 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Theory of Generalization in Selectivity Learning
Sep 11, 2024



Query-driven machine learning models have emerged as a promising estimation technique for query selectivities. Yet, surprisingly little is known about the efficacy of these techniques from a theoretical perspective, as there exist substantial gaps between practical solutions and state-of-the-art (SOTA) theory based on the Probably Approximately Correct (PAC) learning framework. In this paper, we aim to bridge the gaps between theory and practice. First, we demonstrate that selectivity predictors induced by signed measures are learnable, which relaxes the reliance on probability measures in SOTA theory. More importantly, beyond the PAC learning framework (which only allows us to characterize how the model behaves when both training and test workloads are drawn from the same distribution), we establish, under mild assumptions, that selectivity predictors from this class exhibit favorable out-of-distribution (OOD) generalization error bounds. These theoretical advances provide us with a better understanding of both the in-distribution and OOD generalization capabilities of query-driven selectivity learning, and facilitate the design of two general strategies to improve OOD generalization for existing query-driven selectivity models. We empirically verify that our techniques help query-driven selectivity models generalize significantly better to OOD queries both in terms of prediction accuracy and query latency performance, while maintaining their superior in-distribution generalization performance.
Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation
Sep 15, 2021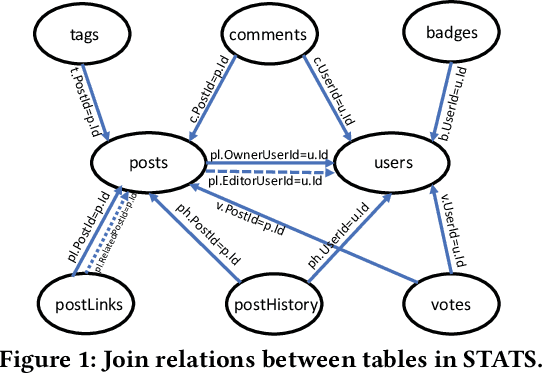
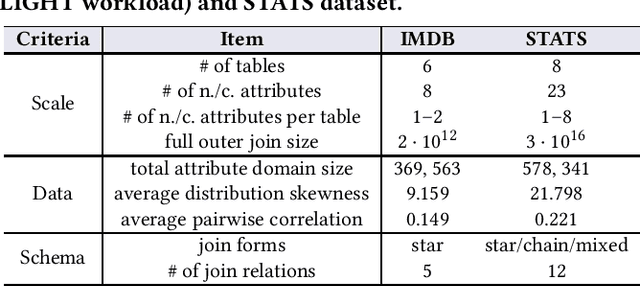
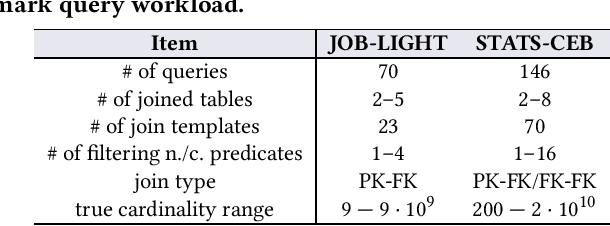
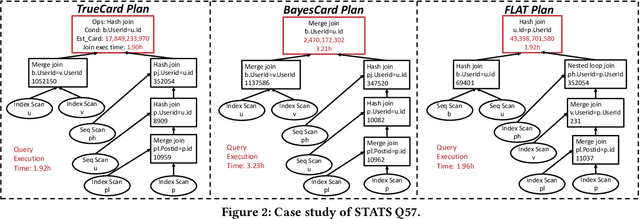
Cardinality estimation (CardEst) plays a significant role in generating high-quality query plans for a query optimizer in DBMS. In the last decade, an increasing number of advanced CardEst methods (especially ML-based) have been proposed with outstanding estimation accuracy and inference latency. However, there exists no study that systematically evaluates the quality of these methods and answer the fundamental problem: to what extent can these methods improve the performance of query optimizer in real-world settings, which is the ultimate goal of a CardEst method. In this paper, we comprehensively and systematically compare the effectiveness of CardEst methods in a real DBMS. We establish a new benchmark for CardEst, which contains a new complex real-world dataset STATS and a diverse query workload STATS-CEB. We integrate multiple most representative CardEst methods into an open-source database system PostgreSQL, and comprehensively evaluate their true effectiveness in improving query plan quality, and other important aspects affecting their applicability, ranging from inference latency, model size, and training time, to update efficiency and accuracy. We obtain a number of key findings for the CardEst methods, under different data and query settings. Furthermore, we find that the widely used estimation accuracy metric(Q-Error) cannot distinguish the importance of different sub-plan queries during query optimization and thus cannot truly reflect the query plan quality generated by CardEst methods. Therefore, we propose a new metric P-Error to evaluate the performance of CardEst methods, which overcomes the limitation of Q-Error and is able to reflect the overall end-to-end performance of CardEst methods. We have made all of the benchmark data and evaluation code publicly available at https://github.com/Nathaniel-Han/End-to-End-CardEst-Benchmark.
A Unified Deep Model of Learning from both Data and Queries for Cardinality Estimation
Jul 26, 2021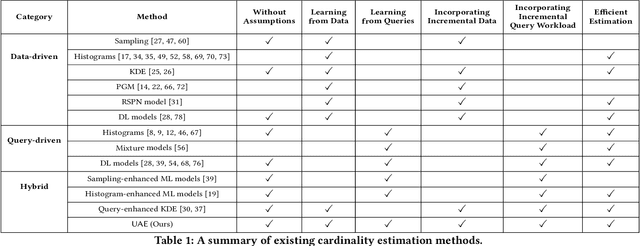
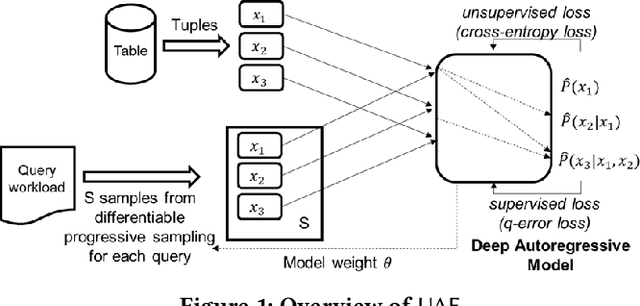
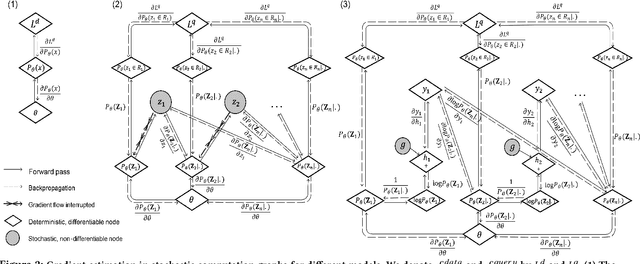
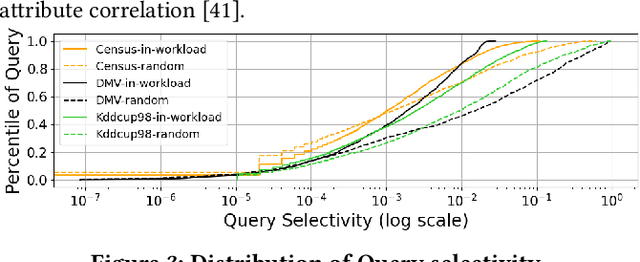
Cardinality estimation is a fundamental problem in database systems. To capture the rich joint data distributions of a relational table, most of the existing work either uses data as unsupervised information or uses query workload as supervised information. Very little work has been done to use both types of information, and cannot fully make use of both types of information to learn the joint data distribution. In this work, we aim to close the gap between data-driven and query-driven methods by proposing a new unified deep autoregressive model, UAE, that learns the joint data distribution from both the data and query workload. First, to enable using the supervised query information in the deep autoregressive model, we develop differentiable progressive sampling using the Gumbel-Softmax trick. Second, UAE is able to utilize both types of information to learn the joint data distribution in a single model. Comprehensive experimental results demonstrate that UAE achieves single-digit multiplicative error at tail, better accuracies over state-of-the-art methods, and is both space and time efficient.