 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Rank Learning for Offline Query Optimization
Apr 08, 2025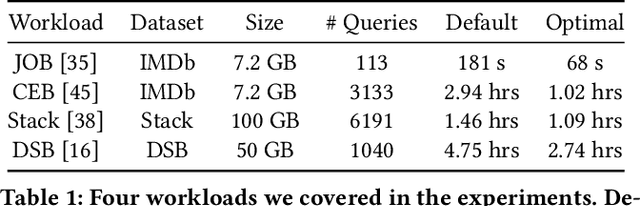
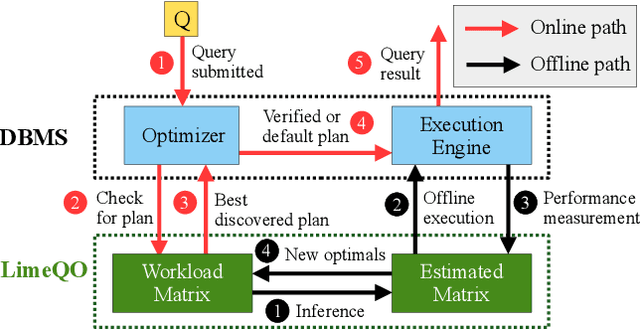
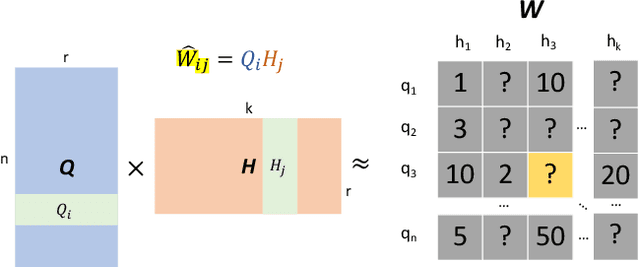
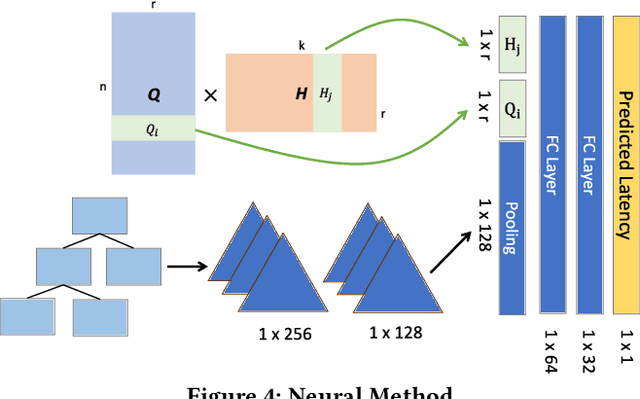
Recent deployments of learned query optimizers use expensive neural networks and ad-hoc search policies. To address these issues, we introduce \textsc{LimeQO}, a framework for offline query optimization leveraging low-rank learning to efficiently explore alternative query plans with minimal resource usage. By modeling the workload as a partially observed, low-rank matrix, we predict unobserved query plan latencies using purely linear methods, significantly reducing computational overhead compared to neural networks. We formalize offline exploration as an active learning problem, and present simple heuristics that reduces a 3-hour workload to 1.5 hours after just 1.5 hours of exploration. Additionally, we propose a transductive Tree Convolutional Neural Network (TCNN) that, despite higher computational costs, achieves the same workload reduction with only 0.5 hours of exploration. Unlike previous approaches that place expensive neural networks directly in the query processing ``hot'' path, our approach offers a low-overhead solution and a no-regressions guarantee, all without making assumptions about the underlying DBMS. The code is available in \href{https://github.com/zixy17/LimeQO}{https://github.com/zixy17/LimeQO}.
The Unreasonable Effectiveness of LLMs for Query Optimization
Nov 05, 2024
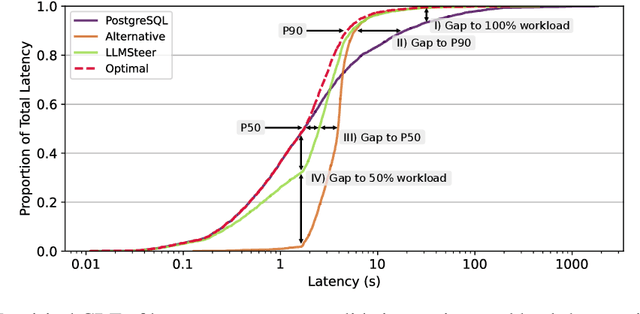
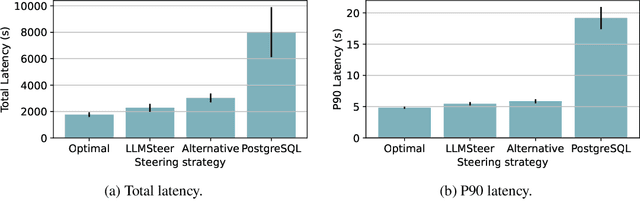
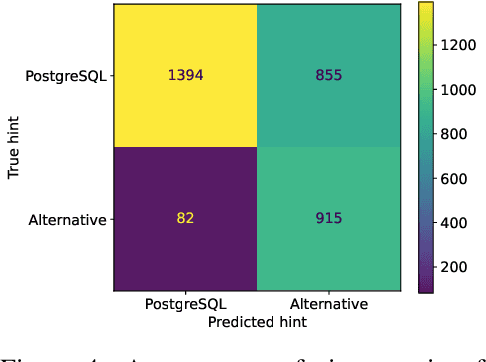
Recent work in database query optimization has used complex machine learning strategies, such as customized reinforcement learning schemes. Surprisingly, we show that LLM embeddings of query text contain useful semantic information for query optimization. Specifically, we show that a simple binary classifier deciding between alternative query plans, trained only on a small number of labeled embedded query vectors, can outperform existing heuristic systems. Although we only present some preliminary results, an LLM-powered query optimizer could provide significant benefits, both in terms of performance and simplicity.
A Unified Graph Transformer for Overcoming Isolations in Multi-modal Recommendation
Jul 29, 2024With the rapid development of online multimedia services, especially in e-commerce platforms, there is a pressing need for personalised recommendation systems that can effectively encode the diverse multi-modal content associated with each item. However, we argue that existing multi-modal recommender systems typically use isolated processes for both feature extraction and modality modelling. Such isolated processes can harm the recommendation performance. Firstly, an isolated extraction process underestimates the importance of effective feature extraction in multi-modal recommendations, potentially incorporating non-relevant information, which is harmful to item representations. Second, an isolated modality modelling process produces disjointed embeddings for item modalities due to the individual processing of each modality, which leads to a suboptimal fusion of user/item representations for effective user preferences prediction. We hypothesise that the use of a unified model for addressing both aforementioned isolated processes will enable the consistent extraction and cohesive fusion of joint multi-modal features, thereby enhancing the effectiveness of multi-modal recommender systems. In this paper, we propose a novel model, called Unified Multi-modal Graph Transformer (UGT), which firstly leverages a multi-way transformer to extract aligned multi-modal features from raw data for top-k recommendation. Subsequently, we build a unified graph neural network in our UGT model to jointly fuse the user/item representations with their corresponding multi-modal features. Using the graph transformer architecture of our UGT model, we show that the UGT model can achieve significant effectiveness gains, especially when jointly optimised with the commonly-used multi-modal recommendation losses.
A Directional Diffusion Graph Transformer for Recommendation
Apr 04, 2024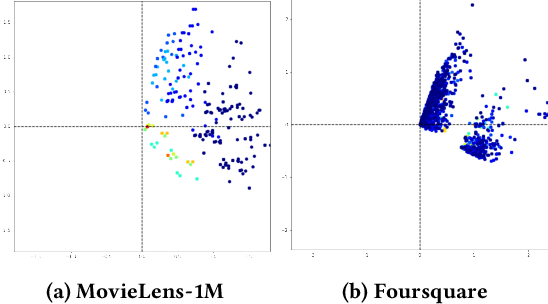

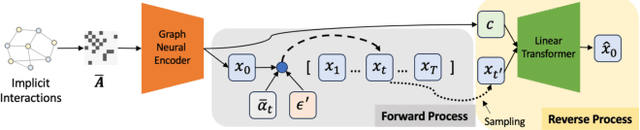
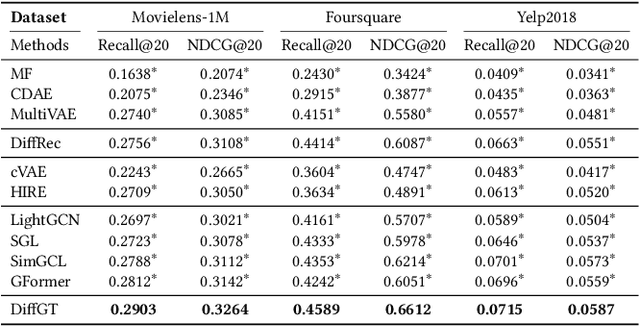
In real-world recommender systems, implicitly collected user feedback, while abundant, often includes noisy false-positive and false-negative interactions. The possible misinterpretations of the user-item interactions pose a significant challenge for traditional graph neural recommenders. These approaches aggregate the users' or items' neighbours based on implicit user-item interactions in order to accurately capture the users' profiles. To account for and model possible noise in the users' interactions in graph neural recommenders, we propose a novel Diffusion Graph Transformer (DiffGT) model for top-k recommendation. Our DiffGT model employs a diffusion process, which includes a forward phase for gradually introducing noise to implicit interactions, followed by a reverse process to iteratively refine the representations of the users' hidden preferences (i.e., a denoising process). In our proposed approach, given the inherent anisotropic structure observed in the user-item interaction graph, we specifically use anisotropic and directional Gaussian noises in the forward diffusion process. Our approach differs from the sole use of isotropic Gaussian noises in existing diffusion models. In the reverse diffusion process, to reverse the effect of noise added earlier and recover the true users' preferences, we integrate a graph transformer architecture with a linear attention module to denoise the noisy user/item embeddings in an effective and efficient manner. In addition, such a reverse diffusion process is further guided by personalised information (e.g., interacted items) to enable the accurate estimation of the users' preferences on items. Our extensive experiments conclusively demonstrate the superiority of our proposed graph diffusion model over ten existing state-of-the-art approaches across three benchmark datasets.
Large Multi-modal Encoders for Recommendation
Nov 03, 2023



In recent years, the rapid growth of online multimedia services, such as e-commerce platforms, has necessitated the development of personalised recommendation approaches that can encode diverse content about each item. Indeed, modern multi-modal recommender systems exploit diverse features obtained from raw images and item descriptions to enhance the recommendation performance. However, the existing multi-modal recommenders primarily depend on the features extracted individually from different media through pre-trained modality-specific encoders, and exhibit only shallow alignments between different modalities - limiting these systems' ability to capture the underlying relationships between the modalities. In this paper, we investigate the usage of large multi-modal encoders within the specific context of recommender systems, as these have previously demonstrated state-of-the-art effectiveness when ranking items across various domains. Specifically, we tailor two state-of-the-art multi-modal encoders (CLIP and VLMo) for recommendation tasks using a range of strategies, including the exploration of pre-trained and fine-tuned encoders, as well as the assessment of the end-to-end training of these encoders. We demonstrate that pre-trained large multi-modal encoders can generate more aligned and effective user/item representations compared to existing modality-specific encoders across three multi-modal recommendation datasets. Furthermore, we show that fine-tuning these large multi-modal encoders with recommendation datasets leads to an enhanced recommendation performance. In terms of different training paradigms, our experiments highlight the essential role of the end-to-end training of large multi-modal encoders in multi-modal recommendation systems.
Contrastive Graph Prompt-tuning for Cross-domain Recommendation
Aug 21, 2023Recommender systems are frequently challenged by the data sparsity problem. One approach to mitigate this issue is through cross-domain recommendation techniques. In a cross-domain context, sharing knowledge between domains can enhance the effectiveness in the target domain. Recent cross-domain methods have employed a pre-training approach, but we argue that these methods often result in suboptimal fine-tuning, especially with large neural models. Modern language models utilize prompts for efficient model tuning. Such prompts act as a tunable latent vector, allowing for the freezing of the main model parameters. In our research, we introduce the Personalised Graph Prompt-based Recommendation (PGPRec) framework. This leverages the advantages of prompt-tuning. Within this framework, we formulate personalized graph prompts item-wise, rooted in items that a user has previously engaged with. Specifically, we employ Contrastive Learning (CL) to produce pre-trained embeddings that offer greater generalizability in the pre-training phase, ensuring robust training during the tuning phase. Our evaluation of PGPRec in cross-domain scenarios involves comprehensive testing with the top-k recommendation tasks and a cold-start analysis. Our empirical findings, based on four Amazon Review datasets, reveal that the PGPRec framework can decrease the tuned parameters by as much as 74%, maintaining competitive performance. Remarkably, there's an 11.41% enhancement in performance against the leading baseline in cold-start situations.