 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Ground Truth Annotation Quality on Performance of Semantic Image Segmentation of Traffic Conditions
Paper and Code


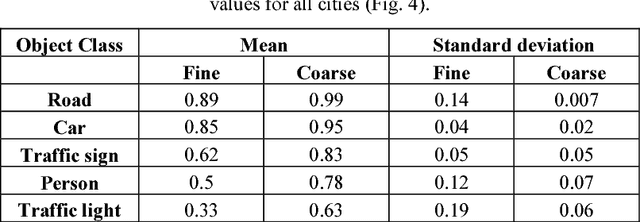
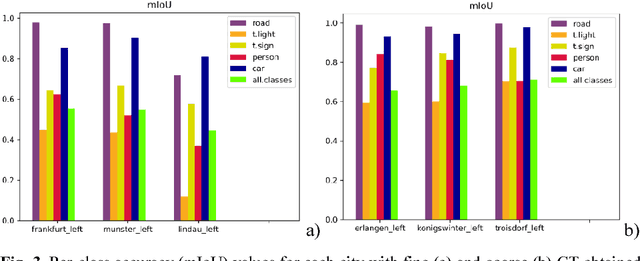
Preparation of high-quality datasets for the urban scene understanding is a labor-intensive task, especially, for datasets designed for the autonomous driving applications. The application of the coarse ground truth (GT) annotations of these datasets without detriment to the accuracy of semantic image segmentation (by the mean intersection over union - mIoU) could simplify and speedup the dataset preparation and model fine tuning before its practical application. Here the results of the comparative analysis for semantic segmentation accuracy obtained by PSPNet deep learning architecture are presented for fine and coarse annotated images from Cityscapes dataset. Two scenarios were investigated: scenario 1 - the fine GT images for training and prediction, and scenario 2 - the fine GT images for training and the coarse GT images for prediction. The obtained results demonstrated that for the most important classes the mean accuracy values of semantic image segmentation for coarse GT annotations are higher than for the fine GT ones, and the standard deviation values are vice versa. It means that for some applications some unimportant classes can be excluded and the model can be tuned further for some classes and specific regions on the coarse GT dataset without loss of the accuracy even. Moreover, this opens the perspectives to use deep neural networks for the preparation of such coarse GT datasets.