 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyFormer: Scalable Node-wise Filters via Polynomial Graph Transformer
Jul 19, 2024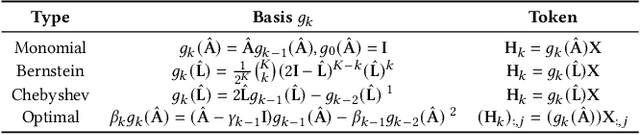
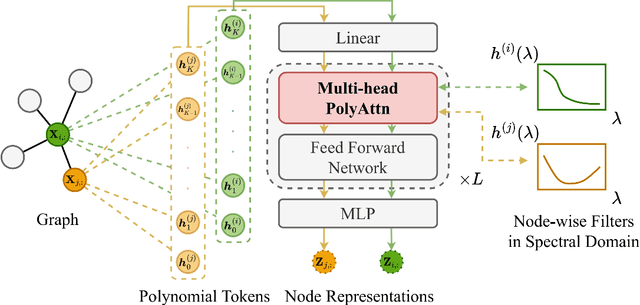
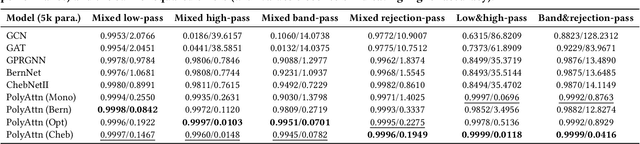
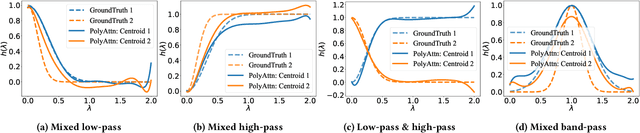
Spectral Graph Neural Networks have demonstrated superior performance in graph representation learning. However, many current methods focus on employing shared polynomial coefficients for all nodes, i.e., learning node-unified filters, which limits the filters' flexibility for node-level tasks. The recent DSF attempts to overcome this limitation by learning node-wise coefficients based on positional encoding. However, the initialization and updating process of the positional encoding are burdensome, hindering scalability on large-scale graphs. In this work, we propose a scalable node-wise filter, PolyAttn. Leveraging the attention mechanism, PolyAttn can directly learn node-wise filters in an efficient manner, offering powerful representation capabilities. Building on PolyAttn, we introduce the whole model, named PolyFormer. In the lens of Graph Transformer models, PolyFormer, which calculates attention scores within nodes, shows great scalability. Moreover, the model captures spectral information, enhancing expressiveness while maintaining efficiency. With these advantages, PolyFormer offers a desirable balance between scalability and expressiveness for node-level tasks. Extensive experiments demonstrate that our proposed methods excel at learning arbitrary node-wise filters, showing superior performance on both homophilic and heterophilic graphs, and handling graphs containing up to 100 million nodes. The code is available at https://github.com/air029/PolyFormer.
PRICE: A Pretrained Model for Cross-Database Cardinality Estimation
Jun 03, 2024

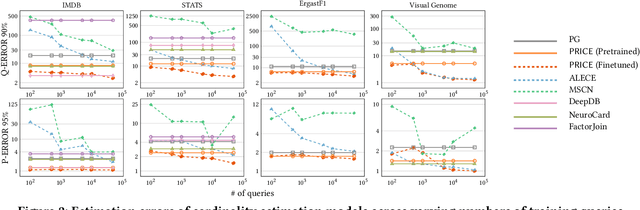
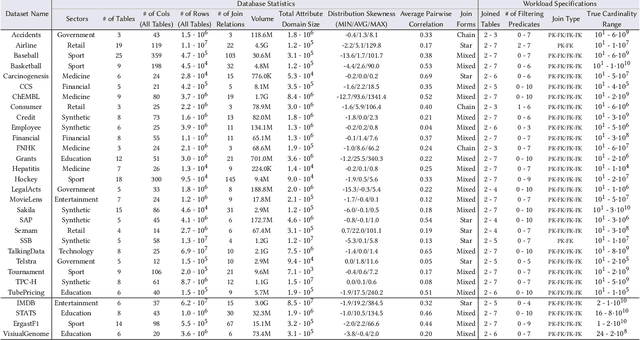
Cardinality estimation (CardEst) is essential for optimizing query execution plans. Recent ML-based CardEst methods achieve high accuracy but face deployment challenges due to high preparation costs and lack of transferability across databases. In this paper, we propose PRICE, a PRetrained multI-table CardEst model, which addresses these limitations. PRICE takes low-level but transferable features w.r.t. data distributions and query information and elegantly applies self-attention models to learn meta-knowledge to compute cardinality in any database. It is generally applicable to any unseen new database to attain high estimation accuracy, while its preparation cost is as little as the basic one-dimensional histogram-based CardEst methods. Moreover, PRICE can be finetuned to further enhance its performance on any specific database. We pretrained PRICE using 30 diverse datasets, completing the process in about 5 hours with a resulting model size of only about 40MB. Evaluations show that PRICE consistently outperforms existing methods, achieving the highest estimation accuracy on several unseen databases and generating faster execution plans with lower overhead. After finetuning with a small volume of databasespecific queries, PRICE could even find plans very close to the optimal ones. Meanwhile, PRICE is generally applicable to different settings such as data updates, data scaling, and query workload shifts. We have made all of our data and codes publicly available at https://github.com/StCarmen/PRICE.