 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenColor: Generative Color-Concept Association in Visual Design
Mar 05, 2025Existing approaches for color-concept association typically rely on query-based image referencing, and color extraction from image references. However, these approaches are effective only for common concepts, and are vulnerable to unstable image referencing and varying image conditions. Our formative study with designers underscores the need for primary-accent color compositions and context-dependent colors (e.g., 'clear' vs. 'polluted' sky) in design. In response, we introduce a generative approach for mining semantically resonant colors leveraging images generated by text-to-image models. Our insight is that contemporary text-to-image models can resemble visual patterns from large-scale real-world data. The framework comprises three stages: concept instancing produces generative samples using diffusion models, text-guided image segmentation identifies concept-relevant regions within the image, and color association extracts primarily accompanied by accent colors. Quantitative comparisons with expert designs validate our approach's effectiveness, and we demonstrate the applicability through cases in various design scenarios and a gallery.
GhostVec: A New Threat to Speaker Privacy of End-to-End Speech Recognition System
Nov 17, 2023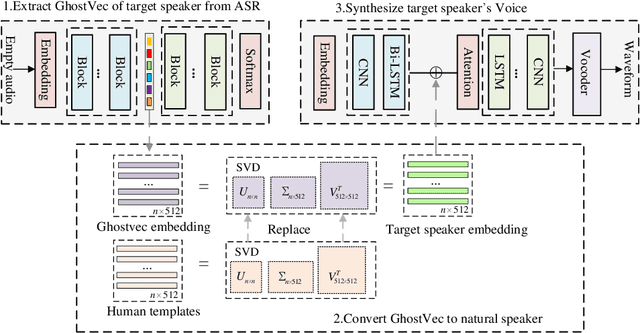
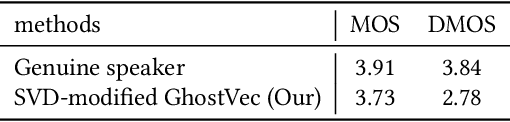
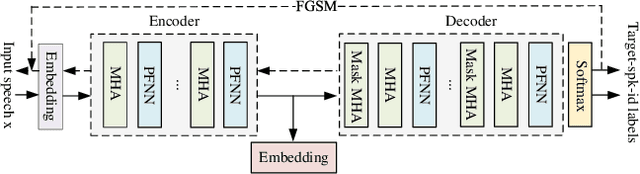
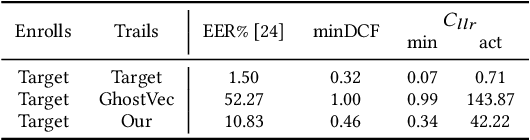
Speaker adaptation systems face privacy concerns, for such systems are trained on private datasets and often overfitting. This paper demonstrates that an attacker can extract speaker information by querying speaker-adapted speech recognition (ASR) systems. We focus on the speaker information of a transformer-based ASR and propose GhostVec, a simple and efficient attack method to extract the speaker information from an encoder-decoder-based ASR system without any external speaker verification system or natural human voice as a reference. To make our results quantitative, we pre-process GhostVec using singular value decomposition (SVD) and synthesize it into waveform. Experiment results show that the synthesized audio of GhostVec reaches 10.83\% EER and 0.47 minDCF with target speakers, which suggests the effectiveness of the proposed method. We hope the preliminary discovery in this study to catalyze future speech recognition research on privacy-preserving topics.
Reprogramming Self-supervised Learning-based Speech Representations for Speaker Anonymization
Nov 17, 2023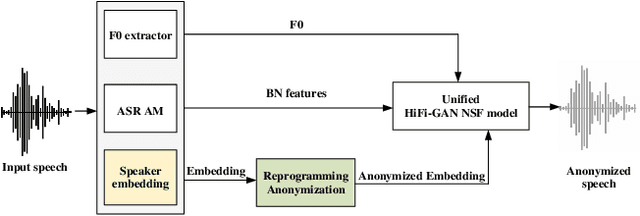


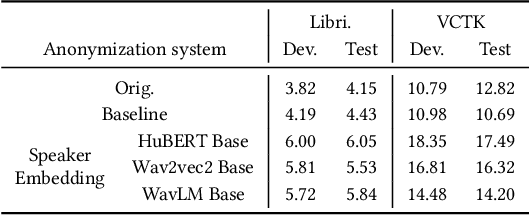
Current speaker anonymization methods, especially with self-supervised learning (SSL) models, require massive computational resources when hiding speaker identity. This paper proposes an effective and parameter-efficient speaker anonymization method based on recent End-to-End model reprogramming technology. To improve the anonymization performance, we first extract speaker representation from large SSL models as the speaker identifies. To hide the speaker's identity, we reprogram the speaker representation by adapting the speaker to a pseudo domain. Extensive experiments are carried out on the VoicePrivacy Challenge (VPC) 2022 datasets to demonstrate the effectiveness of our proposed parameter-efficient learning anonymization methods. Additionally, while achieving comparable performance with the VPC 2022 strong baseline 1.b, our approach consumes less computational resources during anonymization.