 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pushing-Grasping Collaborative Method Based on Deep Q-Network Algorithm in Dual Perspectives
Paper and Code
Jan 04, 2021
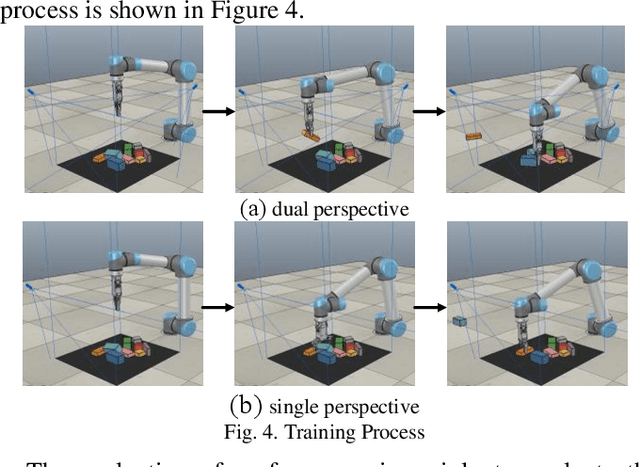
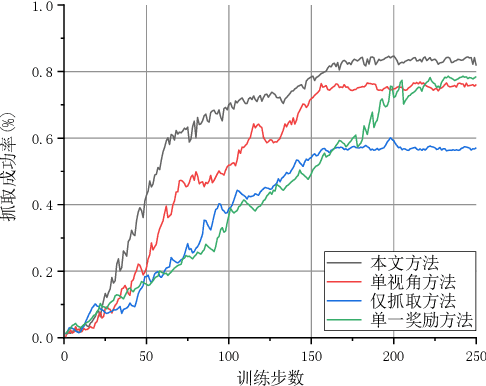
Aiming at the traditional grasping method for manipulators based on 2D camera, when faced with the scene of gathering or covering, it can hardly perform well in unstructured scenes that appear as gathering and covering, for the reason that can't recognize objects accurately in cluster scenes from a single perspective and the manipulators can't make the environment better for grasping. In this case, a novel method of pushing-grasping collaborative based on the deep Q-network in dual perspectives is proposed in this paper. This method adopts an improved deep Q network algorithm, with an RGB-D camera to obtain the information of objects' RGB images and point clouds from two perspectives, and combines the pushing and grasping actions so that the trained manipulator can make the scenes better for grasping so that it can perform well in more complicated grasping scenes. What's more, we improved the reward function of the deep Q-network and propose the piecewise reward function to speed up the convergence of the deep Q-network. We trained different models and tried different methods in the V-REP simulation environment, and it concluded that the method proposed in this paper converges quickly and the success rate of grasping objects in unstructured scenes raises up to 83.5%. Besides, it shows the generalization ability and well performance when novel objects appear in the scenes that the manipulator has never grasped before.