 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Generative Game Engine: Breaking the Resolution Wall via Hardware-Algorithm Co-Design
Jan 31, 2026Real-time generative game engines represent a paradigm shift in interactive simulation, promising to replace traditional graphics pipelines with neural world models. However, existing approaches are fundamentally constrained by the ``Memory Wall,'' restricting practical deployments to low resolutions (e.g., $64 \times 64$). This paper bridges the gap between generative models and high-resolution neural simulations by introducing a scalable \textit{Hardware-Algorithm Co-Design} framework. We identify that high-resolution generation suffers from a critical resource mismatch: the World Model is compute-bound while the Decoder is memory-bound. To address this, we propose a heterogeneous architecture that intelligently decouples these components across a cluster of AI accelerators. Our system features three core innovations: (1) an asymmetric resource allocation strategy that optimizes throughput under sequence parallelism constraints; (2) a memory-centric operator fusion scheme that minimizes off-chip bandwidth usage; and (3) a manifold-aware latent extrapolation mechanism that exploits temporal redundancy to mask latency. We validate our approach on a cluster of programmable AI accelerators, enabling real-time generation at $720 \times 480$ resolution -- a $50\times$ increase in pixel throughput over prior baselines. Evaluated on both continuous 3D racing and discrete 2D platformer benchmarks, our system delivers fluid 26.4 FPS and 48.3 FPS respectively, with an amortized effective latency of 2.7 ms. This work demonstrates that resolving the ``Memory Wall'' via architectural co-design is not merely an optimization, but a prerequisite for enabling high-fidelity, responsive neural gameplay.
ColorConceptBench: A Benchmark for Probabilistic Color-Concept Understanding in Text-to-Image Models
Jan 23, 2026While text-to-image (T2I) models have advanced considerably, their capability to associate colors with implicit concepts remains underexplored. To address the gap, we introduce ColorConceptBench, a new human-annotated benchmark to systematically evaluate color-concept associations through the lens of probabilistic color distributions. ColorConceptBench moves beyond explicit color names or codes by probing how models translate 1,281 implicit color concepts using a foundation of 6,369 human annotations. Our evaluation of seven leading T2I models reveals that current models lack sensitivity to abstract semantics, and crucially, this limitation appears resistant to standard interventions (e.g., scaling and guidance). This demonstrates that achieving human-like color semantics requires more than larger models, but demands a fundamental shift in how models learn and represent implicit meaning.
When Eyes and Ears Disagree: Can MLLMs Discern Audio-Visual Confusion?
Nov 13, 2025Can Multimodal Large Language Models (MLLMs) discern confused objects that are visually present but audio-absent? To study this, we introduce a new benchmark, AV-ConfuseBench, which simulates an ``Audio-Visual Confusion'' scene by modifying the corresponding sound of an object in the video, e.g., mute the sounding object and ask MLLMs Is there a/an muted-object sound''. Experimental results reveal that MLLMs, such as Qwen2.5-Omni and Gemini 2.5, struggle to discriminate non-existent audio due to visually dominated reasoning. Motivated by this observation, we introduce RL-CoMM, a Reinforcement Learning-based Collaborative Multi-MLLM that is built upon the Qwen2.5-Omni foundation. RL-CoMM includes two stages: 1) To alleviate visually dominated ambiguities, we introduce an external model, a Large Audio Language Model (LALM), as the reference model to generate audio-only reasoning. Then, we design a Step-wise Reasoning Reward function that enables MLLMs to self-improve audio-visual reasoning with the audio-only reference. 2) To ensure an accurate answer prediction, we introduce Answer-centered Confidence Optimization to reduce the uncertainty of potential heterogeneous reasoning differences. Extensive experiments on audio-visual question answering and audio-visual hallucination show that RL-CoMM improves the accuracy by 10~30\% over the baseline model with limited training data. Follow: https://github.com/rikeilong/AVConfusion.
NN-Former: Rethinking Graph Structure in Neural Architecture Representation
Jul 01, 2025
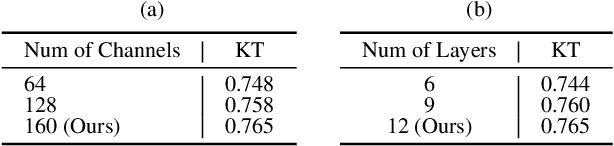
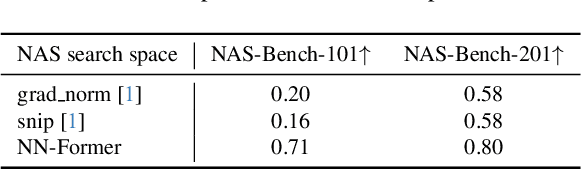
The growing use of deep learning necessitates efficient network design and deployment, making neural predictors vital for estimating attributes such as accuracy and latency. Recently, Graph Neural Networks (GNNs) and transformers have shown promising performance in representing neural architectures. However, each of both methods has its disadvantages. GNNs lack the capabilities to represent complicated features, while transformers face poor generalization when the depth of architecture grows. To mitigate the above issues, we rethink neural architecture topology and show that sibling nodes are pivotal while overlooked in previous research. We thus propose a novel predictor leveraging the strengths of GNNs and transformers to learn the enhanced topology. We introduce a novel token mixer that considers siblings, and a new channel mixer named bidirectional graph isomorphism feed-forward network. Our approach consistently achieves promising performance in both accuracy and latency prediction, providing valuable insights for learning Directed Acyclic Graph (DAG) topology. The code is available at https://github.com/XuRuihan/NNFormer.
Application-Driven Value Alignment in Agentic AI Systems: Survey and Perspectives
Jun 11, 2025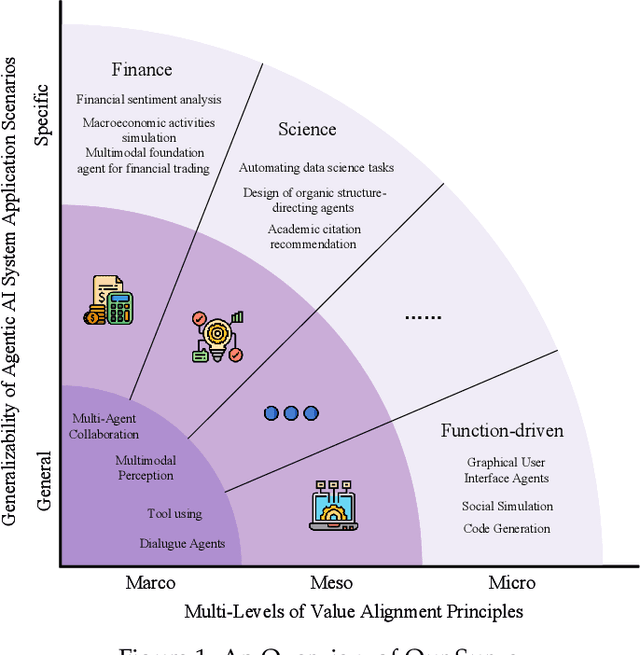
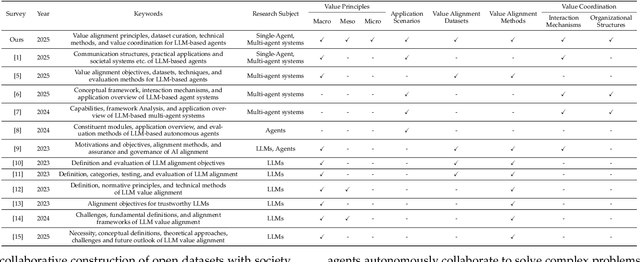
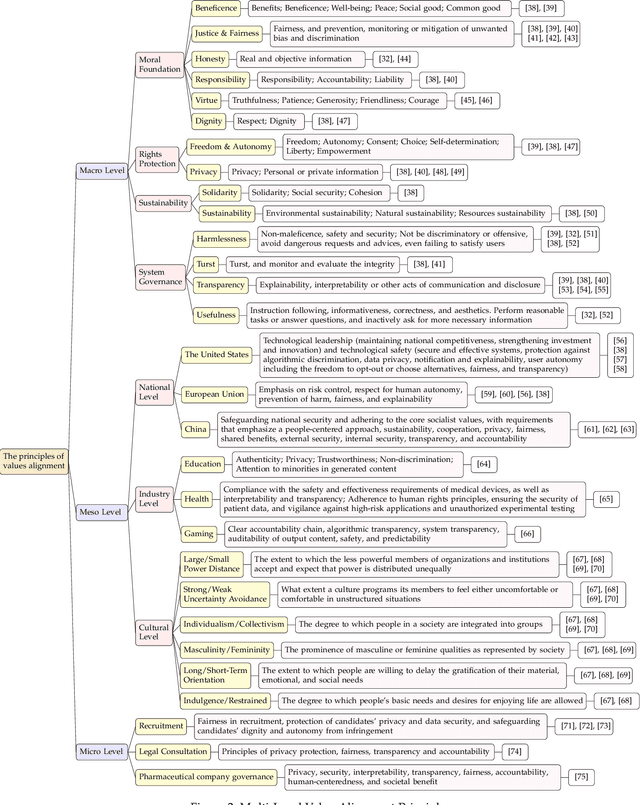
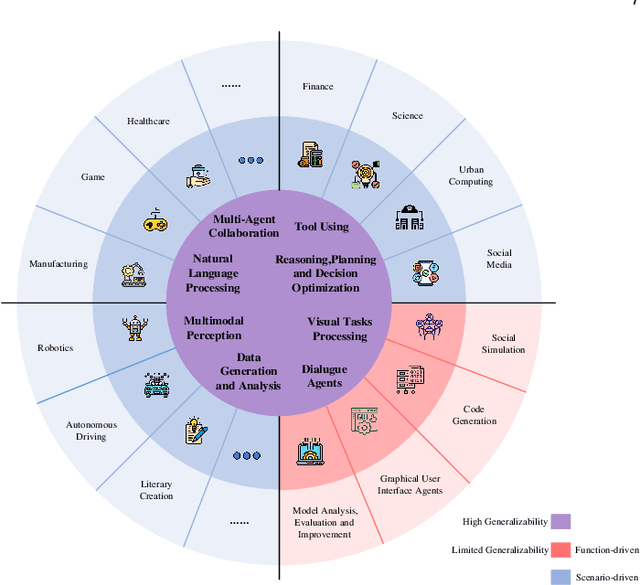
The ongoing evolution of AI paradigms has propelled AI research into the Agentic AI stage. Consequently, the focus of research has shifted from single agents and simple applications towards multi-agent autonomous decision-making and task collaboration in complex environments. As Large Language Models (LLMs) advance, their applications become more diverse and complex, leading to increasingly situational and systemic risks. This has brought significant attention to value alignment for AI agents, which aims to ensure that an agent's goals, preferences, and behaviors align with human values and societal norms. This paper reviews value alignment in agent systems within specific application scenarios. It integrates the advancements in AI driven by large models with the demands of social governance. Our review covers value principles, agent system application scenarios, and agent value alignment evaluation. Specifically, value principles are organized hierarchically from a top-down perspective, encompassing macro, meso, and micro levels. Agent system application scenarios are categorized and reviewed from a general-to-specific viewpoint. Agent value alignment evaluation systematically examines datasets for value alignment assessment and relevant value alignment methods. Additionally, we delve into value coordination among multiple agents within agent systems. Finally, we propose several potential research directions in this field.
AKRMap: Adaptive Kernel Regression for Trustworthy Visualization of Cross-Modal Embeddings
May 20, 2025Cross-modal embeddings form the foundation for multi-modal models. However, visualization methods for interpreting cross-modal embeddings have been primarily confined to traditional dimensionality reduction (DR) techniques like PCA and t-SNE. These DR methods primarily focus on feature distributions within a single modality, whilst failing to incorporate metrics (e.g., CLIPScore) across multiple modalities.This paper introduces AKRMap, a new DR technique designed to visualize cross-modal embeddings metric with enhanced accuracy by learning kernel regression of the metric landscape in the projection space. Specifically, AKRMap constructs a supervised projection network guided by a post-projection kernel regression loss, and employs adaptive generalized kernels that can be jointly optimized with the projection. This approach enables AKRMap to efficiently generate visualizations that capture complex metric distributions, while also supporting interactive features such as zoom and overlay for deeper exploration. Quantitative experiments demonstrate that AKRMap outperforms existing DR methods in generating more accurate and trustworthy visualizations. We further showcase the effectiveness of AKRMap in visualizing and comparing cross-modal embeddings for text-to-image models. Code and demo are available at https://github.com/yilinye/AKRMap.
Facilitating Video Story Interaction with Multi-Agent Collaborative System
May 02, 2025Video story interaction enables viewers to engage with and explore narrative content for personalized experiences. However, existing methods are limited to user selection, specially designed narratives, and lack customization. To address this, we propose an interactive system based on user intent. Our system uses a Vision Language Model (VLM) to enable machines to understand video stories, combining Retrieval-Augmented Generation (RAG) and a Multi-Agent System (MAS) to create evolving characters and scene experiences. It includes three stages: 1) Video story processing, utilizing VLM and prior knowledge to simulate human understanding of stories across three modalities. 2) Multi-space chat, creating growth-oriented characters through MAS interactions based on user queries and story stages. 3) Scene customization, expanding and visualizing various story scenes mentioned in dialogue. Applied to the Harry Potter series, our study shows the system effectively portrays emergent character social behavior and growth, enhancing the interactive experience in the video story world.
Multi-modal Reference Learning for Fine-grained Text-to-Image Retrieval
Apr 10, 2025Fine-grained text-to-image retrieval aims to retrieve a fine-grained target image with a given text query. Existing methods typically assume that each training image is accurately depicted by its textual descriptions. However, textual descriptions can be ambiguous and fail to depict discriminative visual details in images, leading to inaccurate representation learning. To alleviate the effects of text ambiguity, we propose a Multi-Modal Reference learning framework to learn robust representations. We first propose a multi-modal reference construction module to aggregate all visual and textual details of the same object into a comprehensive multi-modal reference. The multi-modal reference hence facilitates the subsequent representation learning and retrieval similarity computation. Specifically, a reference-guided representation learning module is proposed to use multi-modal references to learn more accurate visual and textual representations. Additionally, we introduce a reference-based refinement method that employs the object references to compute a reference-based similarity that refines the initial retrieval results. Extensive experiments are conducted on five fine-grained text-to-image retrieval datasets for different text-to-image retrieval tasks. The proposed method has achieved superior performance over state-of-the-art methods. For instance, on the text-to-person image retrieval dataset RSTPReid, our method achieves the Rank1 accuracy of 56.2\%, surpassing the recent CFine by 5.6\%.
GMapLatent: Geometric Mapping in Latent Space
Mar 30, 2025Cross-domain generative models based on encoder-decoder AI architectures have attracted much attention in generating realistic images, where domain alignment is crucial for generation accuracy. Domain alignment methods usually deal directly with the initial distribution; however, mismatched or mixed clusters can lead to mode collapse and mixture problems in the decoder, compromising model generalization capabilities. In this work, we innovate a cross-domain alignment and generation model that introduces a canonical latent space representation based on geometric mapping to align the cross-domain latent spaces in a rigorous and precise manner, thus avoiding mode collapse and mixture in the encoder-decoder generation architectures. We name this model GMapLatent. The core of the method is to seamlessly align latent spaces with strict cluster correspondence constraints using the canonical parameterizations of cluster-decorated latent spaces. We first (1) transform the latent space to a canonical parameter domain by composing barycenter translation, optimal transport merging and constrained harmonic mapping, and then (2) compute geometric registration with cluster constraints over the canonical parameter domains. This process realizes a bijective (one-to-one and onto) mapping between newly transformed latent spaces and generates a precise alignment of cluster pairs. Cross-domain generation is then achieved through the aligned latent spaces embedded in the encoder-decoder pipeline. Experiments on gray-scale and color images validate the efficiency, efficacy and applicability of GMapLatent, and demonstrate that the proposed model has superior performance over existing models.
nvBench 2.0: A Benchmark for Natural Language to Visualization under Ambiguity
Mar 17, 2025Natural Language to Visualization (NL2VIS) enables users to create visualizations from natural language queries, making data insights more accessible. However, NL2VIS faces challenges in interpreting ambiguous queries, as users often express their visualization needs in imprecise language. To address this challenge, we introduce nvBench 2.0, a new benchmark designed to evaluate NL2VIS systems in scenarios involving ambiguous queries. nvBench 2.0 includes 7,878 natural language queries and 24,076 corresponding visualizations, derived from 780 tables across 153 domains. It is built using a controlled ambiguity-injection pipeline that generates ambiguous queries through a reverse-generation workflow. By starting with unambiguous seed visualizations and selectively injecting ambiguities, the pipeline yields multiple valid interpretations for each query, with each ambiguous query traceable to its corresponding visualization through step-wise reasoning paths. We evaluate various Large Language Models (LLMs) on their ability to perform ambiguous NL2VIS tasks using nvBench 2.0. We also propose Step-NL2VIS, an LLM-based model trained on nvBench 2.0, which enhances performance in ambiguous scenarios through step-wise preference optimization. Our results show that Step-NL2VIS outperforms all baselines, setting a new state-of-the-art for ambiguous NL2VIS tasks.