 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Intent as a Protocol-Like Communication Layer: Cross-Model Robustness, Framework Comparison, and the Weak-Model Compensation Effect
Mar 31, 2026How reliably can structured intent representations preserve user goals across different AI models, languages, and prompting frameworks? Prior work showed that PPS (Prompt Protocol Specification), a 5W3H-based structured intent framework, improves goal alignment in Chinese and generalizes to English and Japanese. This paper extends that line of inquiry in three directions: cross-model robustness across Claude, GPT-4o, and Gemini 2.5 Pro; controlled comparison with CO-STAR and RISEN; and a user study (N=50) of AI-assisted intent expansion in ecologically valid settings. Across 3,240 model outputs (3 languages x 6 conditions x 3 models x 3 domains x 20 tasks), evaluated by an independent judge (DeepSeek-V3), we find that structured prompting substantially reduces cross-language score variance relative to unstructured baselines. The strongest structured conditions reduce cross-language sigma from 0.470 to about 0.020. We also observe a weak-model compensation pattern: the lowest-baseline model (Gemini) shows a much larger D-A gain (+1.006) than the strongest model (Claude, +0.217). Under the current evaluation resolution, 5W3H, CO-STAR, and RISEN achieve similarly high goal-alignment scores, suggesting that dimensional decomposition itself is an important active ingredient. In the user study, AI-expanded 5W3H prompts reduce interaction rounds by 60 percent and increase user satisfaction from 3.16 to 4.04. These findings support the practical value of structured intent representation as a robust, protocol-like communication layer for human-AI interaction.
Does Structured Intent Representation Generalize? A Cross-Language, Cross-Model Empirical Study of 5W3H Prompting
Mar 26, 2026Does structured intent representation generalize across languages and models? We study PPS (Prompt Protocol Specification), a 5W3H-based framework for structured intent representation in human-AI interaction, and extend prior Chinese-only evidence along three dimensions: two additional languages (English and Japanese), a fourth condition in which a user's simple prompt is automatically expanded into a full 5W3H specification by an AI-assisted authoring interface, and a new research question on cross-model output consistency. Across 2,160 model outputs (3 languages x 4 conditions x 3 LLMs x 60 tasks), we find that AI-expanded 5W3H prompts (Condition D) show no statistically significant difference in goal alignment from manually crafted 5W3H prompts (Condition C) across all three languages, while requiring only a single-sentence input from the user. Structured PPS conditions often reduce or reshape cross-model output variance, though this effect is not uniform across languages and metrics; the strongest evidence comes from identifying spurious low variance in unconstrained baselines. We also show that unstructured prompts exhibit a systematic dual-inflation bias: artificially high composite scores and artificially low apparent cross-model variance. These findings suggest that structured 5W3H representations can improve intent alignment and accessibility across languages and models, especially when AI-assisted authoring lowers the barrier for non-expert users.
Evaluating 5W3H Structured Prompting for Intent Alignment in Human-AI Interaction
Mar 19, 2026Natural language prompts often suffer from intent transmission loss: the gap between what users actually need and what they communicate to AI systems. We evaluate PPS (Prompt Protocol Specification), a 5W3H-based framework for structured intent representation in human-AI interaction. In a controlled three-condition study across 60 tasks in three domains (business, technical, and travel), three large language models (DeepSeek-V3, Qwen-Max, and Kimi), and three prompt conditions - (A) simple prompts, (B) raw PPS JSON, and (C) natural-language-rendered PPS - we collect 540 AI-generated outputs evaluated by an LLM judge. We introduce goal_alignment, a user-intent-centered evaluation dimension, and find that rendered PPS outperforms both simple prompts and raw JSON on this metric. PPS gains are task-dependent: gains are large in high-ambiguity business analysis tasks but reverse in low-ambiguity travel planning. We also identify a measurement asymmetry in standard LLM evaluation, where unconstrained prompts can inflate constraint adherence scores and mask the practical value of structured prompting. A preliminary retrospective survey (N = 20) further suggests a 66.1% reduction in follow-up prompts required, from 3.33 to 1.13 rounds. These findings suggest that structured intent representations can improve alignment and usability in human-AI interaction, especially in tasks where user intent is inherently ambiguous.
A Pushing-Grasping Collaborative Method Based on Deep Q-Network Algorithm in Dual Perspectives
Jan 04, 2021
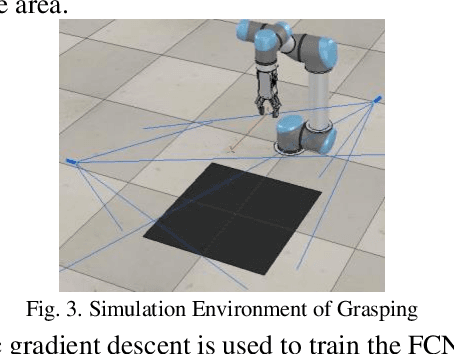
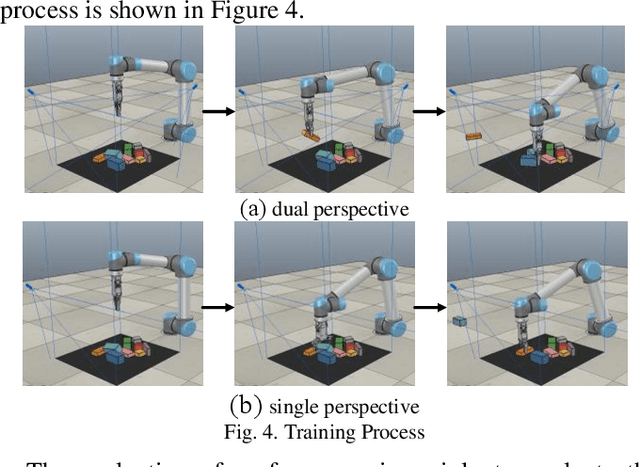
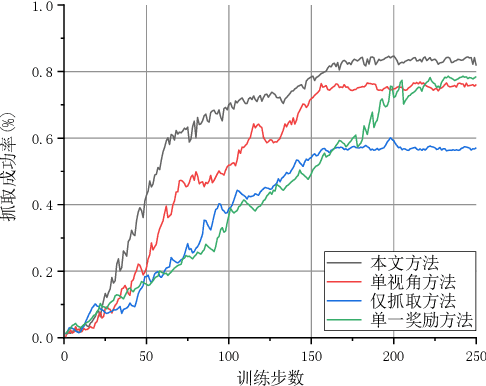
Aiming at the traditional grasping method for manipulators based on 2D camera, when faced with the scene of gathering or covering, it can hardly perform well in unstructured scenes that appear as gathering and covering, for the reason that can't recognize objects accurately in cluster scenes from a single perspective and the manipulators can't make the environment better for grasping. In this case, a novel method of pushing-grasping collaborative based on the deep Q-network in dual perspectives is proposed in this paper. This method adopts an improved deep Q network algorithm, with an RGB-D camera to obtain the information of objects' RGB images and point clouds from two perspectives, and combines the pushing and grasping actions so that the trained manipulator can make the scenes better for grasping so that it can perform well in more complicated grasping scenes. What's more, we improved the reward function of the deep Q-network and propose the piecewise reward function to speed up the convergence of the deep Q-network. We trained different models and tried different methods in the V-REP simulation environment, and it concluded that the method proposed in this paper converges quickly and the success rate of grasping objects in unstructured scenes raises up to 83.5%. Besides, it shows the generalization ability and well performance when novel objects appear in the scenes that the manipulator has never grasped before.
A Visual Kinematics Calibration Method for Manipulator Based on Nonlinear Optimization
May 18, 2020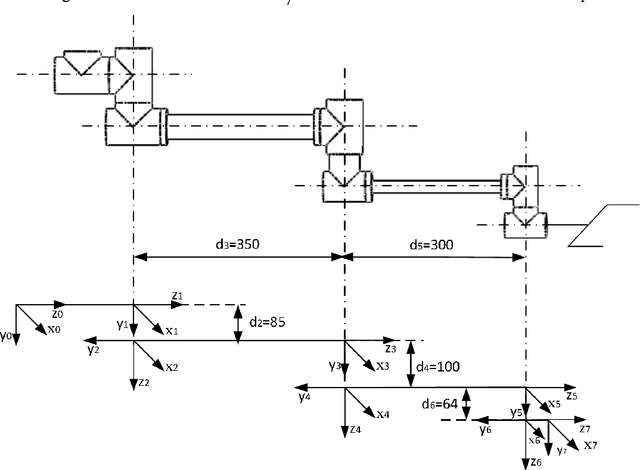
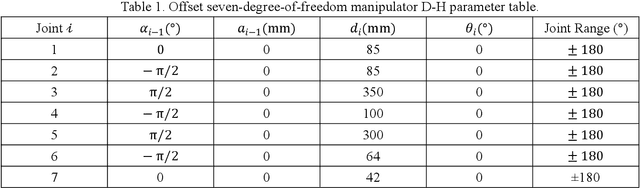
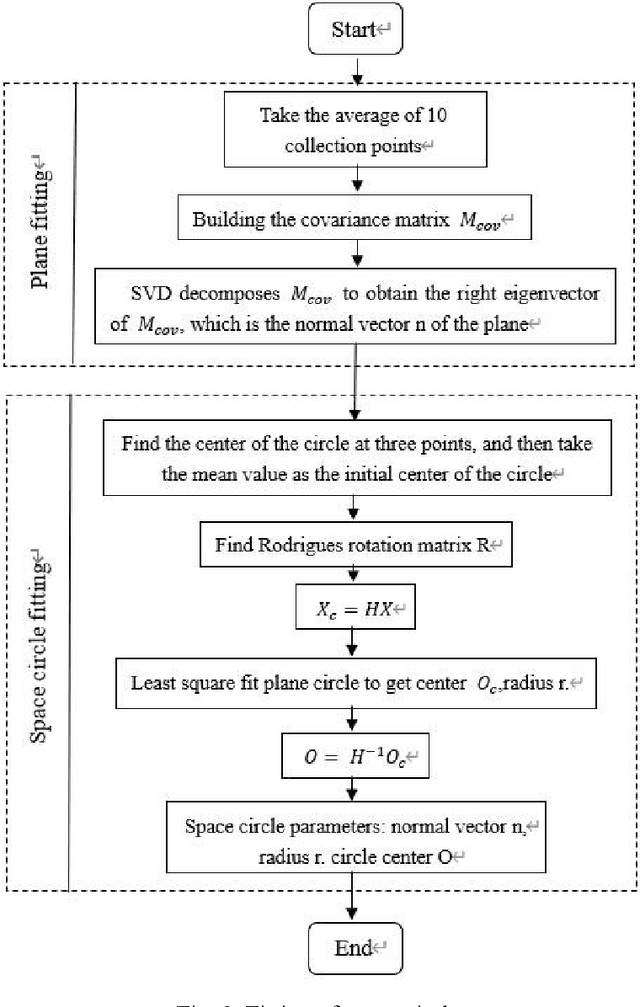

The traditional kinematic calibration method for manipulators requires precise three-dimensional measuring instruments to measure the end pose, which is not only expensive due to the high cost of the measuring instruments but also not applicable to all manipulators. Another calibration method uses a camera, but the system error caused by the camera's parameters affects the calibration accuracy of the kinematics of the robot arm. Therefore, this paper proposes a method for calibrating the geometric parameters of a kinematic model of a manipulator based on monocular vision. Firstly, the classic Denavit-Hartenberg(D-H) modeling method is used to establish the kinematic parameters of the manipulator. Secondly, nonlinear optimization and parameter compensation are performed. The three-dimensional positions of the feature points of the calibration plate under each manipulator attitude corresponding to the actual kinematic model and the classic D-H kinematic model are mapped into the pixel coordinate system, and the sum of Euclidean distance errors of the pixel coordinates of the two is used as the objective function to be optimized. The experimental results show that the pixel deviation of the end pose corresponding to the optimized D-H kinematic model proposed in this paper and the end pose corresponding to the actual kinematic model in the pixel coordinate system is 0.99 pixels. Compared with the 7.9 deviation pixels between the pixel coordinates calculated by the classic D-H kinematic model and the actual pixel coordinates, the deviation is reduced by nearly 7 pixels for an 87% reduction in error. Therefore, the proposed method can effectively avoid system errors caused by camera parameters in visual calibration, can improve the absolute positioning accuracy of the end of the robotic arm, and has good economy and universality.
Monocular visual-inertial SLAM algorithm combined with wheel speed anomaly detection
Mar 22, 2020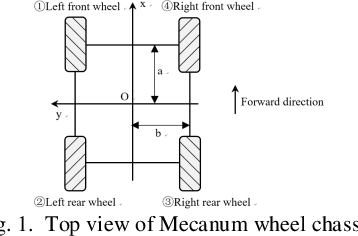
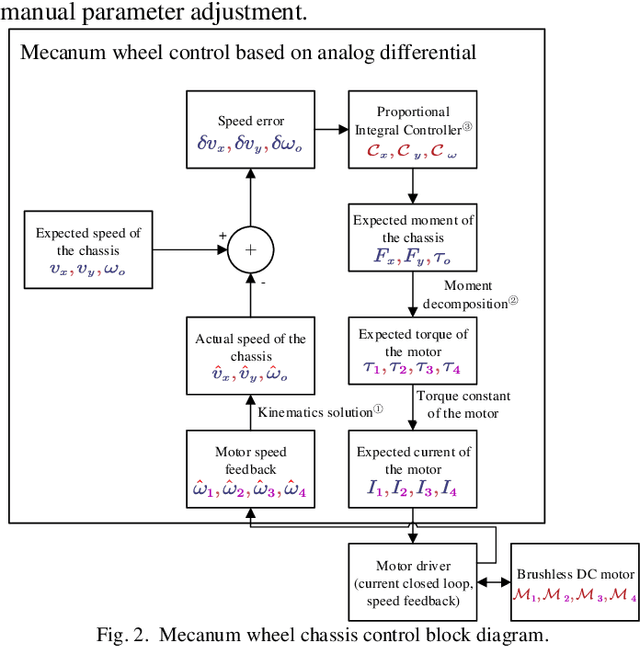
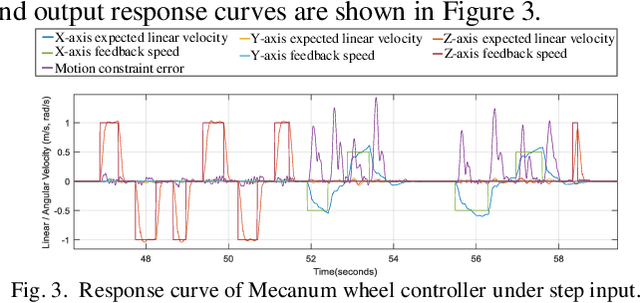
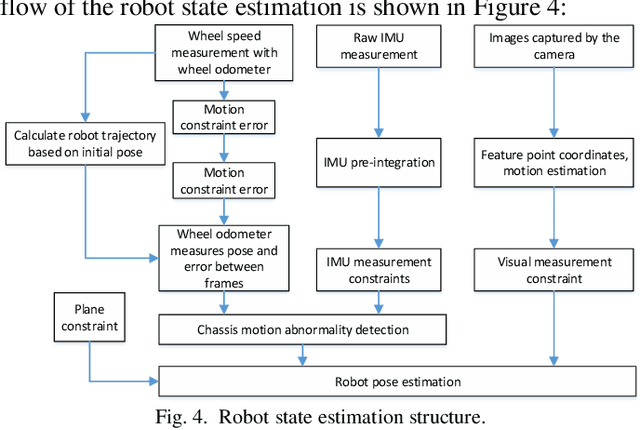
To address the weak observability of monocular visual-inertial odometers on ground-based mobile robots, this paper proposes a monocular inertial SLAM algorithm combined with wheel speed anomaly detection. The algorithm uses a wheel speed odometer pre-integration method to add the wheel speed measurement to the least-squares problem in a tightly coupled manner. For abnormal motion situations, such as skidding and abduction, this paper adopts the Mecanum mobile chassis control method, based on torque control. This method uses the motion constraint error to estimate the reliability of the wheel speed measurement. At the same time, in order to prevent incorrect chassis speed measurements from negatively influencing robot pose estimation, this paper uses three methods to detect abnormal chassis movement and analyze chassis movement status in real time. When the chassis movement is determined to be abnormal, the wheel odometer pre-integration measurement of the current frame is removed from the state estimation equation, thereby ensuring the accuracy and robustness of the state estimation. Experimental results show that the accuracy and robustness of the method in this paper are better than those of a monocular visual-inertial odometer.
Robust tightly coupled pose estimation based on monocular vision, inertia, and wheel speed
Mar 05, 2020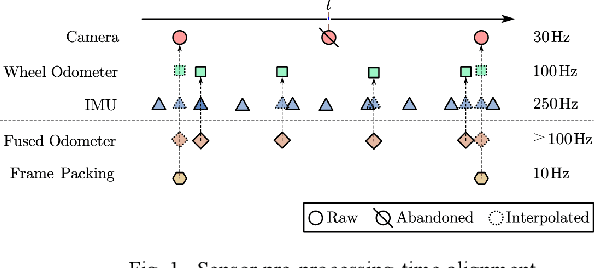
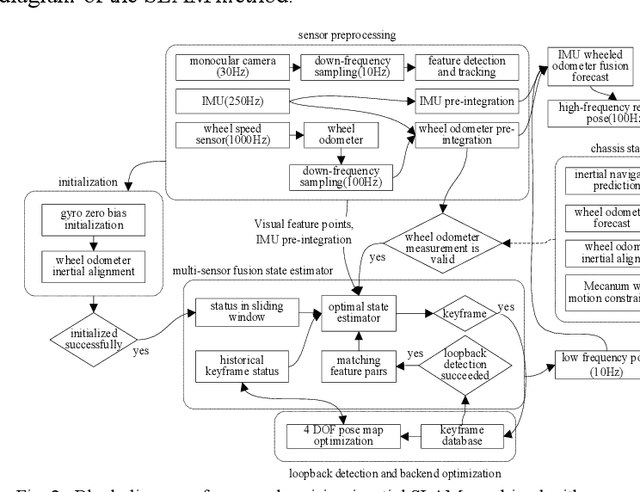
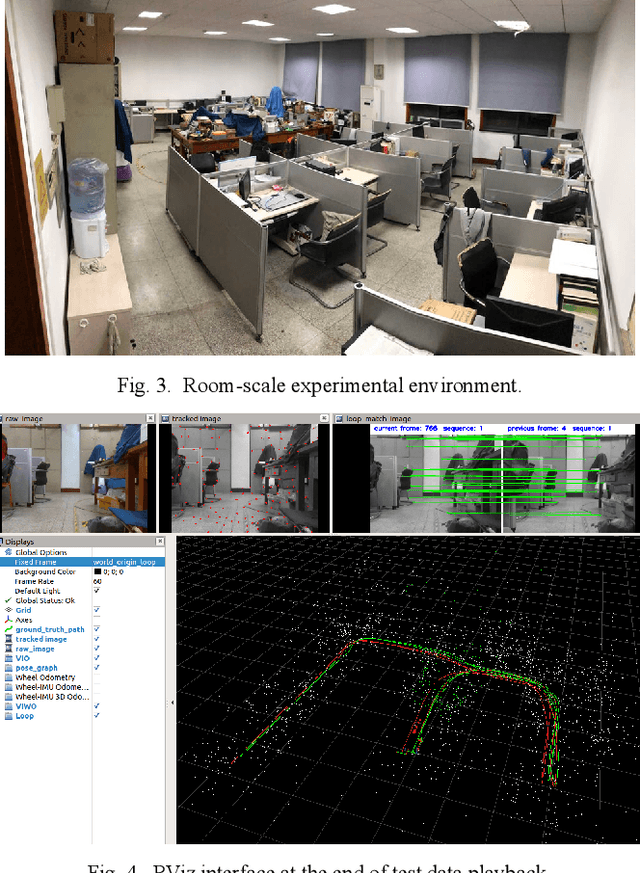
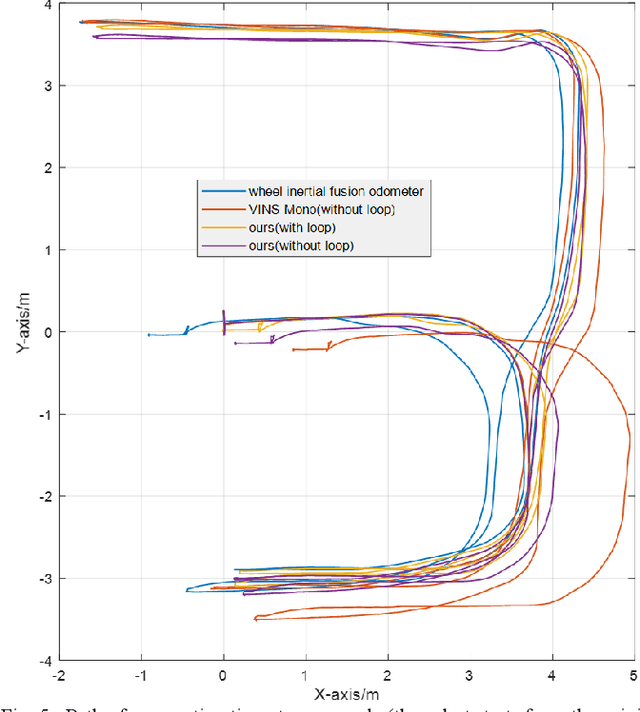
The visual SLAM method is widely used for self-localization and mapping in complex environments. Visual-inertia SLAM, which combines a camera with IMU, can significantly improve the robustness and enable scale weak-visibility, whereas monocular visual SLAM is scale-invisible. For ground mobile robots, the introduction of a wheel speed sensor can solve the scale weak-visible problem and improve the robustness under abnormal conditions. In this thesis, a multi-sensor fusion SLAM algorithm using monocular vision, inertia, and wheel speed measurements is proposed. The sensor measurements are combined in a tightly coupled manner, and a nonlinear optimization method is used to maximize the posterior probability to solve the optimal state estimation. Loop detection and back-end optimization are added to help reduce or even eliminate the cumulative error of the estimated poses, thus ensuring global consistency of the trajectory and map. The wheel odometer pre-integration algorithm, which combines the chassis speed and IMU angular speed, can avoid repeated integration caused by linearization point changes during iterative optimization; state initialization based on the wheel odometer and IMU enables a quick and reliable calculation of the initial state values required by the state estimator in both stationary and moving states. Comparative experiments were carried out in room-scale scenes, building scale scenes, and visual loss scenarios. The results showed that the proposed algorithm has high accuracy, 2.2 m of cumulative error after moving 812 m (0.28%, loopback optimization disabled), strong robustness, and effective localization capability even in the event of sensor loss such as visual loss. The accuracy and robustness of the proposed method are superior to those of monocular visual inertia SLAM and traditional wheel odometers.
Prediction of Physical Load Level by Machine Learning Analysis of Heart Activity after Exercises
Dec 20, 2019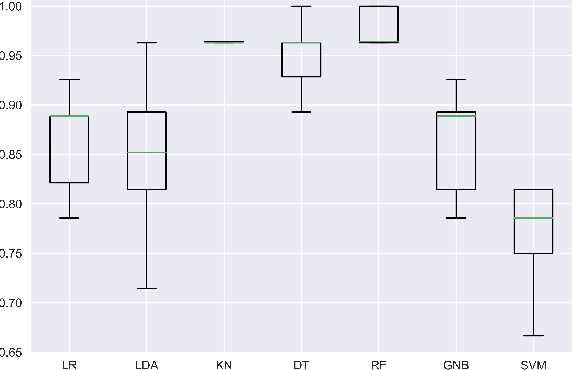
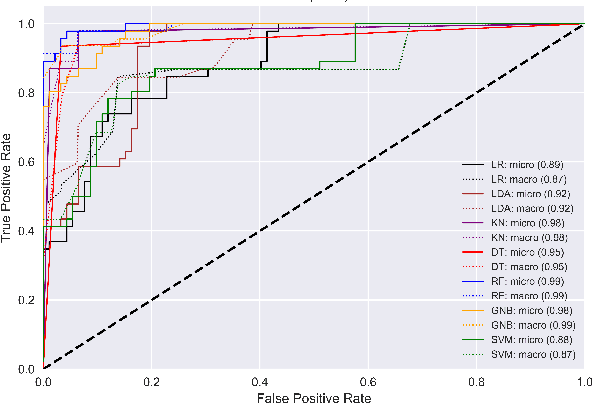
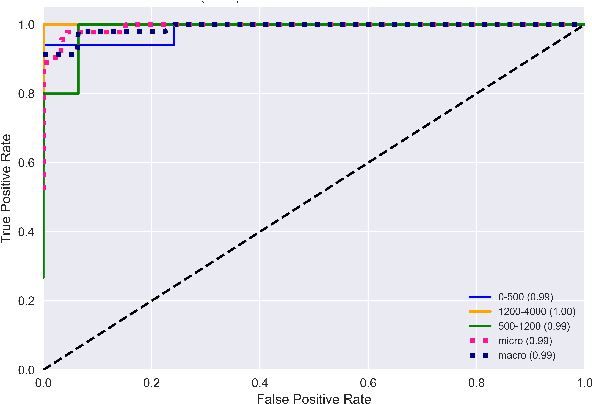
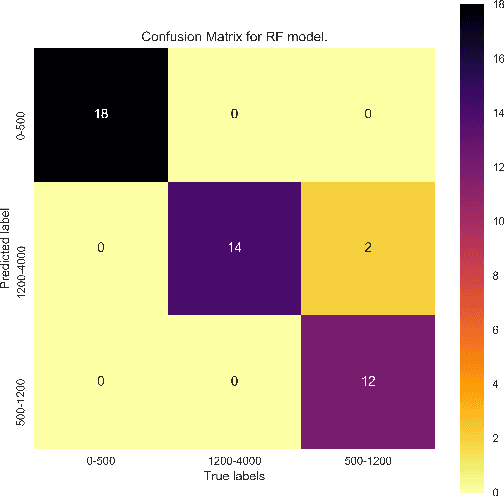
The assessment of energy expenditure in real life is of great importance for monitoring the current physical state of people, especially in work, sport, elderly care, health care, and everyday life even. This work reports about application of some machine learning methods (linear regression, linear discriminant analysis, k-nearest neighbors, decision tree, random forest, Gaussian naive Bayes, support-vector machine) for monitoring energy expenditures in athletes. The classification problem was to predict the known level of the in-exercise loads (in three categories by calories) by the heart rate activity features measured during the short period of time (1 minute only) after training, i.e by features of the post-exercise load. The results obtained shown that the post-exercise heart activity features preserve the information of the in-exercise training loads and allow us to predict their actual in-exercise levels. The best performance can be obtained by the random forest classifier with all 8 heart rate features (micro-averaged area under curve value AUCmicro = 0.87 and macro-averaged one AUCmacro = 0.88) and the k-nearest neighbors classifier with 4 most important heart rate features (AUCmicro = 0.91 and AUCmacro = 0.89). The limitations and perspectives of the ML methods used are outlined, and some practical advices are proposed as to their improvement and implementation for the better prediction of in-exercise energy expenditures.
Open Source Dataset and Machine Learning Techniques for Automatic Recognition of Historical Graffiti
Aug 31, 2018

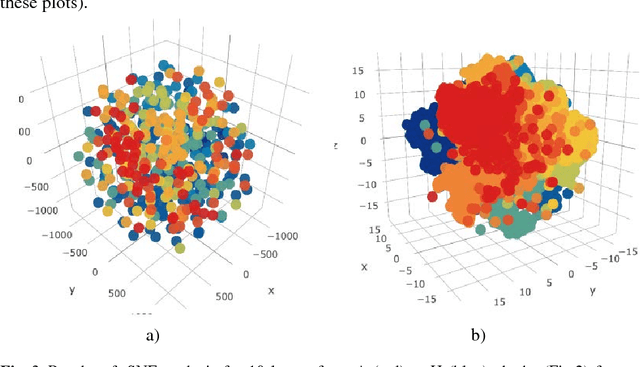
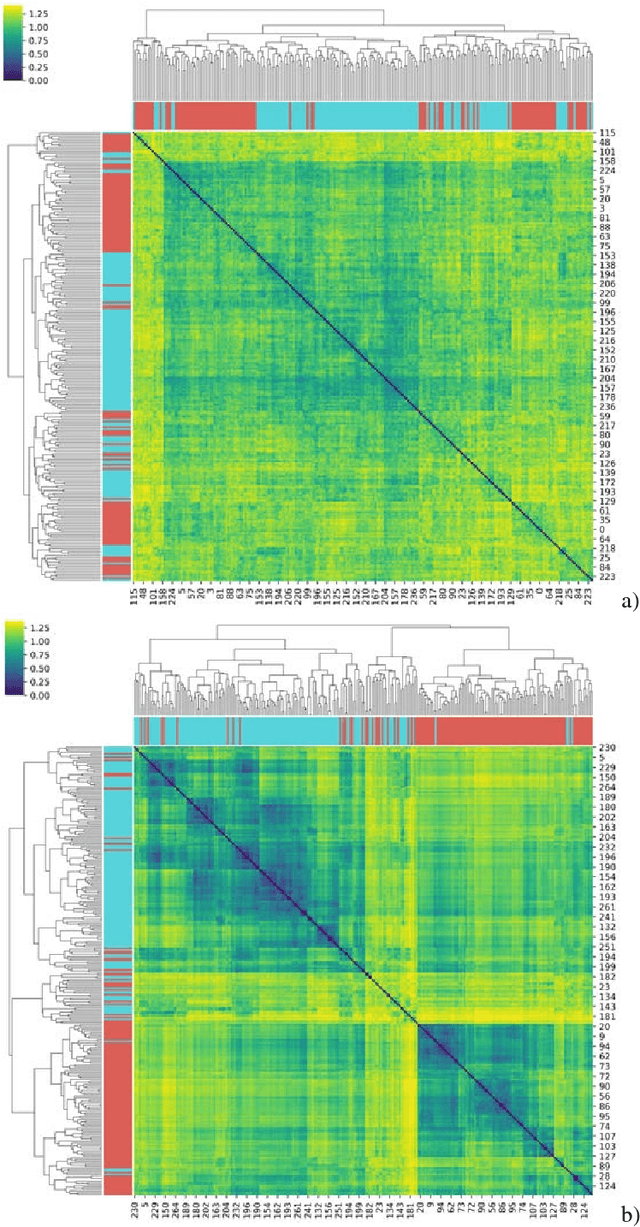
Machine learning techniques are presented for automatic recognition of the historical letters (XI-XVIII centuries) carved on the stoned walls of St.Sophia cathedral in Kyiv (Ukraine). A new image dataset of these carved Glagolitic and Cyrillic letters (CGCL) was assembled and pre-processed for recognition and prediction by machine learning methods. The dataset consists of more than 4000 images for 34 types of letters. The explanatory data analysis of CGCL and notMNIST datasets shown that the carved letters can hardly be differentiated by dimensionality reduction methods, for example, by t-distributed stochastic neighbor embedding (tSNE) due to the worse letter representation by stone carving in comparison to hand writing. The multinomial logistic regression (MLR) and a 2D convolutional neural network (CNN) models were applied. The MLR model demonstrated the area under curve (AUC) values for receiver operating characteristic (ROC) are not lower than 0.92 and 0.60 for notMNIST and CGCL, respectively. The CNN model gave AUC values close to 0.99 for both notMNIST and CGCL (despite the much smaller size and quality of CGCL in comparison to notMNIST) under condition of the high lossy data augmentation. CGCL dataset was published to be available for the data science community as an open source resource.
Chest X-Ray Analysis of Tuberculosis by Deep Learning with Segmentation and Augmentation
Mar 03, 2018
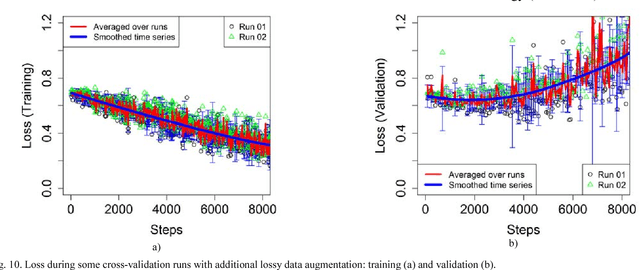
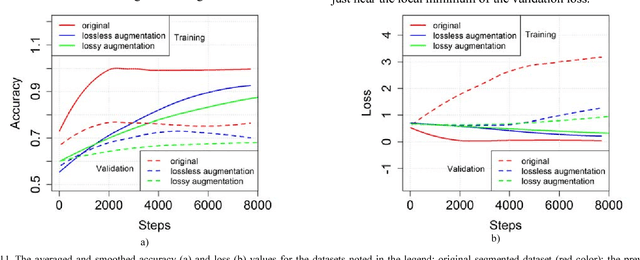
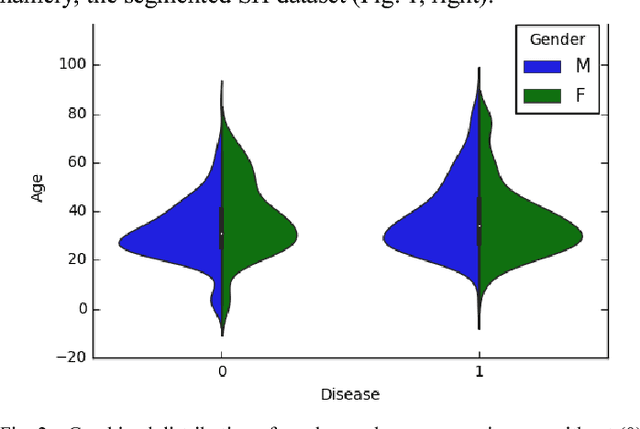
The results of chest X-ray (CXR) analysis of 2D images to get the statistically reliable predictions (availability of tuberculosis) by computer-aided diagnosis (CADx) on the basis of deep learning are presented. They demonstrate the efficiency of lung segmentation, lossless and lossy data augmentation for CADx of tuberculosis by deep convolutional neural network (CNN) applied to the small and not well-balanced dataset even. CNN demonstrates ability to train (despite overfitting) on the pre-processed dataset obtained after lung segmentation in contrast to the original not-segmented dataset. Lossless data augmentation of the segmented dataset leads to the lowest validation loss (without overfitting) and nearly the same accuracy (within the limits of standard deviation) in comparison to the original and other pre-processed datasets after lossy data augmentation. The additional limited lossy data augmentation results in the lower validation loss, but with a decrease of the validation accuracy. In conclusion, besides the more complex deep CNNs and bigger datasets, the better progress of CADx for the small and not well-balanced datasets even could be obtained by better segmentation, data augmentation, dataset stratification, and exclusion of non-evident outliers.