 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted Sampling for Masked Language Modeling
Feb 28, 2023
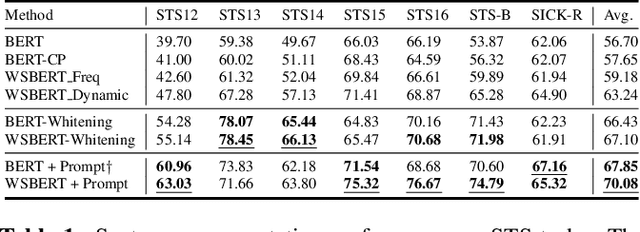
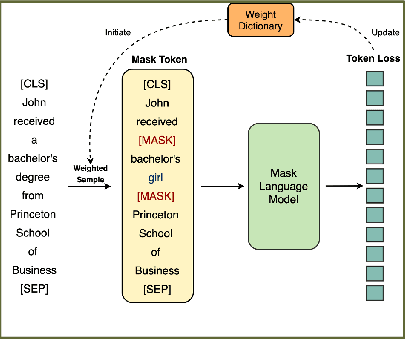
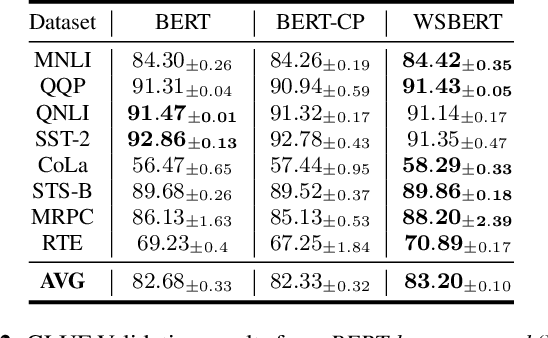
Masked Language Modeling (MLM) is widely used to pretrain language models. The standard random masking strategy in MLM causes the pre-trained language models (PLMs) to be biased toward high-frequency tokens. Representation learning of rare tokens is poor and PLMs have limited performance on downstream tasks. To alleviate this frequency bias issue, we propose two simple and effective Weighted Sampling strategies for masking tokens based on the token frequency and training loss. We apply these two strategies to BERT and obtain Weighted-Sampled BERT (WSBERT). Experiments on the Semantic Textual Similarity benchmark (STS) show that WSBERT significantly improves sentence embeddings over BERT. Combining WSBERT with calibration methods and prompt learning further improves sentence embeddings. We also investigate fine-tuning WSBERT on the GLUE benchmark and show that Weighted Sampling also improves the transfer learning capability of the backbone PLM. We further analyze and provide insights into how WSBERT improves token embeddings.
* 6 pages, 2 figures
Taming the Expressiveness and Programmability of Graph Analytical Queries
Apr 20, 2020

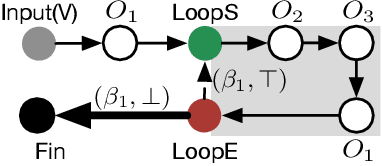
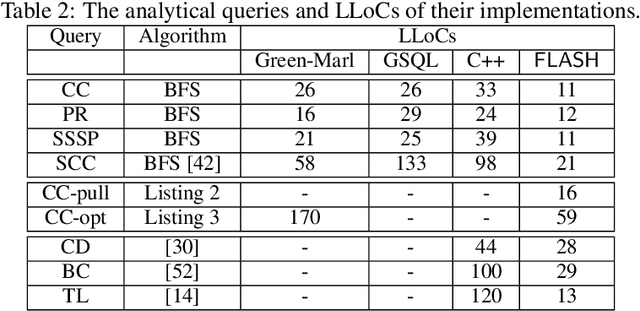
Graph database has enjoyed a boom in the last decade, and graph queries accordingly gain a lot of attentions from both the academia and industry. We focus on analytical queries in this paper. While analyzing existing domain-specific languages (DSLs) for analytical queries regarding the perspectives of completeness, expressiveness and programmability, we find out that none of existing work has achieved a satisfactory coverage of these perspectives. Motivated by this, we propose the \flash DSL, which is named after the three primitive operators Filter, LocAl and PuSH. We prove that \flash is Turing complete (completeness), and show that it achieves both good expressiveness and programmability for analytical queries. We provide an implementation of \flash based on code generation, and compare it with native C++ codes and existing DSL using representative queries. The experiment results demonstrate \flash's expressiveness, and its capability of programming complex algorithms that achieve satisfactory runtime.