 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRICE: A Pretrained Model for Cross-Database Cardinality Estimation
Jun 03, 2024

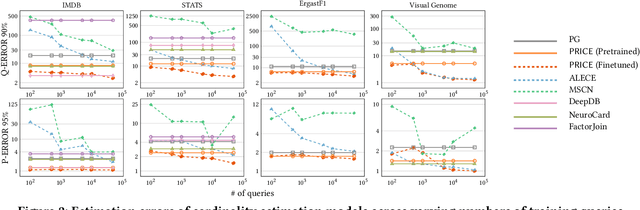
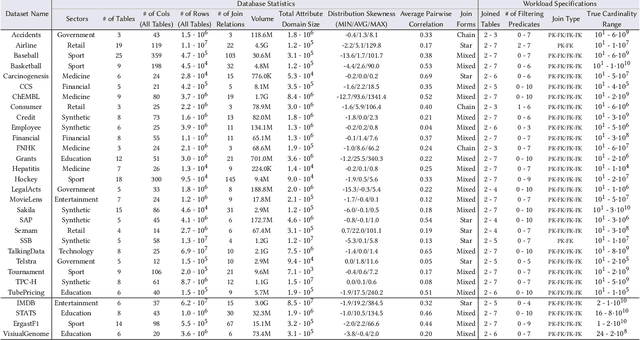
Cardinality estimation (CardEst) is essential for optimizing query execution plans. Recent ML-based CardEst methods achieve high accuracy but face deployment challenges due to high preparation costs and lack of transferability across databases. In this paper, we propose PRICE, a PRetrained multI-table CardEst model, which addresses these limitations. PRICE takes low-level but transferable features w.r.t. data distributions and query information and elegantly applies self-attention models to learn meta-knowledge to compute cardinality in any database. It is generally applicable to any unseen new database to attain high estimation accuracy, while its preparation cost is as little as the basic one-dimensional histogram-based CardEst methods. Moreover, PRICE can be finetuned to further enhance its performance on any specific database. We pretrained PRICE using 30 diverse datasets, completing the process in about 5 hours with a resulting model size of only about 40MB. Evaluations show that PRICE consistently outperforms existing methods, achieving the highest estimation accuracy on several unseen databases and generating faster execution plans with lower overhead. After finetuning with a small volume of databasespecific queries, PRICE could even find plans very close to the optimal ones. Meanwhile, PRICE is generally applicable to different settings such as data updates, data scaling, and query workload shifts. We have made all of our data and codes publicly available at https://github.com/StCarmen/PRICE.
Baihe: SysML Framework for AI-driven Databases
Dec 29, 2021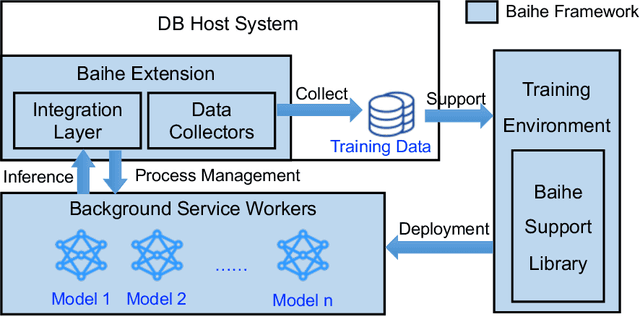
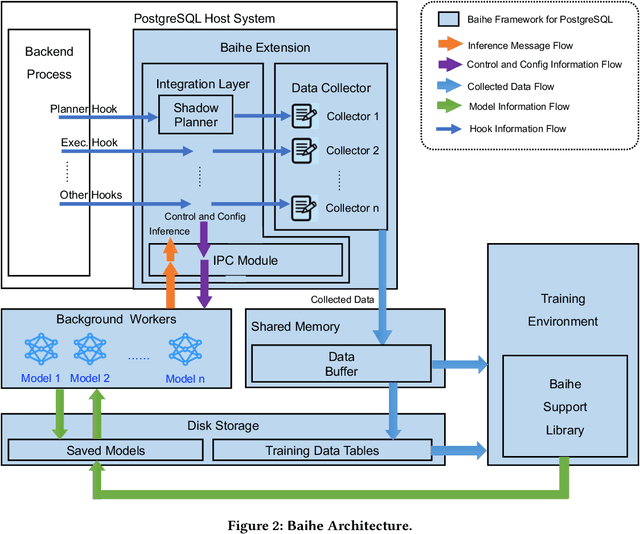
We present Baihe, a SysML Framework for AI-driven Databases. Using Baihe, an existing relational database system may be retrofitted to use learned components for query optimization or other common tasks, such as e.g. learned structure for indexing. To ensure the practicality and real world applicability of Baihe, its high level architecture is based on the following requirements: separation from the core system, minimal third party dependencies, Robustness, stability and fault tolerance, as well as stability and configurability. Based on the high level architecture, we then describe a concrete implementation of Baihe for PostgreSQL and present example use cases for learned query optimizers. To serve both practitioners, as well as researchers in the DB and AI4DB community Baihe for PostgreSQL will be released under open source license.
Glue: Adaptively Merging Single Table Cardinality to Estimate Join Query Size
Dec 07, 2021
Cardinality estimation (CardEst), a central component of the query optimizer, plays a significant role in generating high-quality query plans in DBMS. The CardEst problem has been extensively studied in the last several decades, using both traditional and ML-enhanced methods. Whereas, the hardest problem in CardEst, i.e., how to estimate the join query size on multiple tables, has not been extensively solved. Current methods either reply on independence assumptions or apply techniques with heavy burden, whose performance is still far from satisfactory. Even worse, existing CardEst methods are often designed to optimize one goal, i.e., inference speed or estimation accuracy, which can not adapt to different occasions. In this paper, we propose a very general framework, called Glue, to tackle with these challenges. Its key idea is to elegantly decouple the correlations across different tables and losslessly merge single table CardEst results to estimate the join query size. Glue supports obtaining the single table-wise CardEst results using any existing CardEst method and can process any complex join schema. Therefore, it easily adapts to different scenarios having different performance requirements, i.e., OLTP with fast estimation time or OLAP with high estimation accuracy. Meanwhile, we show that Glue can be seamlessly integrated into the plan search process and is able to support counting distinct number of values. All these properties exhibit the potential advances of deploying Glue in real-world DBMS.