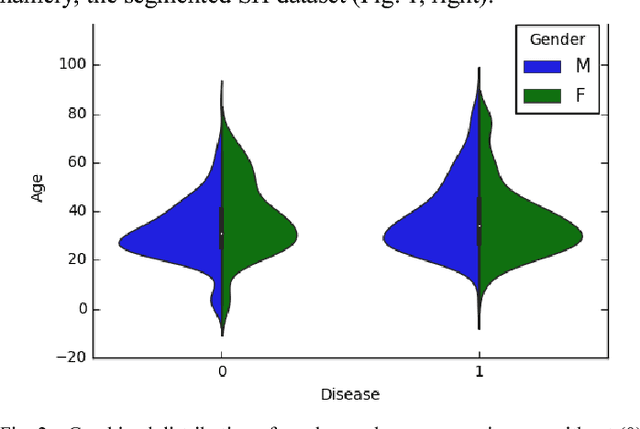
The results of chest X-ray (CXR) analysis of 2D images to get the statistically reliable predictions (availability of tuberculosis) by computer-aided diagnosis (CADx) on the basis of deep learning are presented. They demonstrate the efficiency of lung segmentation, lossless and lossy data augmentation for CADx of tuberculosis by deep convolutional neural network (CNN) applied to the small and not well-balanced dataset even. CNN demonstrates ability to train (despite overfitting) on the pre-processed dataset obtained after lung segmentation in contrast to the original not-segmented dataset. Lossless data augmentation of the segmented dataset leads to the lowest validation loss (without overfitting) and nearly the same accuracy (within the limits of standard deviation) in comparison to the original and other pre-processed datasets after lossy data augmentation. The additional limited lossy data augmentation results in the lower validation loss, but with a decrease of the validation accuracy. In conclusion, besides the more complex deep CNNs and bigger datasets, the better progress of CADx for the small and not well-balanced datasets even could be obtained by better segmentation, data augmentation, dataset stratification, and exclusion of non-evident outliers.
Deep Learning for Fatigue Estimation on the Basis of Multimodal Human-Machine Interactions
Dec 30, 2017
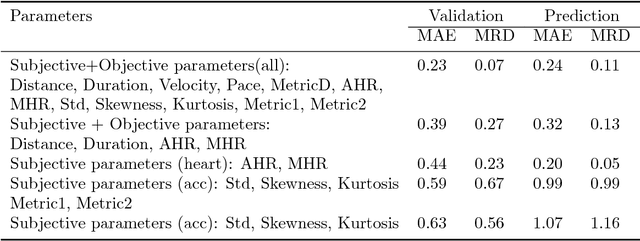
The new method is proposed to monitor the level of current physical load and accumulated fatigue by several objective and subjective characteristics. It was applied to the dataset targeted to estimate the physical load and fatigue by several statistical and machine learning methods. The data from peripheral sensors (accelerometer, GPS, gyroscope, magnetometer) and brain-computing interface (electroencephalography) were collected, integrated, and analyzed by several statistical and machine learning methods (moment analysis, cluster analysis, principal component analysis, etc.). The hypothesis 1 was presented and proved that physical activity can be classified not only by objective parameters, but by subjective parameters also. The hypothesis 2 (experienced physical load and subsequent restoration as fatigue level can be estimated quantitatively and distinctive patterns can be recognized) was presented and some ways to prove it were demonstrated. Several "physical load" and "fatigue" metrics were proposed. The results presented allow to extend application of the machine learning methods for characterization of complex human activity patterns (for example, to estimate their actual physical load and fatigue, and give cautions and advice).