 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Multimodal Aspect-Based Sentiment Analysis by LLM-Generated Rationales
May 20, 2025There has been growing interest in Multimodal Aspect-Based Sentiment Analysis (MABSA) in recent years. Existing methods predominantly rely on pre-trained small language models (SLMs) to collect information related to aspects and sentiments from both image and text, with an aim to align these two modalities. However, small SLMs possess limited capacity and knowledge, often resulting in inaccurate identification of meaning, aspects, sentiments, and their interconnections in textual and visual data. On the other hand, Large language models (LLMs) have shown exceptional capabilities in various tasks by effectively exploring fine-grained information in multimodal data. However, some studies indicate that LLMs still fall short compared to fine-tuned small models in the field of ABSA. Based on these findings, we propose a novel framework, termed LRSA, which combines the decision-making capabilities of SLMs with additional information provided by LLMs for MABSA. Specifically, we inject explanations generated by LLMs as rationales into SLMs and employ a dual cross-attention mechanism for enhancing feature interaction and fusion, thereby augmenting the SLMs' ability to identify aspects and sentiments. We evaluated our method using two baseline models, numerous experiments highlight the superiority of our approach on three widely-used benchmarks, indicating its generalizability and applicability to most pre-trained models for MABSA.
Human-LLM Hybrid Text Answer Aggregation for Crowd Annotations
Oct 22, 2024



The quality is a crucial issue for crowd annotations. Answer aggregation is an important type of solution. The aggregated answers estimated from multiple crowd answers to the same instance are the eventually collected annotations, rather than the individual crowd answers themselves. Recently, the capability of Large Language Models (LLMs) on data annotation tasks has attracted interest from researchers. Most of the existing studies mainly focus on the average performance of individual crowd workers; several recent works studied the scenarios of aggregation on categorical labels and LLMs used as label creators. However, the scenario of aggregation on text answers and the role of LLMs as aggregators are not yet well-studied. In this paper, we investigate the capability of LLMs as aggregators in the scenario of close-ended crowd text answer aggregation. We propose a human-LLM hybrid text answer aggregation method with a Creator-Aggregator Multi-Stage (CAMS) crowdsourcing framework. We make the experiments based on public crowdsourcing datasets. The results show the effectiveness of our approach based on the collaboration of crowd workers and LLMs.
AHP-Powered LLM Reasoning for Multi-Criteria Evaluation of Open-Ended Responses
Oct 02, 2024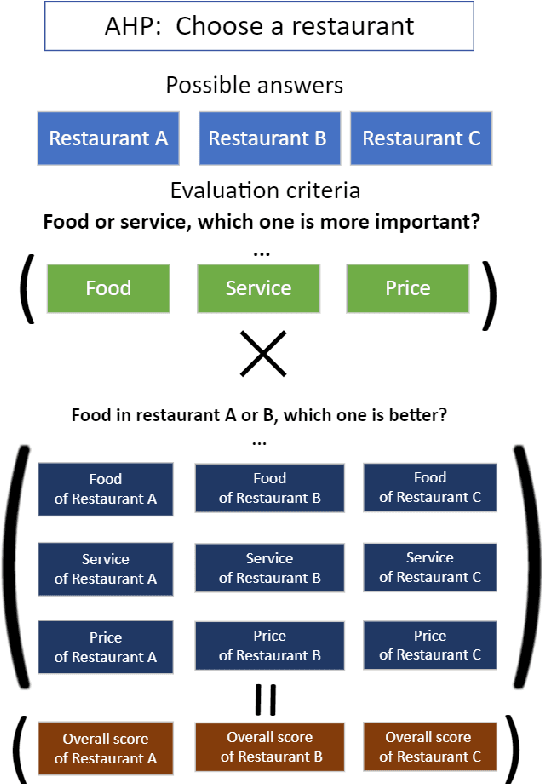



Question answering (QA) tasks have been extensively studied in the field of natural language processing (NLP). Answers to open-ended questions are highly diverse and difficult to quantify, and cannot be simply evaluated as correct or incorrect, unlike close-ended questions with definitive answers. While large language models (LLMs) have demonstrated strong capabilities across various tasks, they exhibit relatively weaker performance in evaluating answers to open-ended questions. In this study, we propose a method that leverages LLMs and the analytic hierarchy process (AHP) to assess answers to open-ended questions. We utilized LLMs to generate multiple evaluation criteria for a question. Subsequently, answers were subjected to pairwise comparisons under each criterion with LLMs, and scores for each answer were calculated in the AHP. We conducted experiments on four datasets using both ChatGPT-3.5-turbo and GPT-4. Our results indicate that our approach more closely aligns with human judgment compared to the four baselines. Additionally, we explored the impact of the number of criteria, variations in models, and differences in datasets on the results.
A Generalized Model for Multidimensional Intransitivity
Sep 28, 2024Intransitivity is a critical issue in pairwise preference modeling. It refers to the intransitive pairwise preferences between a group of players or objects that potentially form a cyclic preference chain and has been long discussed in social choice theory in the context of the dominance relationship. However, such multifaceted intransitivity between players and the corresponding player representations in high dimensions is difficult to capture. In this paper, we propose a probabilistic model that jointly learns each player's d-dimensional representation (d>1) and a dataset-specific metric space that systematically captures the distance metric in Rd over the embedding space. Interestingly, by imposing additional constraints in the metric space, our proposed model degenerates to former models used in intransitive representation learning. Moreover, we present an extensive quantitative investigation of the vast existence of intransitive relationships between objects in various real-world benchmark datasets. To our knowledge, this investigation is the first of this type. The predictive performance of our proposed method on different real-world datasets, including social choice, election, and online game datasets, shows that our proposed method outperforms several competing methods in terms of prediction accuracy.
Evaluating Saliency Explanations in NLP by Crowdsourcing
May 17, 2024
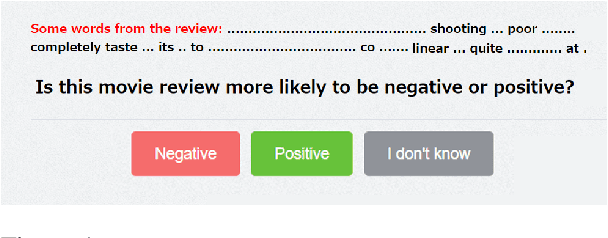


Deep learning models have performed well on many NLP tasks. However, their internal mechanisms are typically difficult for humans to understand. The development of methods to explain models has become a key issue in the reliability of deep learning models in many important applications. Various saliency explanation methods, which give each feature of input a score proportional to the contribution of output, have been proposed to determine the part of the input which a model values most. Despite a considerable body of work on the evaluation of saliency methods, whether the results of various evaluation metrics agree with human cognition remains an open question. In this study, we propose a new human-based method to evaluate saliency methods in NLP by crowdsourcing. We recruited 800 crowd workers and empirically evaluated seven saliency methods on two datasets with the proposed method. We analyzed the performance of saliency methods, compared our results with existing automated evaluation methods, and identified notable differences between NLP and computer vision (CV) fields when using saliency methods. The instance-level data of our crowdsourced experiments and the code to reproduce the explanations are available at https://github.com/xtlu/lreccoling_evaluation.
CaDRec: Contextualized and Debiased Recommender Model
Apr 10, 2024Recommender models aimed at mining users' behavioral patterns have raised great attention as one of the essential applications in daily life. Recent work on graph neural networks (GNNs) or debiasing methods has attained remarkable gains. However, they still suffer from (1) over-smoothing node embeddings caused by recursive convolutions with GNNs, and (2) the skewed distribution of interactions due to popularity and user-individual biases. This paper proposes a contextualized and debiased recommender model (CaDRec). To overcome the over-smoothing issue, we explore a novel hypergraph convolution operator that can select effective neighbors during convolution by introducing both structural context and sequential context. To tackle the skewed distribution, we propose two strategies for disentangling interactions: (1) modeling individual biases to learn unbiased item embeddings, and (2) incorporating item popularity with positional encoding. Moreover, we mathematically show that the imbalance of the gradients to update item embeddings exacerbates the popularity bias, thus adopting regularization and weighting schemes as solutions. Extensive experiments on four datasets demonstrate the superiority of the CaDRec against state-of-the-art (SOTA) methods. Our source code and data are released at https://github.com/WangXFng/CaDRec.
Enhanced Coherence-Aware Network with Hierarchical Disentanglement for Aspect-Category Sentiment Analysis
Mar 15, 2024



Aspect-category-based sentiment analysis (ACSA), which aims to identify aspect categories and predict their sentiments has been intensively studied due to its wide range of NLP applications. Most approaches mainly utilize intrasentential features. However, a review often includes multiple different aspect categories, and some of them do not explicitly appear in the review. Even in a sentence, there is more than one aspect category with its sentiments, and they are entangled intra-sentence, which makes the model fail to discriminately preserve all sentiment characteristics. In this paper, we propose an enhanced coherence-aware network with hierarchical disentanglement (ECAN) for ACSA tasks. Specifically, we explore coherence modeling to capture the contexts across the whole review and to help the implicit aspect and sentiment identification. To address the issue of multiple aspect categories and sentiment entanglement, we propose a hierarchical disentanglement module to extract distinct categories and sentiment features. Extensive experimental and visualization results show that our ECAN effectively decouples multiple categories and sentiments entangled in the coherence representations and achieves state-of-the-art (SOTA) performance. Our codes and data are available online: \url{https://github.com/cuijin-23/ECAN}.
A Comparative Study on Annotation Quality of Crowdsourcing and LLM via Label Aggregation
Jan 18, 2024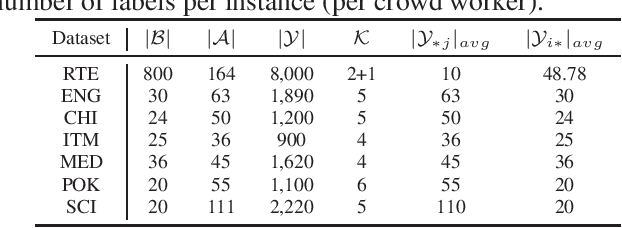
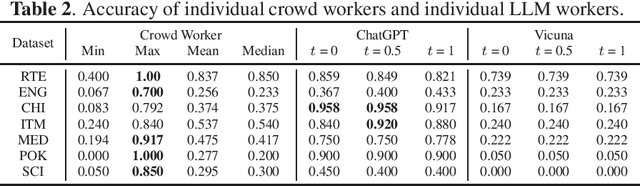
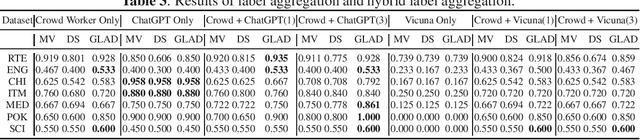
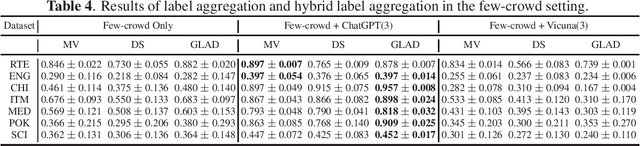
Whether Large Language Models (LLMs) can outperform crowdsourcing on the data annotation task is attracting interest recently. Some works verified this issue with the average performance of individual crowd workers and LLM workers on some specific NLP tasks by collecting new datasets. However, on the one hand, existing datasets for the studies of annotation quality in crowdsourcing are not yet utilized in such evaluations, which potentially provide reliable evaluations from a different viewpoint. On the other hand, the quality of these aggregated labels is crucial because, when utilizing crowdsourcing, the estimated labels aggregated from multiple crowd labels to the same instances are the eventually collected labels. Therefore, in this paper, we first investigate which existing crowdsourcing datasets can be used for a comparative study and create a benchmark. We then compare the quality between individual crowd labels and LLM labels and make the evaluations on the aggregated labels. In addition, we propose a Crowd-LLM hybrid label aggregation method and verify the performance. We find that adding LLM labels from good LLMs to existing crowdsourcing datasets can enhance the quality of the aggregated labels of the datasets, which is also higher than the quality of LLM labels themselves.
FedCPC: An Effective Federated Contrastive Learning Method for Privacy Preserving Early-Stage Alzheimer's Speech Detection
Nov 21, 2023The early-stage Alzheimer's disease (AD) detection has been considered an important field of medical studies. Like traditional machine learning methods, speech-based automatic detection also suffers from data privacy risks because the data of specific patients are exclusive to each medical institution. A common practice is to use federated learning to protect the patients' data privacy. However, its distributed learning process also causes performance reduction. To alleviate this problem while protecting user privacy, we propose a federated contrastive pre-training (FedCPC) performed before federated training for AD speech detection, which can learn a better representation from raw data and enables different clients to share data in the pre-training and training stages. Experimental results demonstrate that the proposed methods can achieve satisfactory performance while preserving data privacy.
Reprogramming Self-supervised Learning-based Speech Representations for Speaker Anonymization
Nov 17, 2023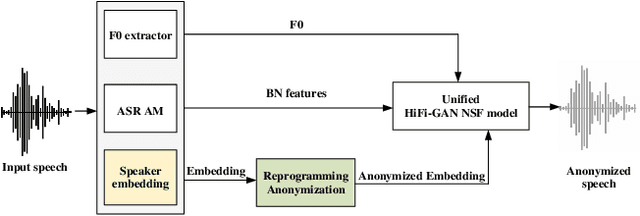


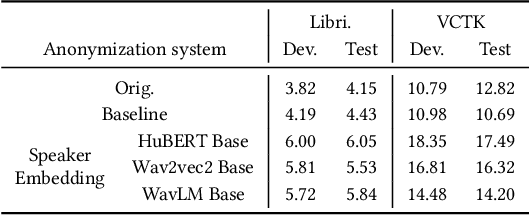
Current speaker anonymization methods, especially with self-supervised learning (SSL) models, require massive computational resources when hiding speaker identity. This paper proposes an effective and parameter-efficient speaker anonymization method based on recent End-to-End model reprogramming technology. To improve the anonymization performance, we first extract speaker representation from large SSL models as the speaker identifies. To hide the speaker's identity, we reprogram the speaker representation by adapting the speaker to a pseudo domain. Extensive experiments are carried out on the VoicePrivacy Challenge (VPC) 2022 datasets to demonstrate the effectiveness of our proposed parameter-efficient learning anonymization methods. Additionally, while achieving comparable performance with the VPC 2022 strong baseline 1.b, our approach consumes less computational resources during anonymization.