 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRICE: A Pretrained Model for Cross-Database Cardinality Estimation
Jun 03, 2024

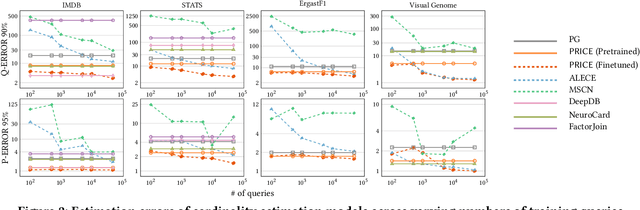
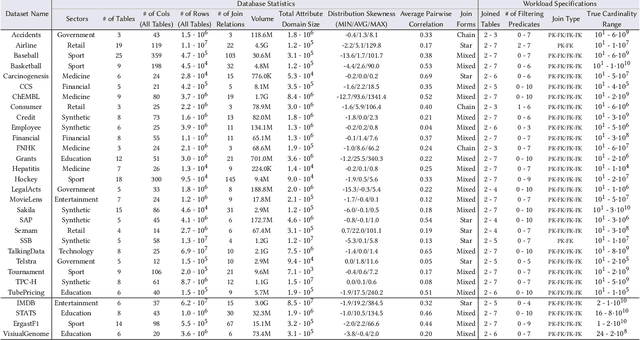
Cardinality estimation (CardEst) is essential for optimizing query execution plans. Recent ML-based CardEst methods achieve high accuracy but face deployment challenges due to high preparation costs and lack of transferability across databases. In this paper, we propose PRICE, a PRetrained multI-table CardEst model, which addresses these limitations. PRICE takes low-level but transferable features w.r.t. data distributions and query information and elegantly applies self-attention models to learn meta-knowledge to compute cardinality in any database. It is generally applicable to any unseen new database to attain high estimation accuracy, while its preparation cost is as little as the basic one-dimensional histogram-based CardEst methods. Moreover, PRICE can be finetuned to further enhance its performance on any specific database. We pretrained PRICE using 30 diverse datasets, completing the process in about 5 hours with a resulting model size of only about 40MB. Evaluations show that PRICE consistently outperforms existing methods, achieving the highest estimation accuracy on several unseen databases and generating faster execution plans with lower overhead. After finetuning with a small volume of databasespecific queries, PRICE could even find plans very close to the optimal ones. Meanwhile, PRICE is generally applicable to different settings such as data updates, data scaling, and query workload shifts. We have made all of our data and codes publicly available at https://github.com/StCarmen/PRICE.
FedCPC: An Effective Federated Contrastive Learning Method for Privacy Preserving Early-Stage Alzheimer's Speech Detection
Nov 21, 2023The early-stage Alzheimer's disease (AD) detection has been considered an important field of medical studies. Like traditional machine learning methods, speech-based automatic detection also suffers from data privacy risks because the data of specific patients are exclusive to each medical institution. A common practice is to use federated learning to protect the patients' data privacy. However, its distributed learning process also causes performance reduction. To alleviate this problem while protecting user privacy, we propose a federated contrastive pre-training (FedCPC) performed before federated training for AD speech detection, which can learn a better representation from raw data and enables different clients to share data in the pre-training and training stages. Experimental results demonstrate that the proposed methods can achieve satisfactory performance while preserving data privacy.