 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLero: A Learning-to-Rank Query Optimizer
Feb 20, 2023A recent line of works apply machine learning techniques to assist or rebuild cost-based query optimizers in DBMS. While exhibiting superiority in some benchmarks, their deficiencies, e.g., unstable performance, high training cost, and slow model updating, stem from the inherent hardness of predicting the cost or latency of execution plans using machine learning models. In this paper, we introduce a learning-to-rank query optimizer, called Lero, which builds on top of a native query optimizer and continuously learns to improve the optimization performance. The key observation is that the relative order or rank of plans, rather than the exact cost or latency, is sufficient for query optimization. Lero employs a pairwise approach to train a classifier to compare any two plans and tell which one is better. Such a binary classification task is much easier than the regression task to predict the cost or latency, in terms of model efficiency and accuracy. Rather than building a learned optimizer from scratch, Lero is designed to leverage decades of wisdom of databases and improve the native query optimizer. With its non-intrusive design, Lero can be implemented on top of any existing DBMS with minimal integration efforts. We implement Lero and demonstrate its outstanding performance using PostgreSQL. In our experiments, Lero achieves near optimal performance on several benchmarks. It reduces the plan execution time of the native optimizer in PostgreSQL by up to 70% and other learned query optimizers by up to 37%. Meanwhile, Lero continuously learns and automatically adapts to query workloads and changes in data.
Estimation of Doubly-Dispersive Channels in Linearly Precoded Multicarrier Systems Using Smoothness Regularization
Oct 11, 2022
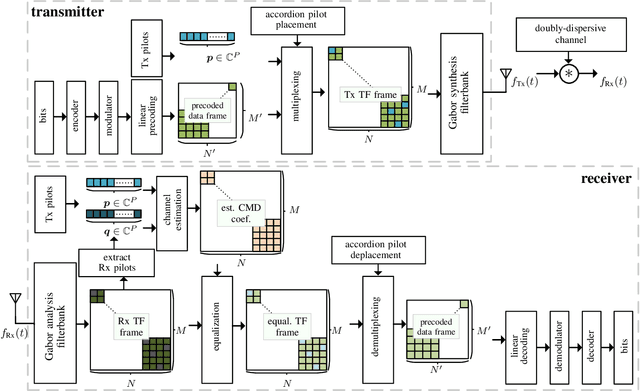


In this paper, we propose a novel channel estimation scheme for pulse-shaped multicarrier systems using smoothness regularization for ultra-reliable low-latency communication (URLLC). It can be applied to any multicarrier system with or without linear precoding to estimate challenging doubly-dispersive channels. A recently proposed modulation scheme using orthogonal precoding is orthogonal time-frequency and space modulation (OTFS). In OTFS, pilot and data symbols are placed in delay-Doppler (DD) domain and are jointly precoded to the time-frequency (TF) domain. On the one hand, such orthogonal precoding increases the achievable channel estimation accuracy and enables high TF diversity at the receiver. On the other hand, it introduces leakage effects which requires extensive leakage suppression when the piloting is jointly precoded with the data. To avoid this, we propose to precode the data symbols only, place pilot symbols without precoding into the TF domain, and estimate the channel coefficients by interpolating smooth functions from the pilot samples. Furthermore, we present a piloting scheme enabling a smooth control of the number and position of the pilot symbols. Our numerical results suggest that the proposed scheme provides accurate channel estimation with reduced signaling overhead compared to standard estimators using Wiener filtering in the discrete DD domain.
Baihe: SysML Framework for AI-driven Databases
Dec 29, 2021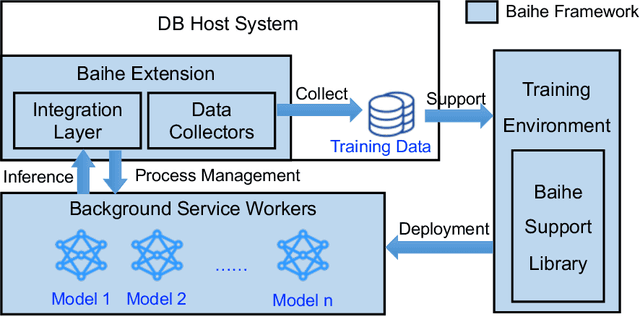
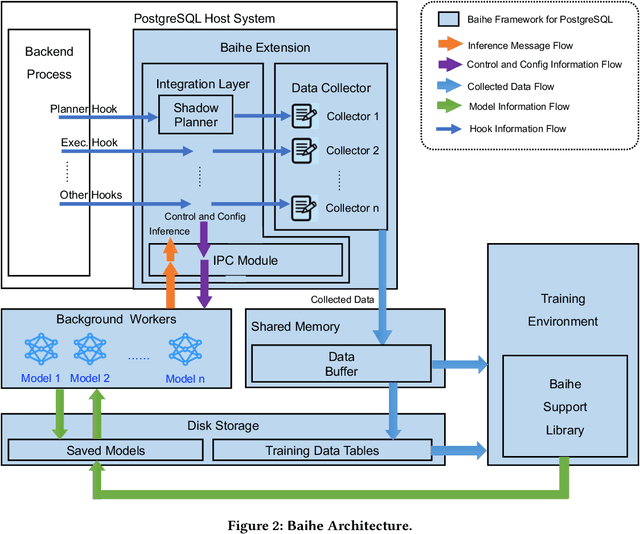
We present Baihe, a SysML Framework for AI-driven Databases. Using Baihe, an existing relational database system may be retrofitted to use learned components for query optimization or other common tasks, such as e.g. learned structure for indexing. To ensure the practicality and real world applicability of Baihe, its high level architecture is based on the following requirements: separation from the core system, minimal third party dependencies, Robustness, stability and fault tolerance, as well as stability and configurability. Based on the high level architecture, we then describe a concrete implementation of Baihe for PostgreSQL and present example use cases for learned query optimizers. To serve both practitioners, as well as researchers in the DB and AI4DB community Baihe for PostgreSQL will be released under open source license.
Glue: Adaptively Merging Single Table Cardinality to Estimate Join Query Size
Dec 07, 2021
Cardinality estimation (CardEst), a central component of the query optimizer, plays a significant role in generating high-quality query plans in DBMS. The CardEst problem has been extensively studied in the last several decades, using both traditional and ML-enhanced methods. Whereas, the hardest problem in CardEst, i.e., how to estimate the join query size on multiple tables, has not been extensively solved. Current methods either reply on independence assumptions or apply techniques with heavy burden, whose performance is still far from satisfactory. Even worse, existing CardEst methods are often designed to optimize one goal, i.e., inference speed or estimation accuracy, which can not adapt to different occasions. In this paper, we propose a very general framework, called Glue, to tackle with these challenges. Its key idea is to elegantly decouple the correlations across different tables and losslessly merge single table CardEst results to estimate the join query size. Glue supports obtaining the single table-wise CardEst results using any existing CardEst method and can process any complex join schema. Therefore, it easily adapts to different scenarios having different performance requirements, i.e., OLTP with fast estimation time or OLAP with high estimation accuracy. Meanwhile, we show that Glue can be seamlessly integrated into the plan search process and is able to support counting distinct number of values. All these properties exhibit the potential advances of deploying Glue in real-world DBMS.
Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation
Sep 15, 2021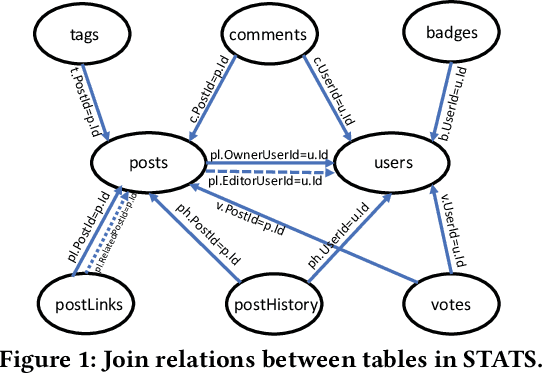
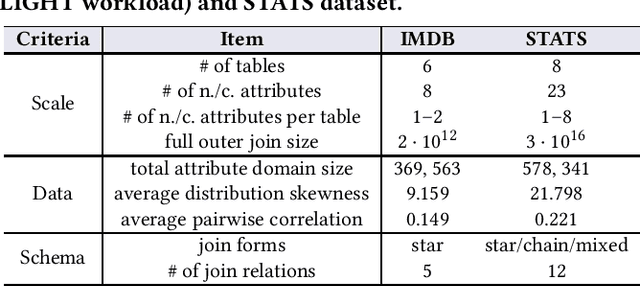
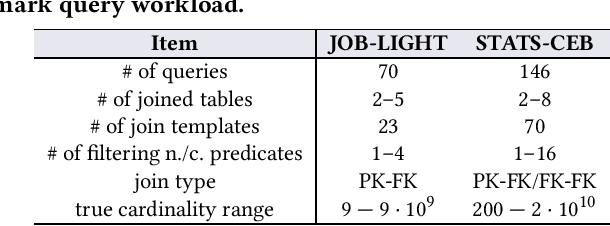
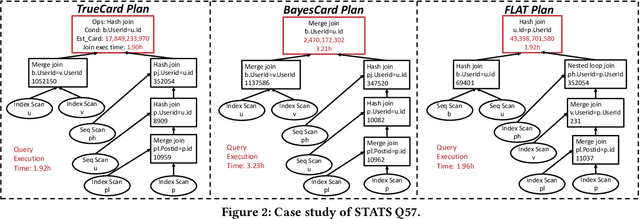
Cardinality estimation (CardEst) plays a significant role in generating high-quality query plans for a query optimizer in DBMS. In the last decade, an increasing number of advanced CardEst methods (especially ML-based) have been proposed with outstanding estimation accuracy and inference latency. However, there exists no study that systematically evaluates the quality of these methods and answer the fundamental problem: to what extent can these methods improve the performance of query optimizer in real-world settings, which is the ultimate goal of a CardEst method. In this paper, we comprehensively and systematically compare the effectiveness of CardEst methods in a real DBMS. We establish a new benchmark for CardEst, which contains a new complex real-world dataset STATS and a diverse query workload STATS-CEB. We integrate multiple most representative CardEst methods into an open-source database system PostgreSQL, and comprehensively evaluate their true effectiveness in improving query plan quality, and other important aspects affecting their applicability, ranging from inference latency, model size, and training time, to update efficiency and accuracy. We obtain a number of key findings for the CardEst methods, under different data and query settings. Furthermore, we find that the widely used estimation accuracy metric(Q-Error) cannot distinguish the importance of different sub-plan queries during query optimization and thus cannot truly reflect the query plan quality generated by CardEst methods. Therefore, we propose a new metric P-Error to evaluate the performance of CardEst methods, which overcomes the limitation of Q-Error and is able to reflect the overall end-to-end performance of CardEst methods. We have made all of the benchmark data and evaluation code publicly available at https://github.com/Nathaniel-Han/End-to-End-CardEst-Benchmark.
QoS Prediction for 5G Connected and Automated Driving
Jul 11, 2021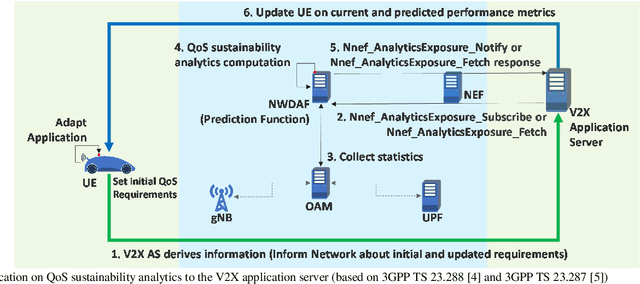
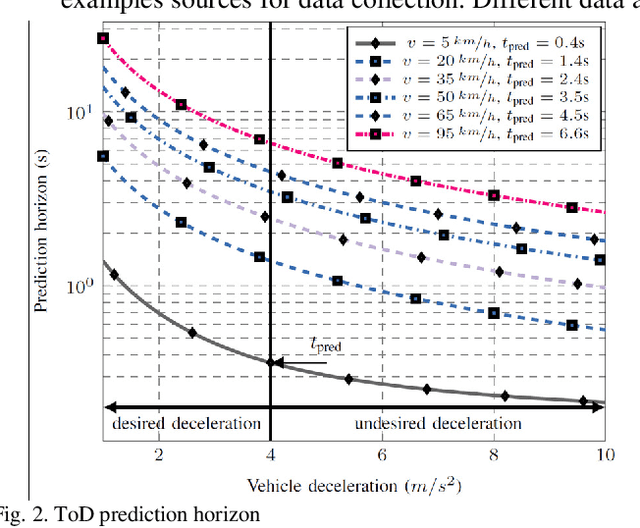
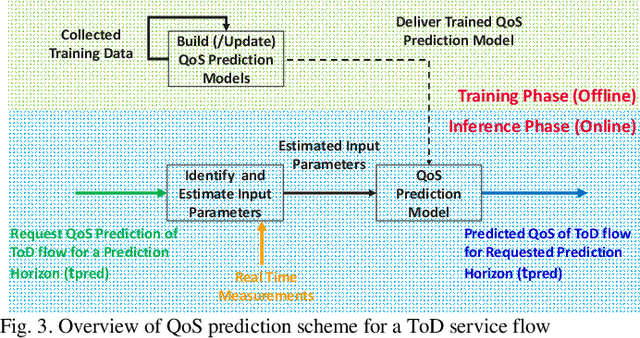
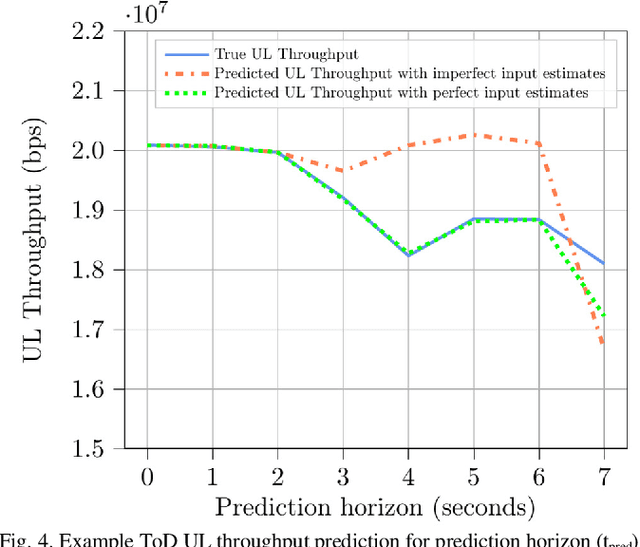
5G communication system can support the demanding quality-of-service (QoS) requirements of many advanced vehicle-to-everything (V2X) use cases. However, the safe and efficient driving, especially of automated vehicles, may be affected by sudden changes of the provided QoS. For that reason, the prediction of the QoS changes and the early notification of these predicted changes to the vehicles have been recently enabled by 5G communication systems. This solution enables the vehicles to avoid or mitigate the effect of sudden QoS changes at the application level. This article describes how QoS prediction could be generated by a 5G communication system and delivered to a V2X application. The tele-operated driving use case is used as an example to analyze the feasibility of a QoS prediction scheme. Useful recommendations for the development of a QoS prediction solution are provided, while open research topics are identified.
Efficient and Scalable Structure Learning for Bayesian Networks: Algorithms and Applications
Dec 07, 2020


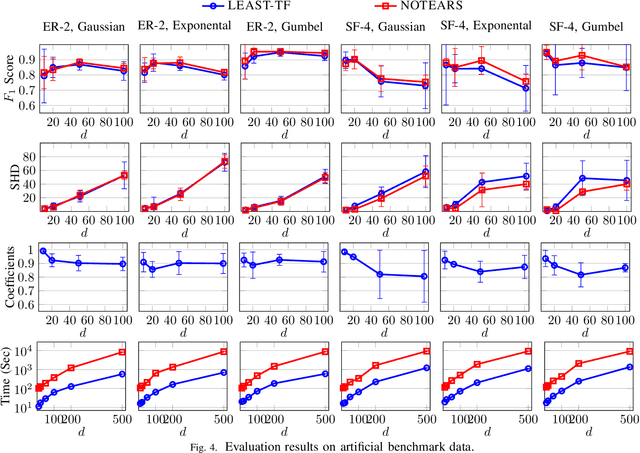
Structure Learning for Bayesian network (BN) is an important problem with extensive research. It plays central roles in a wide variety of applications in Alibaba Group. However, existing structure learning algorithms suffer from considerable limitations in real world applications due to their low efficiency and poor scalability. To resolve this, we propose a new structure learning algorithm LEAST, which comprehensively fulfills our business requirements as it attains high accuracy, efficiency and scalability at the same time. The core idea of LEAST is to formulate the structure learning into a continuous constrained optimization problem, with a novel differentiable constraint function measuring the acyclicity of the resulting graph. Unlike with existing work, our constraint function is built on the spectral radius of the graph and could be evaluated in near linear time w.r.t. the graph node size. Based on it, LEAST can be efficiently implemented with low storage overhead. According to our benchmark evaluation, LEAST runs 1 to 2 orders of magnitude faster than state of the art method with comparable accuracy, and it is able to scale on BNs with up to hundreds of thousands of variables. In our production environment, LEAST is deployed and serves for more than 20 applications with thousands of executions per day. We describe a concrete scenario in a ticket booking service in Alibaba, where LEAST is applied to build a near real-time automatic anomaly detection and root error cause analysis system. We also show that LEAST unlocks the possibility of applying BN structure learning in new areas, such as large-scale gene expression data analysis and explainable recommendation system.
FSPN: A New Class of Probabilistic Graphical Model
Nov 20, 2020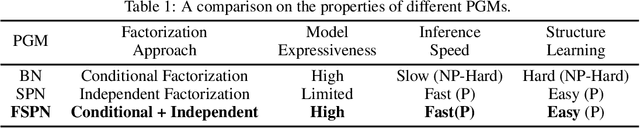
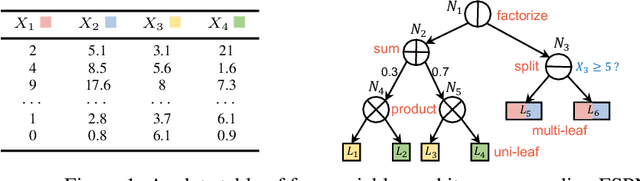
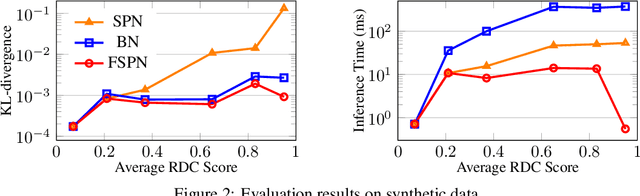
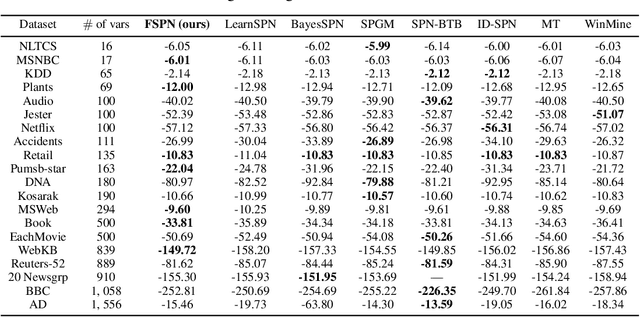
We introduce factorize sum split product networks (FSPNs), a new class of probabilistic graphical models (PGMs). FSPNs are designed to overcome the drawbacks of existing PGMs in terms of estimation accuracy and inference efficiency. Specifically, Bayesian networks (BNs) have low inference speed and performance of tree structured sum product networks(SPNs) significantly degrades in presence of highly correlated variables. FSPNs absorb their advantages by adaptively modeling the joint distribution of variables according to their dependence degree, so that one can simultaneously attain the two desirable goals: high estimation accuracy and fast inference speed. We present efficient probability inference and structure learning algorithms for FSPNs, along with a theoretical analysis and extensive evaluation evidence. Our experimental results on synthetic and benchmark datasets indicate the superiority of FSPN over other PGMs.
FLAT: Fast, Lightweight and Accurate Method for Cardinality Estimation
Nov 18, 2020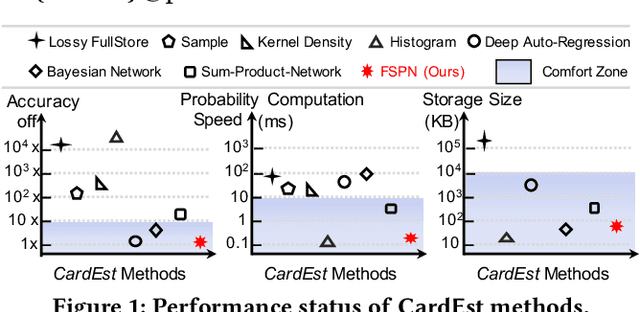
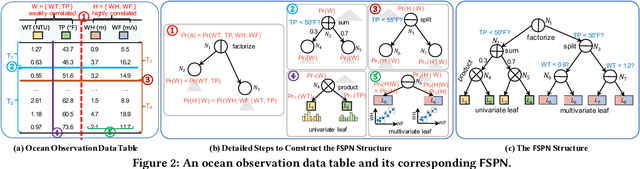
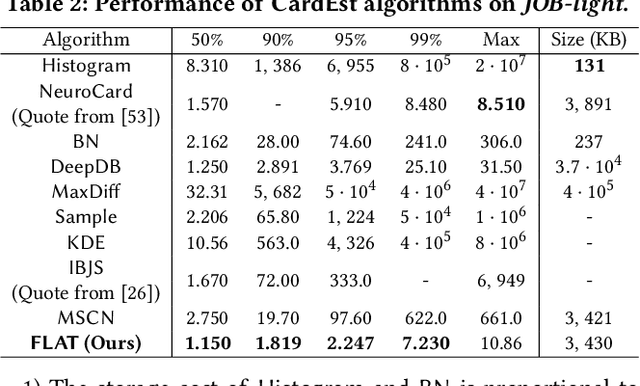

Query optimizers rely on accurate cardinality estimation (CardEst) to produce good execution plans. The core problem of CardEst is how to model the rich joint distribution of attributes in an accurate and compact manner. Despite decades of research, existing methods either over simplify the models only using independent factorization which leads to inaccurate estimates and sub optimal query plans, or over-complicate them by lossless conditional factorization without any independent assumption which results in slow probability computation. In this paper, we propose FLAT, a CardEst method that is simultaneously fast in probability computation, lightweight in model size and accurate in estimation quality. The key idea of FLAT is a novel unsupervised graphical model, called FSPN. It utilizes both independent and conditional factorization to adaptively model different levels of attributes correlations, and thus subsumes all existing CardEst models and dovetails their advantages. FLAT supports efficient online probability computation in near liner time on the underlying FSPN model, and provides effective offline model construction. It can estimate cardinality for both single table queries and multi-table join queries. Extensive experimental study demonstrates the superiority of FLAT over existing CardEst methods on well-known benchmarks: FLAT achieves 1 to 5 orders of magnitude better accuracy, 1 to 3 orders of magnitude faster probability computation speed (around 0.2ms) and 1 to 2 orders of magnitude lower storage cost (only tens of KB).