 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecDB: LLM-Generated Customized Databases via Feature-Oriented Decomposition
May 29, 2026Mainstream relational databases ship a uniform feature set across deployments, although individual workloads exercise only a fraction of the available subsystems. We investigate whether a database can instead be generated on demand with a feature set matched to the target workload. We present SpecDB, a system that uses large language models (LLMs) to synthesize customized relational databases. We survey 9 production systems and decompose them into 10 functional modules, each further divided into implementation variants. To capture cross-module dependencies, including cases where implementations in disjoint subtrees must be co-designed, we adopt the FODA feature model and extend it with a cooperate edge, yielding a dependency graph DBGraph. SpecDB operationalizes DBGraph through a layered module-construction pipeline in which each module is generated, validated, and integrated by a dedicated subagent (driven by three inner agents: Main, Tester, Architect), and a Refining Agent that iteratively repairs and tunes the assembled database against a user-supplied refining harness with read-only access to existing database source code. A companion selection component translates a natural-language workload description into a set of implementation variants, providing an end-to-end pipeline from workload description to deployable database. We evaluate SpecDB on TPC-C with BenchmarkSQL. The generated database (23,779 lines of Rust) completes 60-minute TPC-C at 1 and 10 warehouses with zero errors. At 10 warehouses it reaches tpmC=130, compared to 128 for PostgreSQL and 127 for MySQL, with comparable latency at ~3% of their code size. Because the agent operates at module-specification level rather than product source, it can in principle combine techniques across system boundaries. Paired with falling LLM costs, generating a purpose-built database for a target workload is becoming straightforward.
OpenHospital: A Thing-in-itself Arena for Evolving and Benchmarking LLM-based Collective Intelligence
Mar 17, 2026Large Language Model (LLM)-based Collective Intelligence (CI) presents a promising approach to overcoming the data wall and continuously boosting the capabilities of LLM agents. However, there is currently no dedicated arena for evolving and benchmarking LLM-based CI. To address this gap, we introduce OpenHospital, an interactive arena where physician agents can evolve CI through interactions with patient agents. This arena employs a data-in-agent-self paradigm that rapidly enhances agent capabilities and provides robust evaluation metrics for benchmarking both medical proficiency and system efficiency. Experiments demonstrate the effectiveness of OpenHospital in both fostering and quantifying CI.
GAC: Stabilizing Asynchronous RL Training for LLMs via Gradient Alignment Control
Mar 02, 2026Asynchronous execution is essential for scaling reinforcement learning (RL) to modern large model workloads, including large language models and AI agents, but it can fundamentally alter RL optimization behavior. While prior work on asynchronous RL focuses on training throughput and distributional correction, we show that naively applying asynchrony to policy-gradient updates can induce qualitatively different training dynamics and lead to severe training instability. Through systematic empirical and theoretical analysis, we identify a key signature of this instability: asynchronous training exhibits persistently high cosine similarity between consecutive policy gradients, in contrast to the near-orthogonal updates observed under synchronized training. This stale-aligned gradient effect amplifies correlated updates and increases the risk of overshooting and divergence. Motivated by this observation, we propose GRADIENT ALIGNMENT CONTROL(GAC), a simple dynamics-aware stabilization method that regulates asynchronous RL progress along stale-aligned directions via gradient projection. We establish convergence guarantees under bounded staleness and demonstrate empirically that GAC recovers stable, on-policy training dynamics and matches synchronized baselines even at high staleness.
G-Boost: Boosting Private SLMs with General LLMs
Mar 13, 2025Due to the limited computational resources, most Large Language Models (LLMs) developers can only fine-tune Small Language Models (SLMs) on their own data. These private SLMs typically have limited effectiveness. To boost the performance of private SLMs, this paper proposes to ask general LLMs for help. The general LLMs can be APIs or larger LLMs whose inference cost the developers can afford. Specifically, we propose the G-Boost framework where a private SLM adaptively performs collaborative inference with a general LLM under the guide of process reward. Experiments demonstrate that our framework can significantly boost the performance of private SLMs.
Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation
Sep 15, 2021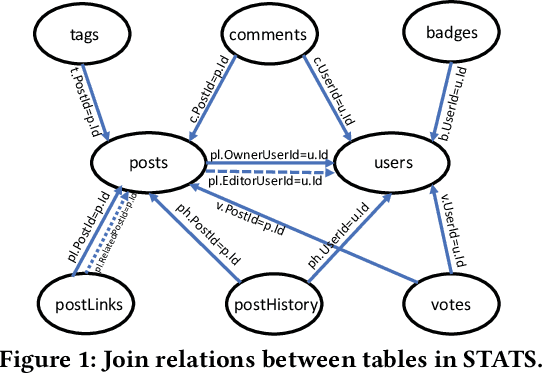
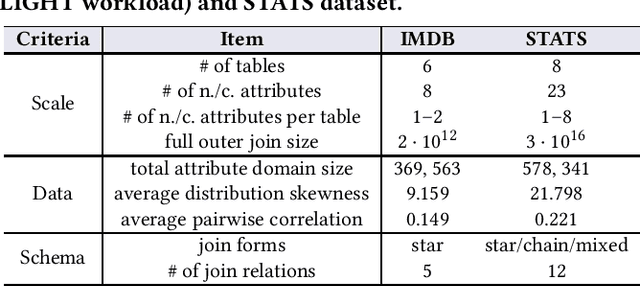
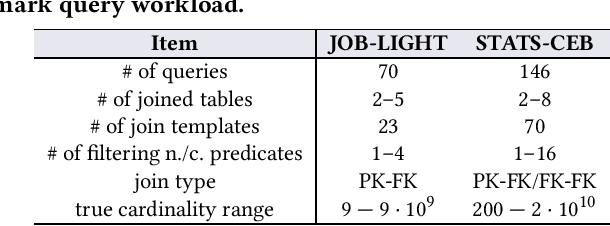
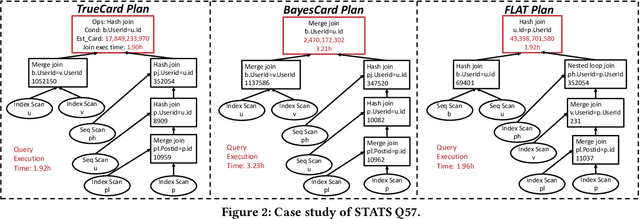
Cardinality estimation (CardEst) plays a significant role in generating high-quality query plans for a query optimizer in DBMS. In the last decade, an increasing number of advanced CardEst methods (especially ML-based) have been proposed with outstanding estimation accuracy and inference latency. However, there exists no study that systematically evaluates the quality of these methods and answer the fundamental problem: to what extent can these methods improve the performance of query optimizer in real-world settings, which is the ultimate goal of a CardEst method. In this paper, we comprehensively and systematically compare the effectiveness of CardEst methods in a real DBMS. We establish a new benchmark for CardEst, which contains a new complex real-world dataset STATS and a diverse query workload STATS-CEB. We integrate multiple most representative CardEst methods into an open-source database system PostgreSQL, and comprehensively evaluate their true effectiveness in improving query plan quality, and other important aspects affecting their applicability, ranging from inference latency, model size, and training time, to update efficiency and accuracy. We obtain a number of key findings for the CardEst methods, under different data and query settings. Furthermore, we find that the widely used estimation accuracy metric(Q-Error) cannot distinguish the importance of different sub-plan queries during query optimization and thus cannot truly reflect the query plan quality generated by CardEst methods. Therefore, we propose a new metric P-Error to evaluate the performance of CardEst methods, which overcomes the limitation of Q-Error and is able to reflect the overall end-to-end performance of CardEst methods. We have made all of the benchmark data and evaluation code publicly available at https://github.com/Nathaniel-Han/End-to-End-CardEst-Benchmark.
FSPN: A New Class of Probabilistic Graphical Model
Nov 20, 2020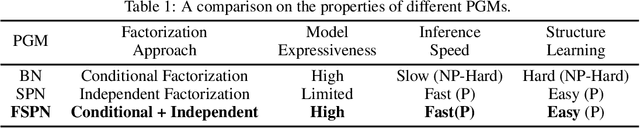
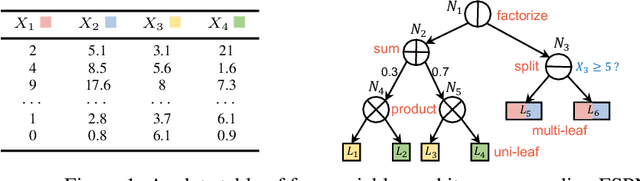
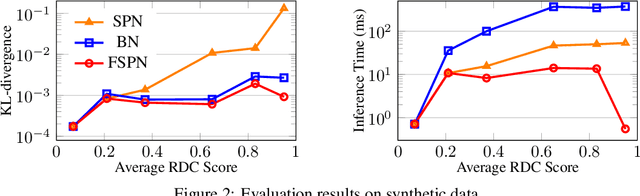
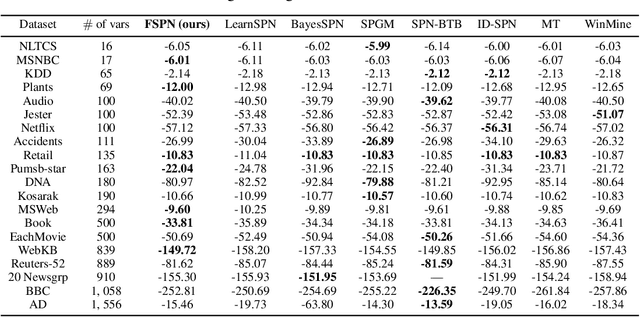
We introduce factorize sum split product networks (FSPNs), a new class of probabilistic graphical models (PGMs). FSPNs are designed to overcome the drawbacks of existing PGMs in terms of estimation accuracy and inference efficiency. Specifically, Bayesian networks (BNs) have low inference speed and performance of tree structured sum product networks(SPNs) significantly degrades in presence of highly correlated variables. FSPNs absorb their advantages by adaptively modeling the joint distribution of variables according to their dependence degree, so that one can simultaneously attain the two desirable goals: high estimation accuracy and fast inference speed. We present efficient probability inference and structure learning algorithms for FSPNs, along with a theoretical analysis and extensive evaluation evidence. Our experimental results on synthetic and benchmark datasets indicate the superiority of FSPN over other PGMs.
FLAT: Fast, Lightweight and Accurate Method for Cardinality Estimation
Nov 18, 2020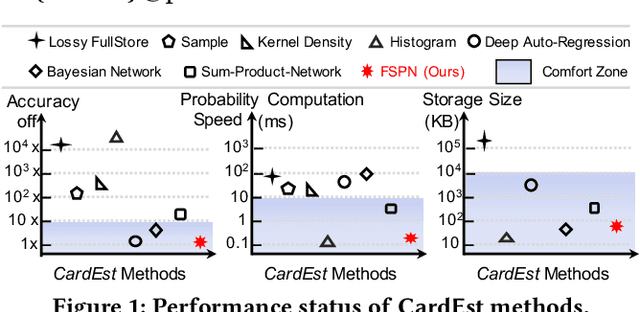
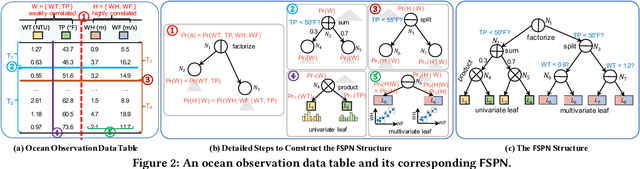
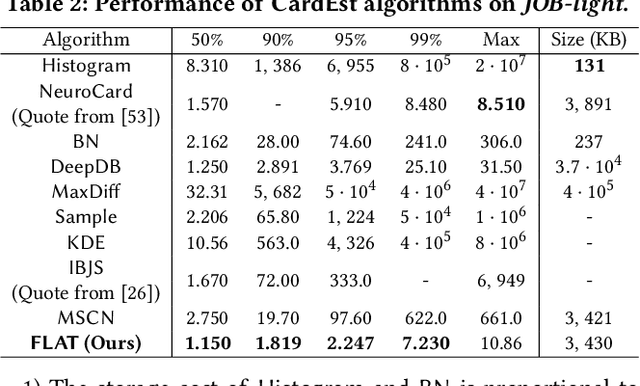

Query optimizers rely on accurate cardinality estimation (CardEst) to produce good execution plans. The core problem of CardEst is how to model the rich joint distribution of attributes in an accurate and compact manner. Despite decades of research, existing methods either over simplify the models only using independent factorization which leads to inaccurate estimates and sub optimal query plans, or over-complicate them by lossless conditional factorization without any independent assumption which results in slow probability computation. In this paper, we propose FLAT, a CardEst method that is simultaneously fast in probability computation, lightweight in model size and accurate in estimation quality. The key idea of FLAT is a novel unsupervised graphical model, called FSPN. It utilizes both independent and conditional factorization to adaptively model different levels of attributes correlations, and thus subsumes all existing CardEst models and dovetails their advantages. FLAT supports efficient online probability computation in near liner time on the underlying FSPN model, and provides effective offline model construction. It can estimate cardinality for both single table queries and multi-table join queries. Extensive experimental study demonstrates the superiority of FLAT over existing CardEst methods on well-known benchmarks: FLAT achieves 1 to 5 orders of magnitude better accuracy, 1 to 3 orders of magnitude faster probability computation speed (around 0.2ms) and 1 to 2 orders of magnitude lower storage cost (only tens of KB).
Taming the Expressiveness and Programmability of Graph Analytical Queries
Apr 20, 2020

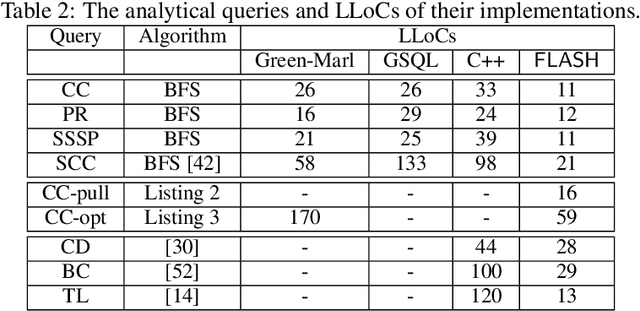
Graph database has enjoyed a boom in the last decade, and graph queries accordingly gain a lot of attentions from both the academia and industry. We focus on analytical queries in this paper. While analyzing existing domain-specific languages (DSLs) for analytical queries regarding the perspectives of completeness, expressiveness and programmability, we find out that none of existing work has achieved a satisfactory coverage of these perspectives. Motivated by this, we propose the \flash DSL, which is named after the three primitive operators Filter, LocAl and PuSH. We prove that \flash is Turing complete (completeness), and show that it achieves both good expressiveness and programmability for analytical queries. We provide an implementation of \flash based on code generation, and compare it with native C++ codes and existing DSL using representative queries. The experiment results demonstrate \flash's expressiveness, and its capability of programming complex algorithms that achieve satisfactory runtime.