 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Size Influence on Performance of Graphic and Tensor Processing Units during Training and Inference Phases
Dec 31, 2018
The impact of the maximally possible batch size (for the better runtime) on performance of graphic processing units (GPU) and tensor processing units (TPU) during training and inference phases is investigated. The numerous runs of the selected deep neural network (DNN) were performed on the standard MNIST and Fashion-MNIST datasets. The significant speedup was obtained even for extremely low-scale usage of Google TPUv2 units (8 cores only) in comparison to the quite powerful GPU NVIDIA Tesla K80 card with the speedup up to 10x for training stage (without taking into account the overheads) and speedup up to 2x for prediction stage (with and without taking into account overheads). The precise speedup values depend on the utilization level of TPUv2 units and increase with the increase of the data volume under processing, but for the datasets used in this work (MNIST and Fashion-MNIST with images of sizes 28x28) the speedup was observed for batch sizes >512 images for training phase and >40 000 images for prediction phase. It should be noted that these results were obtained without detriment to the prediction accuracy and loss that were equal for both GPU and TPU runs up to the 3rd significant digit for MNIST dataset, and up to the 2nd significant digit for Fashion-MNIST dataset.
Impact of Ground Truth Annotation Quality on Performance of Semantic Image Segmentation of Traffic Conditions
Dec 30, 2018

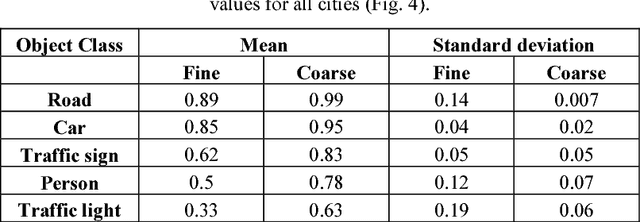
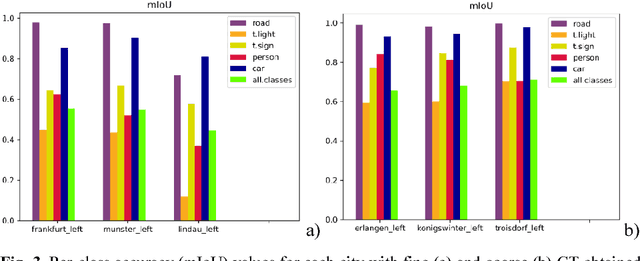
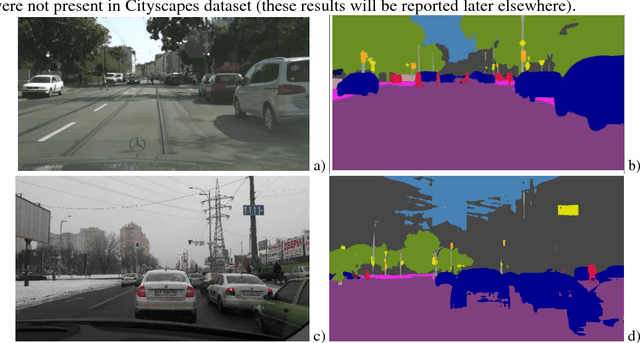
Preparation of high-quality datasets for the urban scene understanding is a labor-intensive task, especially, for datasets designed for the autonomous driving applications. The application of the coarse ground truth (GT) annotations of these datasets without detriment to the accuracy of semantic image segmentation (by the mean intersection over union - mIoU) could simplify and speedup the dataset preparation and model fine tuning before its practical application. Here the results of the comparative analysis for semantic segmentation accuracy obtained by PSPNet deep learning architecture are presented for fine and coarse annotated images from Cityscapes dataset. Two scenarios were investigated: scenario 1 - the fine GT images for training and prediction, and scenario 2 - the fine GT images for training and the coarse GT images for prediction. The obtained results demonstrated that for the most important classes the mean accuracy values of semantic image segmentation for coarse GT annotations are higher than for the fine GT ones, and the standard deviation values are vice versa. It means that for some applications some unimportant classes can be excluded and the model can be tuned further for some classes and specific regions on the coarse GT dataset without loss of the accuracy even. Moreover, this opens the perspectives to use deep neural networks for the preparation of such coarse GT datasets.
Performance Evaluation of Deep Learning Networks for Semantic Segmentation of Traffic Stereo-Pair Images
Jun 05, 2018
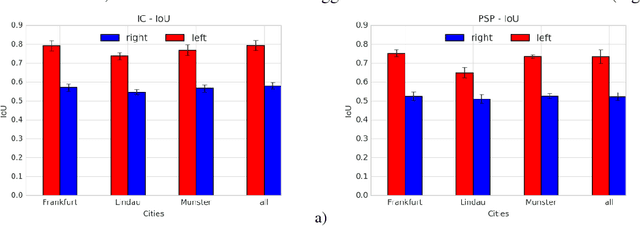
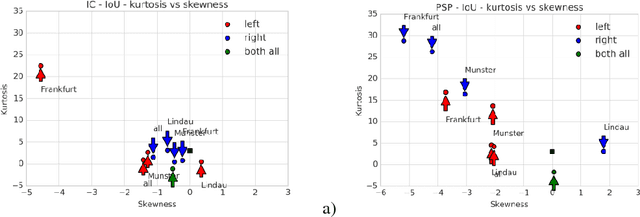
Semantic image segmentation is one the most demanding task, especially for analysis of traffic conditions for self-driving cars. Here the results of application of several deep learning architectures (PSPNet and ICNet) for semantic image segmentation of traffic stereo-pair images are presented. The images from Cityscapes dataset and custom urban images were analyzed as to the segmentation accuracy and image inference time. For the models pre-trained on Cityscapes dataset, the inference time was equal in the limits of standard deviation, but the segmentation accuracy was different for various cities and stereo channels even. The distributions of accuracy (mean intersection over union - mIoU) values for each city and channel are asymmetric, long-tailed, and have many extreme outliers, especially for PSPNet network in comparison to ICNet network. Some statistical properties of these distributions (skewness, kurtosis) allow us to distinguish these two networks and open the question about relations between architecture of deep learning networks and statistical distribution of the predicted results (mIoU here). The results obtained demonstrated the different sensitivity of these networks to: (1) the local street view peculiarities in different cities that should be taken into account during the targeted fine tuning the models before their practical applications, (2) the right and left data channels in stereo-pairs. For both networks, the difference in the predicted results (mIoU here) for the right and left data channels in stereo-pairs is out of the limits of statistical error in relation to mIoU values. It means that the traffic stereo pairs can be effectively used not only for depth calculations (as it is usually used), but also as an additional data channel that can provide much more information about scene objects than simple duplication of the same street view images.