 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Rank Learning for Offline Query Optimization
Apr 08, 2025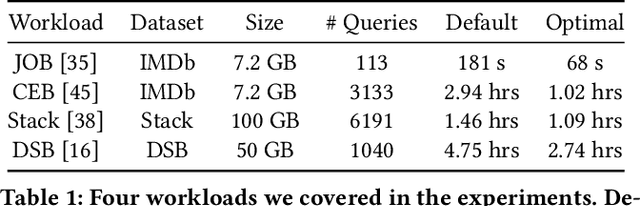
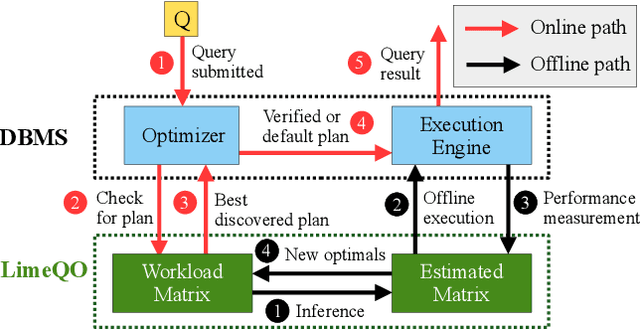
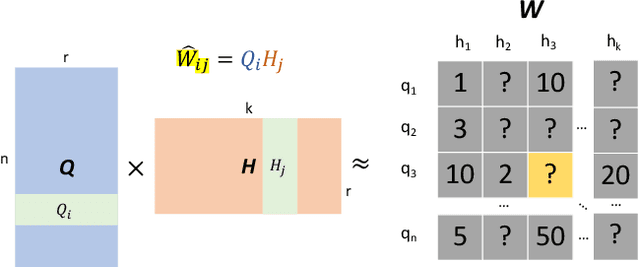
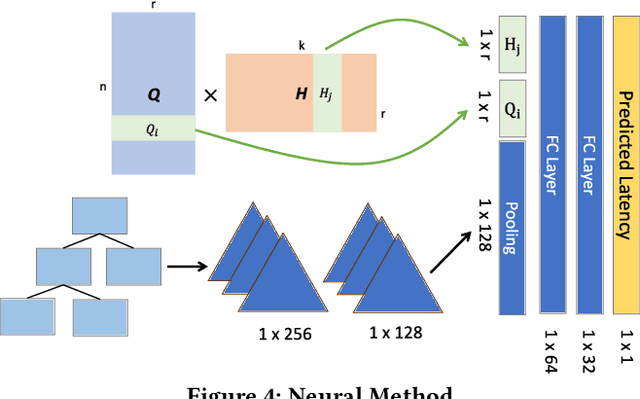
Recent deployments of learned query optimizers use expensive neural networks and ad-hoc search policies. To address these issues, we introduce \textsc{LimeQO}, a framework for offline query optimization leveraging low-rank learning to efficiently explore alternative query plans with minimal resource usage. By modeling the workload as a partially observed, low-rank matrix, we predict unobserved query plan latencies using purely linear methods, significantly reducing computational overhead compared to neural networks. We formalize offline exploration as an active learning problem, and present simple heuristics that reduces a 3-hour workload to 1.5 hours after just 1.5 hours of exploration. Additionally, we propose a transductive Tree Convolutional Neural Network (TCNN) that, despite higher computational costs, achieves the same workload reduction with only 0.5 hours of exploration. Unlike previous approaches that place expensive neural networks directly in the query processing ``hot'' path, our approach offers a low-overhead solution and a no-regressions guarantee, all without making assumptions about the underlying DBMS. The code is available in \href{https://github.com/zixy17/LimeQO}{https://github.com/zixy17/LimeQO}.
A Practical Theory of Generalization in Selectivity Learning
Sep 11, 2024



Query-driven machine learning models have emerged as a promising estimation technique for query selectivities. Yet, surprisingly little is known about the efficacy of these techniques from a theoretical perspective, as there exist substantial gaps between practical solutions and state-of-the-art (SOTA) theory based on the Probably Approximately Correct (PAC) learning framework. In this paper, we aim to bridge the gaps between theory and practice. First, we demonstrate that selectivity predictors induced by signed measures are learnable, which relaxes the reliance on probability measures in SOTA theory. More importantly, beyond the PAC learning framework (which only allows us to characterize how the model behaves when both training and test workloads are drawn from the same distribution), we establish, under mild assumptions, that selectivity predictors from this class exhibit favorable out-of-distribution (OOD) generalization error bounds. These theoretical advances provide us with a better understanding of both the in-distribution and OOD generalization capabilities of query-driven selectivity learning, and facilitate the design of two general strategies to improve OOD generalization for existing query-driven selectivity models. We empirically verify that our techniques help query-driven selectivity models generalize significantly better to OOD queries both in terms of prediction accuracy and query latency performance, while maintaining their superior in-distribution generalization performance.